
AI ペルソナ 判断構造を理解しなければ、AIはあなたの口調を真似るだけで、本当の判断は再現できない。この記事では、判断軸・性格軸・世界観軸の3軸で人間の判断構造を記録するPERSONAシステムがなぜ必要なのか、どういう順序で生まれたのかを示す。
AIはあなたを理解したふりをしている
ChatGPTに「私みたいに話して」と頼んだことはあるだろうか。
口調はそこそこ上手く真似る。文末に「〜だよね」を付けたり、絵文字を適度に混ぜたり、敬語とタメ口を使い分ければそれっぽく見える。
だが、こんなことを頼んでみよう。「この事業提案を受けるかどうか判断して。」
途端に崩れる。あなたなら相手の利害関係を先に読むのか、まず金額を見るのか、それとも「とりあえずやってみて後で考えよう」とするのか。どこで止まり、どこで押すのか。そういった判断の順序をAIは知らない。
口調は表面だ。判断は構造だ。今のほとんどのAI personaシステムは、表面だけコピーして構造には触れない。
より正確に言えば、今のAIにできないのは「何が本当の問題なのかを定義すること」と「次に何をリクエストすべきかを選ぶこと」だ。回答は上手い。下書きも作れる。コードも書ける。しかし「今何を先にすべきか?」「この状況で何を聞くべきか?」「これは今言うべきではないのに」を判断するのは、依然として人間の役割だ。そして人によって判断の仕方が違う。
私は今この問題に直接取り組んでいる。AIが人間の判断構造を再現できるシステムを作っており、論文化できるレベルで整理している。ただしこの記事は「完成したシステムの紹介」ではない。どんな問題があって、どういう順序で構造が生まれたのかを見せる記事だ。
なぜ既存のpersonaは浅いのか
今のほとんどのAI persona設定はこんな感じだ。
「あなたは親切な20代マーケターです。絵文字をよく使い、タメ口で話してください。」
これがpersonaか? 違う。これは口調設定だ。
MBTIを入れても同じだ。「INTJだから論理的に話して」と書けば、AIは毎回「論理的に分析すると…」で始まる文章を出す。だが実際のINTJがすべての状況で論理的にだけ判断するか? しない。怒れば論理を捨てることもあるし、10年後を考えれば目先の損を受け入れることもある。
実際に一緒に働いてみると、本当の違いは「冷静だ/直球だ/戦略的だ」という描写では分からない。本当の違いはこういうところに出る。
- 情報が足りないとき、どこまで言うか
- いつ止まるか
- 失敗したとき崩れるか、回収するか
- 何を小さなミスと見て、何を絶対にダメなミスと見るか
- 同じ出来事を機会と見るか、リスクと見るか
既存personaシステムの問題を3行にまとめるとこうなる。
- 口調だけコピーして判断の順序は見ない
- 一度設定したら変わらない
- 「なぜそう判断するのか」の根拠がない
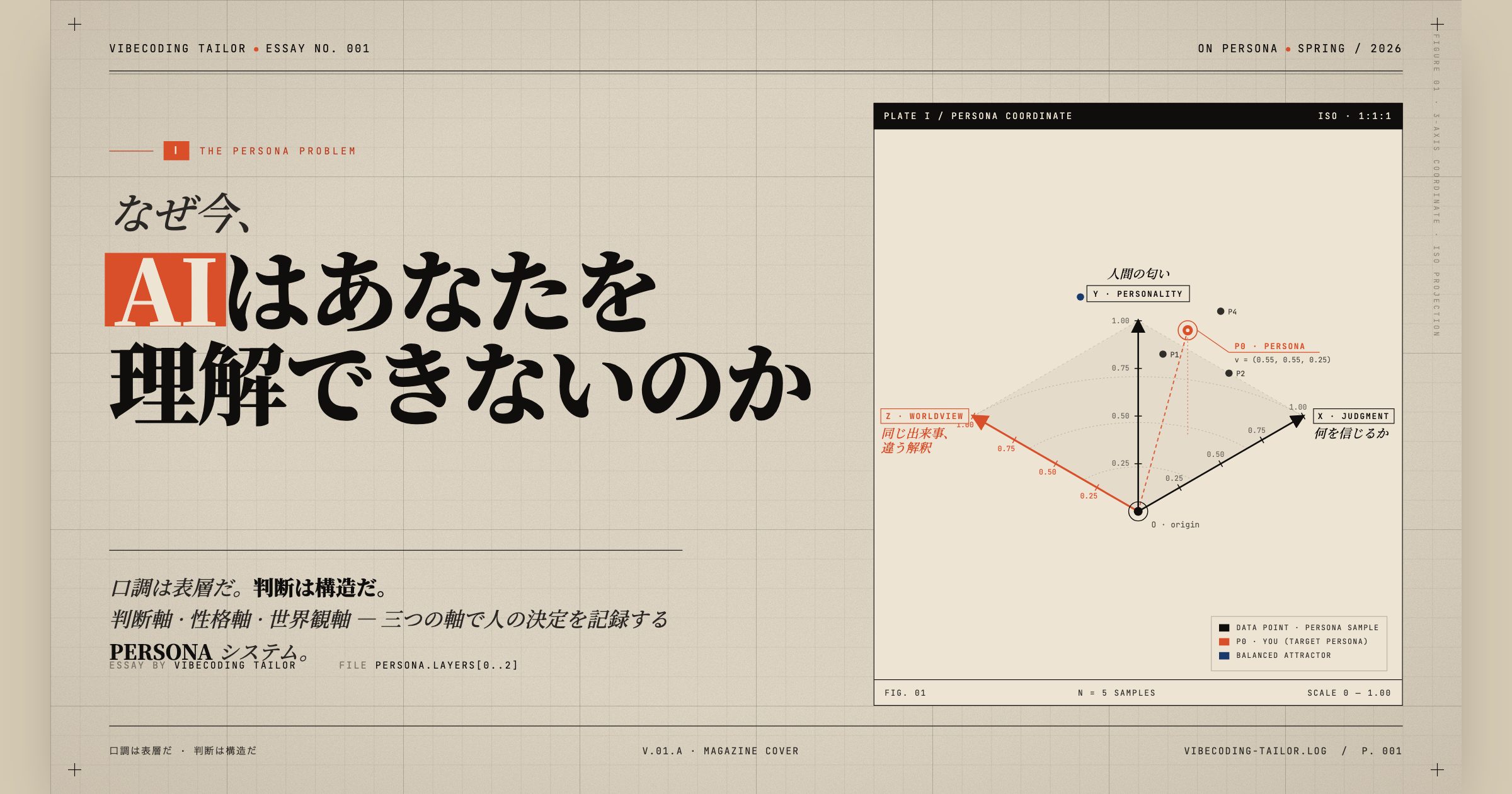
判断軸
同じ証拠を見たとき、何を信じ、何を保留し、どこで線を引くか。運用ルールと絶対禁止ラインを記録する。
性格軸
同じ結論でも実行速度、プレッシャー時の反応、失敗後の回収方法が異なる。気質とテンポを記録する。
世界観軸
なぜ同じ出来事をそう解釈するのか。世界を読む基本フレームと禁止ブリッジを記録する。
1段階:判断軸 — 何を信じ、どこで止まるか
だから私が最初に作ったのは判断軸一つだった。
