
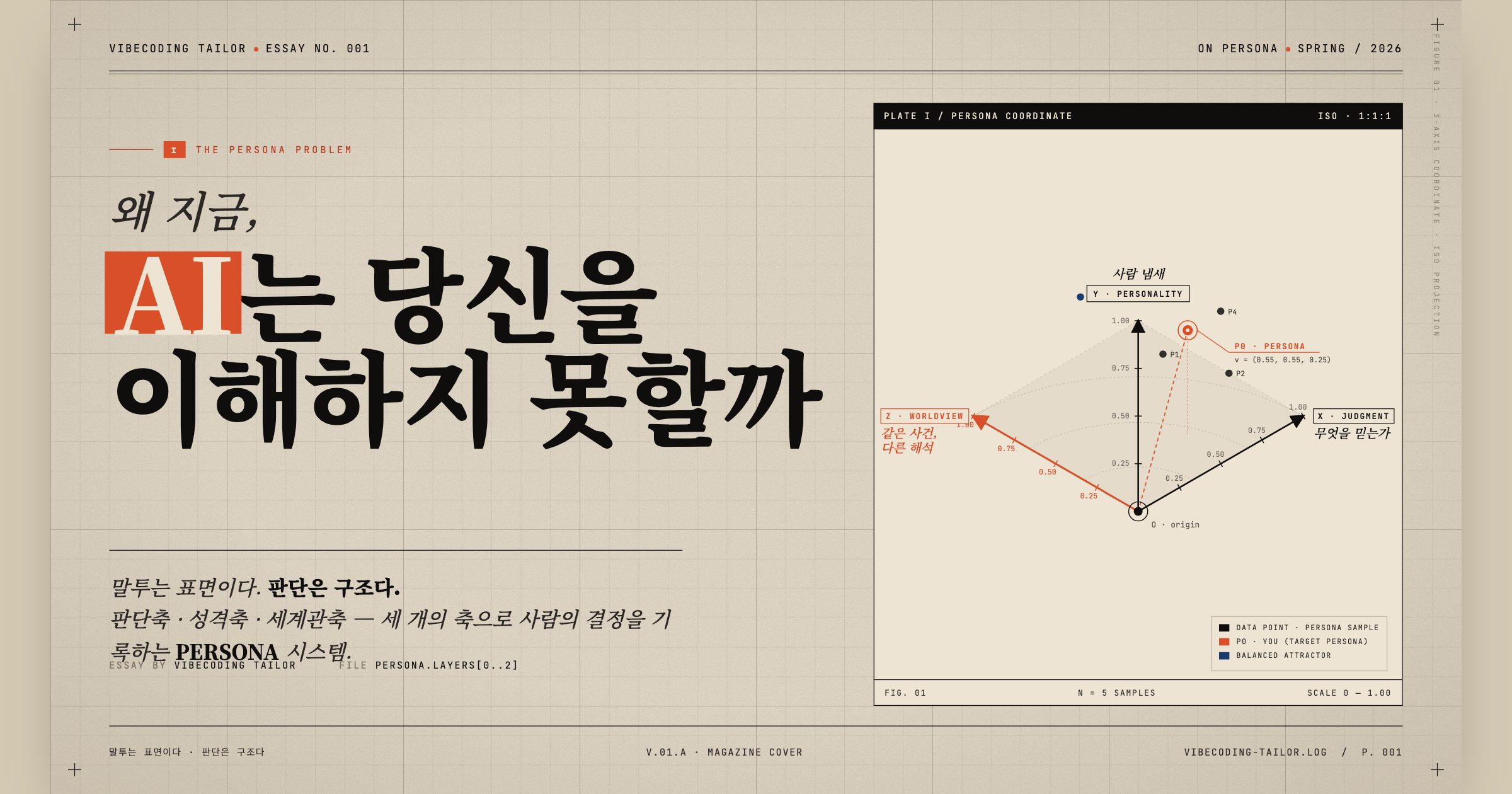
AI 페르소나 판단 구조를 이해하지 못하면, AI는 당신의 말투만 흉내 낼 뿐 진짜 판단은 재현하지 못한다. 이 글에서는 판단축·성격축·세계관축 3축으로 사람의 판단 구조를 기록하는 PERSONA 시스템이 왜 필요한지, 어떤 순서로 만들어졌는지를 보여준다.
