

AI ナレッジベースの作り方を検索している人の多くは、同じ壁にぶつかっている。AIに調べさせるたびに成果がリセットされ、前回のリサーチと同じ検索を繰り返し、判断基準がどこにも残っていない。
料理に例えると、毎回レシピを検索して、前回うまくいった火加減のメモがどこにもない状態だ。調味料は増え続けるのに、味が安定しない。
この記事では、そのメモ帳レベルのAI ナレッジベースを「AIが繰り返し読める運用基盤」に変えた7段階の構造変化を、設計判断の理由とともに記録する。技術的な設計判断も書くが、各段階の冒頭で「何が困っていて、何を変えたか」を先に説明するので、エンジニアでなくても流れは追える。
なぜAI ナレッジベースは「メモを貯めるだけ」では足りないのか
メモアプリにリサーチ結果を貯めている人は多い。だがメモが増えるほど「どこに何を書いたか」がわからなくなり、結局また検索する——という経験はないだろうか。
AIリサーチを始めた当初の問題は3つあった。
- 調べるほど迷う — 情報は増えるが、どれが今の判断に関係するかがわからなくなる
- 毎回ゼロから調べ直す — ブログを書くたびに似た調査を繰り返していた
- AIが文脈を忘れる — 検索は得意だが、チームの基準や過去の判断を長期間保持できない
メモを増やしても、この3つは解決しなかった。問題は情報量ではなく、判断を支える構造がなかったことだ。
なぜ「メモを貯める」だけでは足りないか — 3つの問題
情報過多
調べるほど情報は増えるが、どれが今の判断に関係するかわからなくなる
繰り返し検索
記事を書くたびに似た調査をゼロから繰り返す
文脈喪失
AIは検索が得意でも、判断基準を長期間保持できない
第1段階:ファイルの集積から知識グラフへ
困っていたこと: メモがフォルダに100個あるのに、必要なときに見つからない。
変えたこと: メモ同士を「この話とあの話は関係がある」と線でつないだ。
最初の構造変更は、ファイルをフォルダに分類するのをやめて、情報同士の関係を設計することだった。
| 層 | 役割 | 例 |
|---|---|---|
| raw | 原文をそのまま保管 | 論文、記事、公式発表 |
| source | ソースごとの要約 | 要点抽出・ファクト整理 |
| concept / entity | 繰り返し登場する概念・人物 | 定義・背景・関連付け |
| synthesis | 複数の根拠を束ねた解釈 | 比較分析・構造化された見解 |
ポイントは「ソースを貯める」のではなく「ソース間の関係をAIが辿れる形で残す」ことだ。Markdownのウィキリンクで概念同士をつなぎ、AIが関連情報を芋づる式に参照できるようにした。

本棚に本を並べただけでは辞書にならないのと同じだ。索引と相互参照がなければ、ファイルがいくら増えても「探せるメモ帳」にはならない。
実際の構造を見るとこうなる。
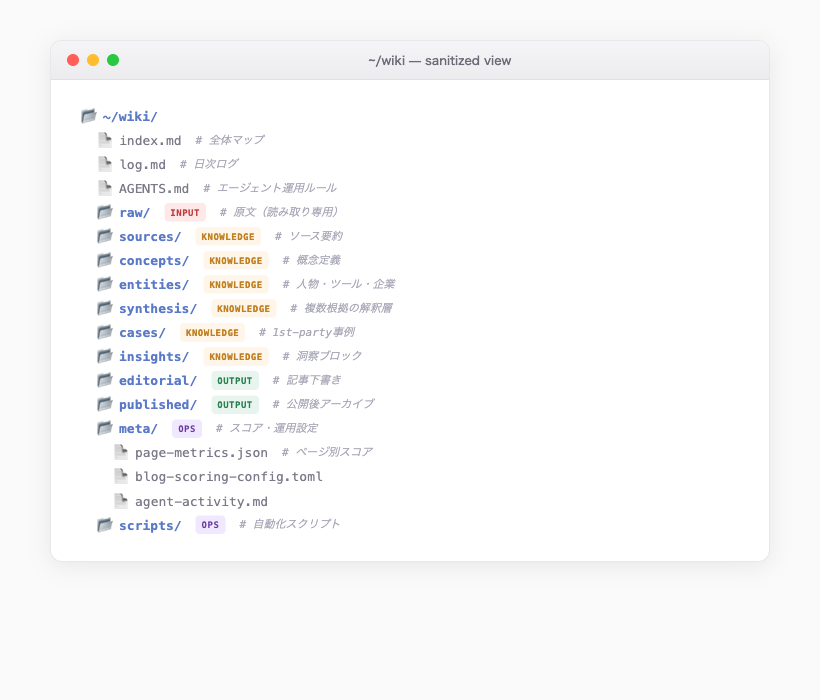
トップレベルが INPUT(raw)/ KNOWLEDGE(sources, concepts, entities, synthesis, cases, insights)/ OUTPUT(editorial, published)/ OPS(meta, scripts)の4つの役割に分かれている。フォルダ名ではなく、役割ベースで設計しているのがポイントだ。
第2段階:次に書くべきテーマを「感覚」ではなく「点数」で選ぶ
困っていたこと: ネタは50個あるのに、「次に何を書くか」で毎回迷う。
変えたこと: ネタに点数をつけて、迷う時間をゼロにした。
AI ナレッジベースが大きくなると、次のボトルネックは優先順位だった。どの情報をブログにするか、どれを保留するかを感覚で決めていると、判断がブレる。