なぜここから始めたか。既存のpersonaは口調やキャラクターに行くのが早すぎると思ったからだ。しかし人を人たらしめるのはそこではない。
- 何を事実として上げるか
- 何をまだシグナルのまま残すか
- どこで止まるか
- どんな文章を価値があると見るか
- どんなリスクに対して急に保守的になるか
例を挙げよう。私のシステムにはこんなルールが書いてある。
「自分だけが負う可逆的な損失には比較的寛容だ。だが他人に波及するリスクにはずっと厳格になる。」
これは口調ではない。判断の非対称構造だ。これを知っていればAIは「この事業提案を受けるべきか?」に対して単に「良さそうです」ではなく、「あなただけが損する部分と、他の人に影響が及ぶ部分を分けて見るべきです」と言える。
もう一つ。
「決済、実際の金銭支出、損失確定はclone scoreがいくら高くても自動化禁止。」
これも判断軸に記録された絶対ルールだ。「AIが代わりに決済していいか?」という問いに、このシステムは常に「ダメだ」と答える。スコアが100点でも。
判断軸はこうして、同じ証拠を見たとき何を信じ、何を保留し、どこで線を引くかを記録する。出発点としては十分だった。
だが限界があった。
2段階:性格軸 — 結論が同じでも人間味が違う
判断の方向はある程度合わせられた。だが問題は、結論が合っていても「人間味」が違うケースが出てきたことだ。
同じ結論でも実際の人間は違う動き方をする。速度が違う。プレッシャーがかかったとき保守化するタイミングが違う。人や組織の読み方が違う。失敗後の回収方法が違う。
私の場合、こんな気質がある。
- 価値が大きいと感じたら非常に速く入る。「十分に知るまで待つ」より「まず入って学びながら補正する」タイプだ。
- 失敗を避けるより、失敗後に何を回収できるかも見る。大きな構造が崩れても比較的すぐに「次の盤の材料」として読み直す。
- 他人に波及するリスクには非常に速く保守化する。保守/攻撃の基準が一般的な性向論ではなく「誰が傷つくか」に紐づいている。
こうしたことは判断軸だけでは捉えられない。結論は同じでもテンポと反応の仕方が違う人は、実質的に違うシステムだ。
だから性格軸が別レイヤーとして加わった。気質、社会的反応、状態変化、性格ベンチマークがこの時正式に組み込まれた。
重要なのは、この時も判断軸のスコアはそのまま据え置いたということだ。構造は広げたがスコアは保守的に維持した。「性格軸を追加したから全体スコアを上げよう」という水増しはしなかった。
3段階:世界観軸 — 同じ事件をなぜ違うように読むか
判断軸と性格軸を揃えても解けないことがあった。
「なぜ同じ出来事をそう解釈するのか」を十分に説明できなかった。
同じ判断、同じ反応を見せても、その裏にある解釈レンズが違えば、長期的にはまったく違う人になる。例えば:
- 「大きな成功は実力だけでなく運の比重も大きい」
- 「だが挑戦がなければ運が作用する表面も開かない」
- 「成功事例だけ見ると生存者バイアスにかかる」
- 「失敗を嘲笑し、成功の裏の苦労だけを美化するのは、どちらも結果だけを見る態度だ」
これは判断基準ではない。性格でもない。世界を読む基本フレームだ。同じニュースを見ても「我々もすぐ飛び込むべきだ」と読む人もいれば、「あの成功の裏に何が隠れているか」を先に読む人もいる。この違いが世界観だ。
だから世界観軸が追加された。
だが世界観をそのまま入れると危険だ。魅力的な解釈一つで危険な判断を正当化できてしまうからだ。だから世界観軸には必ず禁止ブリッジが付いている。