AI는 말투는 따라하지만 판단은 못한다
ChatGPT에게 “나처럼 말해봐”라고 해본 적 있는가.
말투는 꽤 잘 따라한다. 문장 끝에 “~거든”을 붙이고, 이모지를 적당히 섞고, 존댓말과 반말을 번갈아 쓰면 그럴듯해 보인다.
그런데 이런 걸 한번 시켜보자. “이 사업 제안을 받아들일지 말지 판단해줘.”
갑자기 무너진다. 당신이라면 상대의 이해관계를 먼저 읽을 건지, 돈부터 볼 건지, 아니면 “일단 해보고 나중에 생각하자”고 할 건지. 어디서 멈추고 어디서 밀어붙이는지. 그런 판단의 순서를 AI는 모른다.
말투는 표면이다. 판단은 구조다. 지금 대부분의 AI persona 시스템은 표면만 복사하고 구조는 건드리지 못한다.
더 정확하게 말하면, 지금 AI가 못 하는 건 “무엇이 진짜 문제인지 정의하는 것”과 “다음에 무엇을 요청해야 하는지 고르는 것”이다. 답변은 잘한다. 초안도 잘 만든다. 코드도 짠다. 하지만 “지금 뭘 먼저 해야 하지?”, “이 상황에서 뭘 물어봐야 하지?”, “이건 지금 말하면 안 되는 건데”를 판단하는 건 여전히 사람 몫이다. 그리고 그 사람마다 판단 방식이 다르다.
나는 지금 이 문제를 직접 풀고 있다. AI가 사람의 판단 구조를 재현할 수 있는 시스템을 만들고 있고, 논문화할 수 있는 수준으로 정리하고 있다. 다만 이 글은 “완성된 시스템 소개”가 아니다. 어떤 문제가 있어서, 어떤 순서로 구조가 생겨났는가를 보여주는 글이다.
“친절한 20대 마케터”는 페르소나가 아니다
지금 대부분의 AI persona 설정은 이런 식이다.
“너는 친절한 20대 마케터야. 이모지를 자주 쓰고, 반말로 말해.”
이게 persona인가? 아니다. 이건 말투 설정이다.
MBTI를 넣어도 마찬가지다. “INTJ니까 논리적으로 말해”라고 쓰면, AI는 매번 “논리적으로 분석해보면…”으로 시작하는 글을 뱉는다. 그런데 실제 INTJ가 모든 상황에서 논리적으로만 판단하는가? 아니다. 화가 나면 논리를 버리기도 하고, 10년 후를 생각하면 당장의 손해를 감수하기도 한다.
실제로 같이 일해보면, 진짜 차이는 “차분하다/직설적이다/전략적이다” 같은 묘사에서 안 갈린다. 진짜 차이는 이런 데서 갈린다.
- 정보가 부족할 때 어디까지 말하는가
- 언제 멈추는가
- 실패했을 때 무너지는가 회수하는가
- 무엇을 작은 실수로 보고 무엇을 절대 안 되는 실수로 보는가
- 같은 사건을 기회로 보는가 위험으로 보는가
기존 persona 시스템의 문제를 세 줄로 줄이면 이렇다.
- 말투만 복사하고 판단 순서는 안 본다
- 한 번 설정하면 변하지 않는다
- “왜 그렇게 판단하는지”의 근거가 없다
판단축
같은 증거를 봤을 때 무엇을 믿고, 무엇을 보류하고, 어디서 선을 긋는가. 운영 규칙과 절대 금지선을 기록한다.
성격축
같은 결론이어도 실행 속도, 압박 시 반응, 실패 후 회수 방식이 다르다. 기질과 템포를 기록한다.
세계관축
왜 같은 사건을 그렇게 해석하는가. 세상을 읽는 기본 프레임과 금지 브리지를 기록한다.
1단계: 판단축 — 무엇을 믿고 어디서 멈추는가
그래서 내가 처음 만든 건 판단축 하나였다.
왜 여기서 시작했는가. 기존 persona는 너무 빨리 말투, 캐릭터, 인상으로 간다고 봤기 때문이다. 하지만 사람을 사람답게 만드는 건 거기가 아니다.