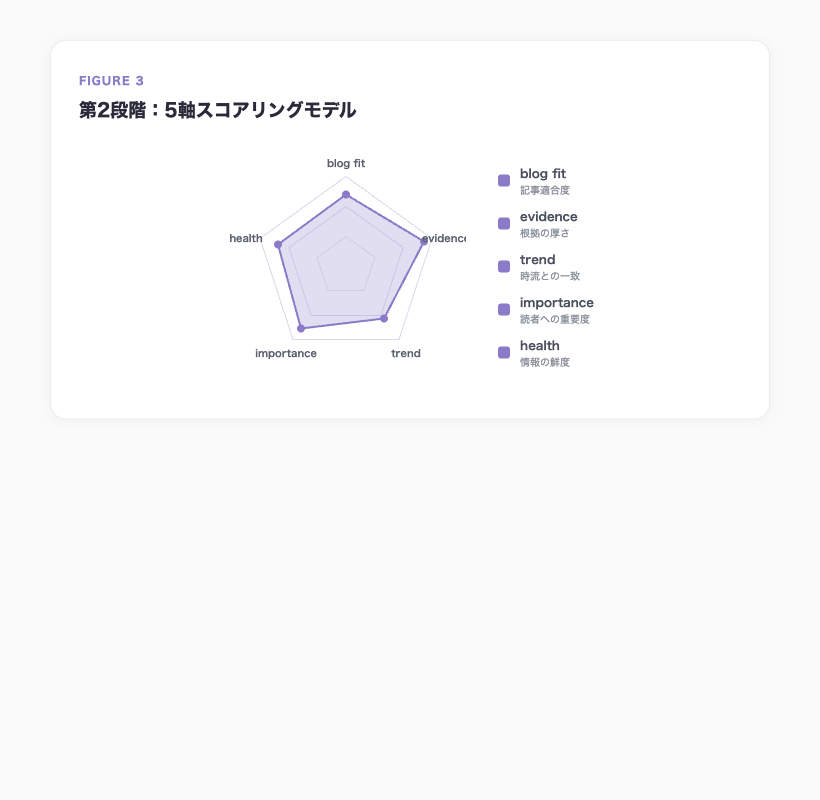
そこでスコアリングモデルを導入した。
| 評価軸 | 見ているもの |
|---|---|
| blog fit | ブログ記事としての適合度 |
| evidence | 根拠の厚さ |
| trend | 検索需要・時流との一致 |
| importance | 読者にとっての重要度 |
| maintenance health | 情報の鮮度 |
5つの軸で数値化することで、「何を今書くべきか」の議論が属人的な判断から構造的な判断に変わった。
スコアが高ければ自動的に書くわけではない。スコアは会話のきっかけだ。「なぜこのテーマのスコアが高いか」を確認してから着手するルールにした。
第3段階:「情報をまとめた記事」と「視点を変える記事」の設計を分ける
困っていたこと: 「おもしろい意見」だけの記事と「ただの情報整理」の記事、どちらかに偏る。
変えたこと: 1本の記事の中に「事実・兆候・意見」の3つの箱を作り、どれかが空なら公開しないルールにした。
ここが一番時間をかけた構造変更だった。
洞察を強化すると、AIが「それっぽい解釈」を量産する方向に傾く。情報性を強化すると、どこにでもある整理記事に戻る。このバランスを感覚で取ろうとすると、記事ごとに品質がバラつく。
だから感覚ではなく構造で制御することにした。
- fact — 検証可能な事実
- signal — 傾向を示す兆候
- thesis — 自分たちの解釈・主張

毎週月曜日、AIトレンドニュースレター配信中
会員登録すると、毎週月曜日に「今週のAI・バイブコーディング最新情報」をお届けします。
バナー広告なし・本当に役立つ情報だけを厳選するクリーンなAI専門メディアです。
この3つを記事の中で意識的に分けて書くようにした。さらに記事全体の方向性を2つのレーンに分類した。
| レーン | 特徴 | 例 |
|---|---|---|
| 速報型 | 事実の早さが価値 | ツール発表、公式アップデート |
| 深掘り型 | 解釈の深さが価値 | 設計思想、運用事例、比較分析 |
加えて、記事の出口にもチェックを入れた。「洞察は入っているか、だが情報が空になっていないか」を公開前に確認する仕組みだ。
一番もったいない失敗パターンは「良い解釈はあるのに、読んだ後に持ち帰れる情報がない記事」だった。読者が時間を使って読んだのに、得られたのが曖昧な見解だけ——これを構造的に防ぐのが、fact・signal・thesis分離の目的だ。
実際に救われた失敗パターンを2つ挙げる。
1つ目は「未来予測だけで終わる記事」。AIに最新動向を要約させると、「今後はこの方向に進むだろう」という抽象的な結論が並ぶ。読者は「で、今の数字は?根拠は?」が知りたいのに、それが書かれていない。fact欄が空のままthesisだけ膨らんだ状態だ。出口チェックでこれを止める。
2つ目は「事実の羅列だけの記事」。逆に、ニュースや公式発表をそのまま並べるだけで、「だから何?」の解釈がない記事もある。これはthesis欄が空の状態だ。情報量はあるのに、読者が記事を閉じた後に「この記事を読んで何が変わったか」を思い出せない。これも出口チェックで止める。
この2つを止めるだけで、記事の合格ラインが明確になった。
第4段階:AIが書いた「もっともらしい文章」から抜け出す
困っていたこと: 文章は上手いのに「この人が使ったことあるな」と読者に思ってもらえない。
変えたこと: 自分たちが試した記録(成功も失敗も)をAI ナレッジベースに貯める仕組みを作った。
洞察型の構造を入れてから、また別の壁が見えた。AIは流暢に書くが、「書いた人が試したことがある」ようには読めない。ソースの要約とsynthesisだけでは、文章が賢く見えても、読み手が信頼を寄せるだけの重みが足りなかった。