自伝 → 最終判断直結禁止。辛い経験一つがそのまま最終判断を開いてしまうと、システムが人を理解するのではなく自己合理化マシンになる。世界観 → 発行承認直結禁止。解釈がどれだけ魅力的でも、それだけで発行や外部約束を開いてはいけない。事実検証と安全ゲートは別途通す必要がある。
世界観軸は「なぜそう読むのかを説明するレイヤー」であり、証拠基準や高リスク承認を開くレイヤーではない。
毎週月曜日、AIトレンドニュースレター配信中
会員登録すると毎週月曜日に「今週のAI・バイブコーディング最新情報」をお届けします。
バナー広告なし、本当に役立つ情報だけを届けるクリーンなAI専門メディアです。
実例:一つの場面、三つの軸
ここまで読むと抽象的に聞こえるかもしれない。実際の例を一つ見よう。
私が強く嫌う状況が二つある。
一つ目は、教授が前でアナウンスを始めたのに学生がカバンを詰めてノートPCを閉じる音で聞こえなくなる状況。
二つ目は、横断歩道で青信号だけ見て車を確認せずに歩く態度。
一見すると違う場面だ。一つはマナーの問題、もう一つは安全の問題に見える。
だが私のシステムでは、この二つの場面から同じ構造を読み取る。
性格軸の記録
「公的空間でshared attentionが壊れることを強く嫌う。」
「不可逆的損失がかかる状況で、コストがほぼゼロの追加確認を省略することを嫌う。」
→ これは気質だ。
判断軸の記録
「形式的な安全シグナルがあっても、実際の物理的危険は別途確認する。」
「他人に生命の責任を事実上アウトソースする行動を無責任と見る。」
→ これは運用ルールだ。
世界観軸の記録
「形式的シグナルがあるからといって実際の安全が自動保証されるわけではない。」
「基本的な安全責任はシステムではなく個人が最終的に保有する。」
→ これは解釈レンズだ。
重要なのは、この場面一つがすぐに「だからこの人は元々こういう人だ」にはならないということだ。
私のシステムの処理順序はこうだ。
- 原文をそのまま保存する
- 事例ドキュメントにまとめる — 何が起きて何を読み取ったかを整理する
- 性格/判断/世界観の各軸で何を読み取るかを分離する
- 繰り返し使える解釈レンズを抽出する
- そのレンズがどこまで許されるかbridgeをチェックする
- イベント記録、証拠記録を残す
- 現在のスタンスに反映する
- エントリーポイントを更新する
- それでもすぐには活性化しない — shadow状態でさらに検証する
このシステムは自分の物語を感動的な自己叙事として保管するものではない。後で似た状況が来たとき、なぜそう解釈し、どこで止まるべきかを再現する材料に変換する構造だ。
本当に難しいのは時間、重み付け、bridgeだ
ここまで説明した3軸構造は、いわば分類作業だ。難しくない。
本当の難題はこれだ。
判断、性格、世界観は時間とともに変わる。だが同じ速度では変わらない。
世界観は比較的ゆっくりかもしれない。判断と性格はより頻繁に動くかもしれない。だがさらに難しいのは、同じ軸の中でも要素ごとに変化速度が異なるということだ。
判断軸の中でも「他人リスクに厳格」という基準は10年経っても変わらないかもしれない。一方「どのAIツールが良いか」という判断は1ヶ月で覆る。同じ軸なのに半減期がまったく違う。
だから「判断軸は速く変わる、世界観は遅い」と軸全体をまとめて言うと、ほぼ確実にずれる。
必要なのは:
- 軸の分離
- 要素別の重み付け — 直接陳述、反復行動、公開観察は同じ重みで読まない。証拠タイプごとに強度を異なるレベルで付ける
- 要素別の半減期 — 世界観レベルの信念は半減期が長い。ツール優劣の判断は短い
- 人ごとに異なる変化速度の測定
- 軸間のbridge設計
bridgeが重要な理由は、3軸が互いに孤立した箱ではないからだ。
世界観は判断に影響を与える。「AI時代に知識より問題定義が重要だ」という世界観を持つ人は、コーディング能力を評価する時も「どれだけうまく書けるか」より「何を作るか先に定義できるか」をより重視する。
性格は同じ判断でも実行方法を変える。論理的に同じ結論でも、素早く実行する人と長く躊躇する人では結果が異なる。
繰り返された判断は再び世界観を強化または修正し得る。
だからフォルダ3つ作るだけでは足りない。bridgeがなければ分離ではなく分解しただけだ。
私のシステムではこの変化をstale判定で扱う。仮想シナリオを複数作ってpersonaに答えさせ、実際の自分の判断と比較する。3つ以上のシナリオで繰り返しずれが出れば「この部分は古い」と判定して更新する。
なぜmd、graph、raw promptにこだわるのか
このプロジェクトの深さは趣味ではなくmethodsにある。
ファイルをたくさん積むだけでは意味がない。表紙のない本が積まれた図書館と同じだ。本は多いが、どの本が何で、なぜ重要で、どの本と繋がっているかが分からなければ使えない。
だから二つにこだわる。
一つ目はmd-first。AIが読み、繋げ、書き直し、比較するにはマークダウンがはるかに良い。同時に人間もテキストエディタ一つですぐ読んで修正できる。
二つ目はgraph-first。すべてのドキュメントに役割があり、ドキュメント間の接続が見えなければならない。現在のシステムは100以上のマークダウンファイルが相互接続されている。判断基準ドキュメントは証拠台帳と接続され、証拠台帳は元のプロンプトと接続されている。
プロンプト原文にあなたの思考構造が入っている
入力プロンプトはできる限り原文のまま残すべきだ。
AIに何かを頼むとき、あなたが打つプロンプトには思った以上に多くの情報が入っている。
- 何を先に言うか → 優先順位が見える
- どんな言葉を使うか → 思考方法が見える
- 何を省くか → 当たり前と思っていることが見える
- どんな順序で要求するか → 問題解決の構造が見える
出力は要約してもいい。AIが出した結果は短くまとめても核心は残る。
だが入力は違う。あなたが「この構造で一番危ないのは何?」と聞いたのか、「これ大丈夫?」と聞いたのかは、まったく異なる思考方法だ。要約するとこの違いが消える。
プロンプトを積み重ねると1日でもかなりの量が記録される。テキストベースなので容量自体は負担にならないが、AIに入力できるトークン上限はすぐに埋まる。
数日分集めるだけでモデルのコンテキストに丸ごと入れるには大きすぎる。だから次の話が出てくる。
なぜlog.mdはダンプではなくretrieval構造であるべきか
log.mdに毎日記録を積むと、1週間で7,000行。1ヶ月で3万行。
これを毎回丸ごとAIに入れると? 遅く、高く、核心が埋もれる。
だからlog.md設計の核心は記録量ではなくretrieval path(検索パス)だ。
「このログをいつ、なぜ再び読むのか」を先に決めておくこと。
| 質問 | どこを読むか |