- 무엇을 사실로 올리는가
- 무엇을 아직 신호로만 남기는가
- 어디서 멈추는가
- 어떤 글을 가치 있다고 보는가
- 어떤 리스크에는 급격히 보수화되는가
예를 들어보자. 내 시스템에는 이런 규칙이 적혀 있다.
“자기만 감당하는 가역적 손실에는 비교적 관대하다. 하지만 타인에게 번지는 리스크에는 훨씬 엄격해진다.”
이건 말투가 아니다. 판단의 비대칭 구조다. 이걸 알면 AI는 “이 사업 제안을 받을까?”에 단순히 “좋아 보입니다”가 아니라, “당신만 손해볼 수 있는 부분과 다른 사람에게 영향이 가는 부분을 나눠서 봐야 합니다”라고 말할 수 있다.
또 하나.
“결제, 실제 금전 지출, 손실 확정은 clone score가 아무리 높아도 자동화 금지다.”
이것도 판단축에 기록된 절대 규칙이다. “AI가 대신 결제해도 될까?”라는 질문에 이 시스템은 항상 “안 된다”고 답한다. 점수가 100점이어도.
판단축은 이런 식으로, 같은 증거를 봤을 때 무엇을 믿고, 무엇을 보류하고, 어디서 선을 긋는가를 기록한다. 시작점으로서는 충분했다.
하지만 한계가 있었다.
2단계: 성격축 — 결론이 같아도 사람 냄새가 다르다
판단 방향은 어느 정도 맞출 수 있었다. 그런데 문제는, 결론이 맞아도 사람 냄새가 틀린 경우가 생겼다는 것이다.
같은 결론이어도 실제 사람은 다르게 움직인다. 속도가 다르다. 압박이 들어왔을 때 보수화되는 시점이 다르다. 사람과 조직을 읽는 방식이 다르다. 실패 후 회수 방식이 다르다.
내 경우를 보면 이런 기질이 있다.
- 가치가 크다고 느끼면 매우 빠르게 들어간다. “충분히 알 때까지 기다린다”보다 “먼저 들어가고 배우며 보정한다” 쪽이다.
- 실패를 피하는 것보다 실패 후 무엇을 회수할 수 있는가를 같이 본다. 큰 구조가 무너져도 비교적 빠르게 “다음 판의 재료”로 다시 읽는다.
- 타인에게 번지는 리스크에는 매우 빠르게 보수화된다. 보수/공격의 기준이 성향 일반론이 아니라 “누가 다치는가”에 묶여 있다.
이런 건 판단축만으로는 담을 수 없다. 결론은 같을 수 있지만, 템포와 반응 방식이 다른 사람이면 실제로는 다른 시스템이다.
그래서 성격축이 별도 층으로 붙었다. temperament, social dynamics, state modifiers, 성격 벤치마크가 이때 정식으로 들어갔다.
중요한 건, 이때도 판단축 점수는 그대로 뒀다는 점이다. 구조는 넓혔지만 점수는 보수적으로 유지했다. “성격축을 추가했으니 전체 점수를 올리자”는 식의 부풀리기는 안 했다.
3단계: 세계관축 — 같은 사건을 왜 다르게 읽는가
판단축과 성격축을 갖추고도 풀리지 않는 게 있었다.
“왜 같은 사건을 그렇게 해석하는가”를 충분히 설명할 수 없었다.
같은 판단, 같은 반응을 보여도, 그 뒤에 깔린 해석 렌즈가 다르면 장기적으로 완전히 다른 사람이 된다. 예를 들어:
- “큰 성공은 실력만이 아니라 운의 비중도 크다”
- “하지만 도전이 있어야 운이 작용할 표면도 열린다”
- “성공사례만 보면 생존자 편향에 걸린다”
- “실패를 조롱하고, 성공 뒤의 고생만 미화하는 둘 다 결과만 보는 태도다”
이건 판단 기준이 아니다. 성격도 아니다. 세상을 읽는 기본 프레임이다. 같은 뉴스를 보면서도 어떤 사람은 “우리도 빨리 뛰어들어야 한다”고 읽고, 어떤 사람은 “저 성공 뒤에 뭐가 숨어 있을까”를 먼저 읽는다. 이 차이가 세계관이다.
그래서 세계관축이 추가됐다.