ここで導入したのが、ファーストパーティ・エビデンスの仕組みだ。
- 自分たちが試した作業ログ
- before / afterの記録
- 失敗した選択肢とその理由
- 代表的なスクリーンショット
この設計で一番難しかったのは、保存場所の問題ではなかった。どこまで公開可能で、どこから先が内部情報かを同時に設計する必要があった点だ。
作業ログにはアカウント情報、内部KPI、非公開のツール設定が混ざる。そのまま蓄積すると公開できないし、全部削ると証拠としての価値が消える。だから「そのまま公開」「加工して公開」「メタデータだけ残す」の3段階に分けて、エビデンスごとに開示レベルを設定するようにした。
公開3段階の判別は、こんなイメージだ。

| 開示レベル | 例 | 公開できる範囲 |
|---|---|---|
| そのまま公開 | 公式ツールの設定画面、外部記事のキャプチャ | 全部 |
| 加工して公開 | 自分たちの作業ログ、before/after比較 | 個人情報・KPI・絶対パスをマスク |
| メタデータのみ | 内部の試作品、未公開のスポンサー商談 | 「やった」事実と「学び」だけ |
このルールのおかげで、エビデンスを集めるたびに「これは公開できるか?」で迷うことがなくなった。最初から開示レベルを決めて保存するから、後から記事を書くときに「この素材は使えるか?」を考え直さなくていい。
手間はかかるが、この構造があることで記事の引用元が外部ソースだけでなく、自分たちの運用記録になった。「どのAIでも書ける記事」と「この人たちが試したから書けた記事」の差は、ここで生まれる。
第5段階:図表を「装飾」ではなく「証拠」として扱う
困っていたこと: 図をたくさん貼ったのに、何を証明したい図なのかが読者に伝わらない。
変えたこと: 1つの図に1つの主張を紐づけ、「この図は何を言っているか」を必ず明記するルールにした。
テキストだけでは説明が足りない領域が出てきた。インフラ比較、市場動向、構造図。だが図表はすぐ古くなるし、スクリーンショットは文脈なしに貼ると誤解を生む。
そこで図表管理のルールを作った。
- 1図表 = 1主張 — 図表が何を証明しているか明示する
- 役割分類 — proof(証拠)/ context(文脈説明)/ workflow(手順図示)
- 現在値チャートと構造図を分離 — 古くなるデータと、古くならない概念図を区別する
「図表を多く入れる」ことが品質ではない。図表がどの主張を支えているかが明示されていることが品質だ。
第6段階:最新データは「保存」ではなく「再取得手順」で管理する
困っていたこと: 先月保存した「最新ランキング」が、今月にはもう古い。
変えたこと: 数字そのものを保存するのをやめて、「その数字をどこで取り直せるか」を保存するようにした。
ここは予想以上に厄介だった。
AI ナレッジベースの強みは知識を蓄積できることだが、チャートや数値データに関しては、その強みがそのまま弱点になる。先月正確だったランキング表が、今月には古い情報源に変わっている。AI ナレッジベースに数字を長期保存すると、むしろ誤情報を自分で量産する仕組みになってしまう。
ここで哲学を変えた。チャートを保存するのをやめて、チャートを再取得する手順を保存することにした。
| 保存するもの | 保存しないもの |
|---|---|
| データの取得元(公式URL等) | データの値そのもの |
| 更新頻度の目安 | 「最新の数字」 |
| 再取得手順 | 古くなるランキング表 |
さらに、図表を2種類に分けた。
- 現在値チャート(ランキング、価格、ベンチマーク) → 保存せず再取得