|---|---|
| 「このファイルはいつ変わった?」 | ファイル変更履歴インデックス |
| 「先週どんな判断をした?」 | 週次ロールアップ要約 |
| 「このルールはなぜ作られた?」 | 該当証拠台帳 + 元プロンプト |
| 「personaが古くなっていないか確認して」 | 最新のshadow評価結果 |
このように質問 → どこを見るかを事前にマッピングしておけば、3万行のログから必要な200行だけ取り出せる。
私はこれをuse-case-first retrievalと呼んでいる。データを先に積んで後から探すのではなく、「このデータをどんな状況で使うのか」を先に設計する方式だ。
自分の試験勉強にもこのシステムを使っている
このプロジェクトは「自分に似たAI」を作るところで終わらない。
今、大学の試験勉強でこのシステムのfirst-party実験をしている。物理化学の試験資料をすべてAIに渡し、自分のPERSONAに合った勉強設計を受ける実験だ。
既存のAI学習ツールにできないこと
これまで教育分野でAI個別化と呼ばれてきたものは、ほとんどが進度推薦、問題推薦、難易度調整で止まっている。
だが、同じ熱力学第2法則を学んでも、Aという学生は式から始めなければ掴めず、Bという学生はカルノーサイクルの図から始めなければ掴めない。Cという学生は「なぜエントロピーは常に増大しなければならないのか?」という問いから入らないと理解できない。
これは難易度の問題ではなく認知構造の問題だ。同じ内容、同じレベルなのに進入方法が違う。既存のAI学習ツールはこの違いを見ていない。
実際に何を記録しているか
ここで記録しているのは試験成績ではない。勉強した時間でもない。自分が工学という専門分野をどんな認知構造で理解しようとしているかを記録している。
セッション1つが終わったら以下の5つだけ残す。短く残す。
- 開始層位 — 新しい概念に出会ったとき、どこから入るか。
- 最初の理解方式 — 式、図、メカニズム、事例のうち何で先に掴むか。
- 連結方式 — 概念をどの軸で繋ごうとするか。
- 反復躓き — どこでよく止まるか。
- 回復方式 — correctionを受けたとき、どの方法で最も速く回復するか。原理の再陳述か、解法の例題か、比較表か、視覚的確認か。
例えばこういうことだ。物理化学の第1法則を勉強するセッションで、自分は熱力学エネルギーの層位から入り、式でまず理解しようとし、「熱力学→安定性」軸で繋ごうとするが、exact differentialとinexact differentialで符号条件がよく混同し、原理をもう一度一文で言ってみるように促されると最も速く回復する。これが1行の認知スナップショットだ。
5段階学習ループ
この記録は勉強方法論とも繋がっている。自分が使う学習ループは5段階だ。
- 圧縮 — 現在の範囲を核心概念と核心式に絞る。
- Meaning — 各式と概念を「定義 / 成立条件 / 物理的意味」で改めて説明する。ここで詰まれば暗記したのであって理解したのではない。
- 閉本想起 — 資料を閉じてすぐ書くか口に出す。
- Cheap Check — 単位は合っているか。const p / const V / const Tのうち何が固定か。符号が反転していないか。理想気体でだけ成り立つのか実在気体でも使えるのか。
- Patch — 誤答を長く反省せず即座にパッチする。
セッションが終わったら残すのはちょうど3つだ。今日学んだ構造1つ、今日混乱した箇所1つ、次に最初に見るcheap check 1つ。これ以上は残さない。きれいなノートを作ることが勉強ではないからだ。
世界観が学習方法にも現れる
ここで面白いのは、自分の世界観軸が勉強方法にも表れるという点だ。
自分は高校生の頃から「人々がいくら善く生きても地球環境が壊れたら終わりではないか」と考えていた。環境問題を道徳の問題ではなく技術基盤の問題として読んでいた。だから「最も下層の素材を変えるのが努力あたりのインパクトが大きい」と判断し、工学を選んだ。
これは専攻を学んでそうなったのではない。もともと基盤層を先に見る世界観があり、その結果として専攻を選んだのだ。因果の方向が逆だ。
そして今、AIツールを見るときも、未来産業を分析するときも、PERSONAシステムを設計するときも同じパターンが出る。表面の機能より下層の構造とボトルネックを先に見る。物理化学を勉強するときも「この式は何を定義しているのか、何を近似しているのか」をまず問う。この繰り返される進入パターンそのものが世界観軸のevidenceだ。
ただし、これを「専門家だから正しい」と昇格させることはしない。学習方法に見える反復パターンは学習専用projectionで観察するだけで、master personaにそのまま上げない。
適応ルール:失敗が積み重なると方法が変わる
このシステムは静的な勉強法ではない。記録されたパターンに応じて勉強法そのものが変わる。
- 意味の説明でよく詰まる → 説明型の質問の比重を増やす
- 式の想起が弱い → equation sheetと想起ドリルの比重を増やす
- グラフ解釈がよく間違う → graph-reading noteと視覚資料レンダリングの比重を増やす
- 符号/条件のミスが繰り返される → cheap checkリストをセッション開始時にまず見る
- 記録のせいで速度が落ちる → セッションメモを3行ルールに再び絞る
最後のルールが重要だ。記録が学習速度を落とすなら記録を減らす。このシステムは「記録を減らす勉強法」ではなく「記録の位置を変える勉強法」だ。プロンプト原文は保存しないが、理解構造と反復エラーはより鮮明に残す。
本当の個別化教育の方向
このようにデータが積み重なると何が可能になるか。
- 同じ開始層位が繰り返される → この学生の基本進入点がわかるようになる
- 同じ理解方式が繰り返される → この学生の基本理解インターフェースがわかるようになる
- 同じ連結軸が繰り返される → この学生が知識を組織する主連結軸がわかるようになる
- 同じ躓きが繰り返される → 勉強法修正の最優先対象がわかるようになる
- 同じ回復方式が繰り返される → この学生に合った矯正方式がわかるようになる
長期的には、学生ごとに異なる理解構造に合った個人教科書、個人学習帳、個人コンセプトマップを作る方向へ進める。「どの問題をもっと解くべきか」ではなく、「この学生には熱力学をエネルギー保存から始めるのがいいか、エントロピーから始めるのがいいか」を設計できるようになる。
今、自分はその可能性を自分自身を実験対象にしてfirst-partyで試している。現在、物理化学3チャプターに適用しており、今後は電子材料、材料熱力学、工学数学にも同じ運用を拡張する予定だ。
まだ実験中だ — 解釈禁止ルール
ただし、いくつかの線を明確にしておく必要がある。