- 構造・メカニズム図(アーキテクチャ図、概念図) → 保存してよい(古くならない)
この区分が入ってから、「この図はまだ正しいか?」という確認が格段に楽になった。現在値チャートは再取得手順を実行するだけでいい。構造図は構造そのものが変わらない限り有効だ。
最新性は蓄積の対象ではなく、検証手順の対象だ。
「この図は保存していいか?再取得すべきか?」を判別するために、自分たちはこの2つの質問を使っている。
- 6ヶ月後にこの図を見て、まだ正しいと言えるか? — 言えるなら保存してよい。言えないなら再取得手順を保存する側に分類する。
- この図は数値そのものか、それとも仕組みか? — 数値ならstale、仕組みならpermanent。
シンプルだが、この2つの質問だけで図表の管理コストが大きく減った。「なんとなく古そう」という曖昧な感覚で図を貼り替える作業がなくなり、再取得すべき図だけを定期的に更新する運用に切り替わった。
第7段階:1カテゴリの整備から全AI ナレッジベースの運用基盤へ
困っていたこと: AI関連は整備されたのに、デザインやコンテンツ戦略は元のメモ帳のまま。
変えたこと: うまくいった構造を他のテーマにも複製した。
最初は1つのテーマ(AIツーリング)だけが整備されていた。だが運用を続けるうちに、デザイン、コンテンツ戦略、ブログ運営にも同じレベルの構造が必要になった。
ドメイン別のエビデンスパックを作った。
- AIツーリング — ツール比較・ベンチマーク・運用事例
- デザイン/仕様 — DESIGN.md・Anti-AI UI・スペックレビュー
- コンテンツ成長 — 読者分析・記事パフォーマンス・チャネル最適化
良いAI ナレッジベースは1つのテーマだけが整備された場所ではなく、判断パターンが複数の分野に再現される場所だ。
実際のsynthesisページの一例を見せる。

フロントマター(type、confidence、tags、related)でメタ情報を持ち、本文中の [[wikilink]] で他のページに繋がっている。AIエージェントはこの構造をたどって、関連する判断基準を毎回読み込む。これが「AIが読む運用OS」の実体だ。
7段階の構造進化タイムライン
1
知識グラフ化
2
スコアリング
3
fact/signal/thesis分離
4
1stパーティ証拠
5
図表=証拠
6
再取得プロトコル
7
全ドメイン展開
この7段階を経て、実際に何が変わったか
ここまで構造の話をしてきたが、運用結果としても変化があった。
before(メモ帳時代):
- ブログ記事1本のために、毎回ゼロから情報収集していた
- 「次に何を書くか」で毎週迷っていた
- AIに調べさせても、3日後には文脈をすべて忘れていた
- 図表は貼ったまま、半年後に見ると古くなっていた
- 内部の試行錯誤は記憶の中にしかなかった
after(運用基盤化後):
- 1本の記事に必要な情報の70%は、すでにAI ナレッジベース内にある
- 次に書くべきテーマはスコアで自動的に並ぶ
- AIは毎回ナレッジベースを読み直して、過去の判断基準を引き継ぐ
- 図表は「保存してよいもの」と「再取得すべきもの」に分かれている
- 試行錯誤は記録され、次の判断に再利用される
数字で言えば、1本の記事を書くのに必要だった調査時間がおよそ半分以下になった。だが本当に変わったのは時間ではない。「同じ判断ミスを繰り返さなくなった」ことだ。
AI ナレッジベースが運用基盤になるというのは、単に情報が整理されることではない。過去の自分の判断を、未来の自分とAIが引き継げる状態を作ることだ。
次に予想しているボトルネック
それでも、まだ完成していない。今見えている次のボトルネックは3つある。
- クロスドメインの参照 — AIツーリングのナレッジとデザインのナレッジを横断する記事を書くとき、両方の文脈を同時に保ちにくい