これは構築中のfirst-party experimentだ。まだセッション数が少なく、教科横断の検証も初期段階だ。
解釈の禁止ルールもある。
- 単一セッション1つで認知構造を確定しない
- 疲れた日の失敗を性格に昇格させない
- 特定科目の一時的ボトルネックを全体の認知能力に一般化しない
- このデータだけでmaster PERSONAを変えない
同じ人が物理化学、材料熱力学、電子材料で似た進入/連結パターンを見せるかどうか交差検証するまでは、反復パターンが出ても即座にコアpersonaへ上げず、学習専用projectionでまず補正する。
関連記事:未来産業の本当の現場でAIができることもこの視点で読むと新たな発見がある。
最終目標:99%精度の判断アバター
このプロジェクトの長期目標を先に言う。
PERSONAの最終目標はadvisory shadowではない。最終判断まで99%の水準で自分と同じ方向を出すアバターを作ることだ。
決済や他人に影響が及ぶごく少数の判断だけ人間承認で残し、残りはPERSONAが代行する。今AI業界はあらゆることを自動化しようと拡大しているが、その自動化には最後の関門がある。「この人ならどう判断しただろうか。」私が作っているのはその関門だ。
そしてこの目標に向けて今動かしている核心メカニズムが一つある。
次のプロンプト予測は文章当てではない。実際の使用過程で予測と差分を継続的に比較し補正するcalibration loopだ。
システムがコンテキストを読み、次のリクエストの方向を先に予測する。実際のプロンプトが入力されたら予測と比較し、差分を補正材料として蓄積する。このループが回るほどシステムがユーザーの次の判断をより正確に読むようになる。
今はまだbuilding状態だ
上に書いたのは最終目標:99%精度の判断アバターだ。今いる場所ではない。
現在のシステム状態を正直に言うとこうだ。
- 判断軸:まだbuilding段階
- 性格軸:スコア未付与
- 世界観軸:shadow-only、比較実験用途でのみ使用可能
- 全体状態:building
- 実戦使用:blocked — 別途検証ゲートを通過する必要がある
今このシステムは私の判断を代替しない。shadowモードで私の判断と比較し、差が出るポイントを記録し、構造を補正する段階だ。
このプロジェクトは論文レベルの主張管理も同時に回している。すべての主張を「今書けるもの」と「まだ書いてはいけないもの」に分けて管理している。
- 構造的分離が単純なスタイル複製より安全か → まだ仮説段階
- 問題定義と次のリクエストまで複製できるか → 長期ビジョンであり検証結果ではない
- 記録構造が監査可能な研究対象を作るか → 部分的に支持されるが外部再現はまだ
「言いたいこと」と「立証責任がある文」を混ぜないのがこのプロジェクトの原則だ。
このシステムが危険になるポイント
このシステムは心理診断ツールではない。誰かを臨床的に解釈したり、治療を代替したり、「心を読む」と言うシステムではない。判断と解釈の構造を長期的に記録しモデリングするmethods-heavy prototypeだ。
そしてこのシステムが問題定義と次のリクエスト生成まで複製し始めるなら、既存の「人間が最終判断を持つ」という運営規範を直接圧迫することになる。だからこのプロジェクトは機能拡張より安全質問を先に扱う。「これができたら何が良くなるか」より「これができたら何が危険になるか」を先に問うべきだと考えている。