- 古いsynthesisの再評価 — 半年前に書いた解釈が今も正しいか、自動でフラグが立つ仕組みがない
- 読者からのフィードバック取り込み — 公開後の反応をナレッジベースに戻す経路がまだ細い
これらが見えてきたから、また次の構造変更が始まる。AI ナレッジベースは作り終わるものではなく、ボトルネックが見えるたびに育てるものだ。
今のAI ナレッジベースが採用している7つの原則
7段階の構造進化を経て、今の設計原則は以下の通りだ。
- AI ナレッジベースはメモ帳ではなく、AIが読む運用OSである
- ソースの蓄積より、判断規則の蓄積が重要な場面がある
- 良い記事は情報量ではなく、判断構造と解釈フレームで差がつく
- 洞察とファクトは分離する
- 実際の事例と作業証拠がなければ信頼は浅い
- 図表は装飾ではなくエビデンスである
- 最新性は保存ではなくライブ検証で管理する
今日やること
AI ナレッジベースを始めるためにやるべきことは、たった3つだ。
- 自分のリサーチ用メモを1つ選ぶ
- そのメモが「ソース」「概念」「解釈」のどれに当たるかを分類する
- 分類できたら、Markdownファイルに
type:フロントマターを付けて保存する
15分で始められる。構造は後から育てればいい。
関連記事:ハーネスエンジニアリング完全ガイド / OpenAI Codexのチーム導入
AI ナレッジベース に関するよくある質問
Q. Notionやobsidianでも同じAI ナレッジベース構造は作れますか?
A. 作れます。重要なのはツールではなく、情報を「ソース → 概念 → 解釈」の層に分けて接続する設計思想です。ツールは好みで選んで構いません。
Q. AI ナレッジベースは何ページくらいから効果が出ますか?
A. 10〜15ページで接続構造の恩恵が見え始めます。50ページを超えるとスコアリングが必要になります。最初から全部揃える必要はありません。
Q. AIエージェント(Codex、Claude Code等)との併用はどうしますか?
A. 一方がリサーチして知識を増やし、もう一方がそれを参照して記事や分析を作るという役割分担が効果的です。AI ナレッジベースが2つのエージェントの共有メモリになります。
Q. 個人でも使えますか、チーム向けですか?
A. 個人で始めて、構造ができたらチームに展開するのが自然です。1人で運用する場合でも、「未来の自分」と「AIエージェント」が読者になるため、構造の価値は変わりません。
Q. 最新情報を保存しないなら、何のためのAI ナレッジベースですか?
A. 最新の数字ではなく「何をどこで再確認するか」を保存します。AI ナレッジベースの価値は、蓄積量ではなく判断と検証の手順が残っていることにあります。
この記事を書いた人: VibeCoding Tailor(@shuntailor)。AI ナレッジベース・DESIGN.md・AGENTS.md・検証ループを自社のブログ運営とプロダクト開発に組み込み、AIエージェント運用の品質管理を日常的に実践している。
ソースリスト:
- LLM Wiki 開発哲学タイムライン(2026-04-10)— 内部設計記録
- First-Party Evidence Capture System — 実証データ蓄積の設計思想
- Chart Freshness Governance — 図表鮮度管理ポリシー
- Live Chart Retrieval Protocol — リアルタイムデータ再取得手順
- Wiki Scoring Model — ページ評価スコアリング設計
- Andrej Karpathy — LLM Wiki:知識コンパイルパターン
最終更新日:2026年4月10日