personaを自動で収集することと自動で昇格することも違う。口癖や繰り返し行動は自動で集めてもいい。しかし「この人の核心価値観はこれだ」と上げるのは、必ず本人が確認しなければならない。自動収集と自動昇格を混同した瞬間、AIがあなたを間違って理解したまま間違った判断を下すことになる。
読者に提示する次のアクション
ここまで読んで「それで自分は何をすればいいの?」と思っただろう。
一つだけやればいい。
プロジェクトを始めるたびにlog.mdを一つ作り、AIに送ったプロンプトを原文のまま残せ。
出力は短く要約してもいい。「こんな結果が出た」の一行で十分だ。だが入力プロンプトはそのままコピーして貼れ。
あなたのプロンプトにはあなたの優先順位、思考方法、表現の癖、問題解決の順序がすべて入っている。これが積もれば、後でAIがあなたを理解する材料になる。
AIがあなたを理解するようになる第一歩は、あなたが自分を記録することだ。
この記事の内容は現在構築中のPERSONAシステムから生まれたものです。システムはbuilding状態であり、すべての判断補助結果は人間の最終確認を経ます。
PERSONAの3軸構造
判断軸
何を事実に昇格し、何を保留するか。どこで止まるか。変化速度:速い
性格軸
失敗後の回復速度。圧力時の保守化。人の読み方。変化速度:遅い
世界観軸
同じ事件をなぜそう読むか。成功は運か実力か。変化速度:最も遅い
ストーリーが判断に変わるまでの流れ
⚠ biography→最終判断の直結と、世界観→発行承認の直結は禁止ブリッジ
よくある質問(FAQ)
Q. PERSONAシステムはMBTIや性格タイプ診断と何が違うのですか?
MBTIは固定された類型分類です。PERSONAは判断軸・性格軸・世界観軸の3軸に分けて記録しつつ、時間とともに変わる部分まで追跡します。「この人はINTJだ」で終わるのではなく、「この状況でこの人はどんな順序で判断し、どこで止まるか」を記録します。
Q. log.mdを始めるにはどんなフォーマットが必要ですか?
フォーマットは重要ではありません。日付とともにAIに送ったプロンプト原文をそのまま貼り付ければOKです。出力は一行の要約で十分。重要なのは入力原文が残っていることです。後でログが大きくなったらその時にretrieval構造を設計すればいいです。
Q. このシステムが完成すればAIが自動で判断を代行してくれるのですか?
完成すれば任せられます。このプロジェクトの最終目標は、99%の精度で自分と同じ判断を下すアバターを作ることです。決済や他人に影響が及ぶごく少数の判断だけ人間承認で残し、残りの判断はPERSONAが代行します。今AI業界はあらゆることを自動化しようと拡大していますが、その自動化の最後の関門は「この人ならどう判断しただろうか」です。このシステムはその関門を作るプロジェクトです。
著者:VibeCoding Tailor(Lovable公式アンバサダー)
ソースリスト
- Generative Agents: Interactive Simulacra of Human Behavior (Stanford/Google, 2023) — AIエージェントが人間のように振る舞うシミュレーション研究
- 未来産業の本当の現場でAIができること — shuntailor.net
- バッテリーが未来インフラの核心である理由 — shuntailor.net