하지만 세계관을 그냥 넣으면 위험하다. 멋진 해석 하나로 위험한 판단을 정당화할 수 있기 때문이다. 그래서 세계관축에는 반드시 금지 브리지가 같이 붙어 있다.
자전적 서사 → 최종 판단직결 금지. 힘든 경험 하나가 곧바로 최종 판단을 열어 주면, 시스템이 사람을 이해하는 게 아니라 자기합리화 기계가 된다.세계관 → 발행 승인직결 금지. 해석이 아무리 매력적이어도, 그것만으로 발행이나 외부 약속을 열면 안 된다. 사실 검증과 안전 게이트는 따로 지나야 한다.
세계관축은 “왜 그렇게 읽는가”를 설명하는 층이지, 증거 기준이나 고위험 승인을 여는 층이 아니다.
매주 월요일, AI 트렌드 뉴스레터 발행 중
회원 등록하면 매주 월요일에 「이번 주 AI·바이브코딩 최신 정보」를 보내드립니다.
배너 광고 없이 정말 쓸모 있는 정보만 골라 전하는 클린 AI 전문 미디어입니다.
실제 예시: 하나의 장면, 세 개의 축
여기까지만 읽으면 추상적으로 들릴 수 있다. 실제 예를 하나 보자.
나는 두 가지 상황을 강하게 싫어한다.
첫째, 교수가 앞에서 공지를 시작했는데 학생들이 가방을 싸고 노트북을 닫는 소리로 들리지 않게 만드는 상황.
둘째, 횡단보도에서 파란불만 보고 차를 확인하지 않고 걷는 태도.
언뜻 다른 장면이다. 하나는 예의 문제, 하나는 안전 문제처럼 보인다.
하지만 내 시스템에서는 이 두 장면에서 같은 구조를 읽는다.
성격축 기록
“공적 공간에서 shared attention이 깨지는 것을 강하게 싫어한다.”
“비가역적 손실이 걸린 상황에서 비용이 거의 안 드는 추가 확인을 생략하는 것을 싫어한다.”
→ 이건 기질이다.
판단축 기록
“형식적 안전 신호가 있어도 실제 물리적 위험은 따로 확인한다.”
“타인에게 생명 책임을 사실상 외주하는 행동을 무책임하게 본다.”
→ 이건 운영 규칙이다.
세계관축 기록
“형식적 신호가 있다고 실제 안전이 자동 보장되는 것은 아니다.”
“기본 안전 책임은 시스템이 아니라 개인이 최종 보유한다.”
→ 이건 해석 렌즈다.
중요한 건, 이 장면 하나가 곧바로 “그래서 이 사람은 원래 이런 사람이다”로 가지 않는다는 점이다.
내 시스템의 처리 순서는 이렇다.
- 원문을 그대로 보존한다
- 사례 문서로 묶는다 — 무슨 일이었고 무엇을 읽었는지 정리한다
- 성격/판단/세계관 각 축에서 무엇을 읽는지 분리한다
- 반복 가능한 해석 렌즈를 뽑는다
- 그 렌즈가 어디까지 허용되는지 bridge를 점검한다
- 이벤트 기록, 증거 기록을 남긴다
- 현재 입장에 반영한다
- 엔트리포인트에 갱신한다
- 그래도 바로 활성화하지는 않는다 — shadow 상태에서 더 검증한다
이 시스템은 내 이야기를 감동적인 자기서사로 보관하는 게 아니다. 나중에 비슷한 상황이 왔을 때, 왜 그렇게 해석하고 어디서 멈출지를 재현하는 재료로 바꾸는 구조다.
3축보다 어려운 문제: 시간, 가중치, 축 사이 연결
지금까지 설명한 3축 구조는, 말하자면 분류 작업이다. 어렵지 않다.
진짜 난제는 이거다.
판단, 성격, 세계관은 시간이 지나며 변한다. 하지만 같은 속도로 변하지 않는다.
세계관은 상대적으로 느릴 수 있다. 판단과 성격은 더 자주 움직일 수 있다. 그런데 더 어려운 건, 같은 축 안에서도 요소마다 변화 속도가 다르다는 점이다.
판단축 안에서도 “타인 리스크에 엄격하다”는 기준은 10년이 지나도 안 바뀔 수 있다. 반면 “어떤 AI 도구가 더 좋다”는 판단은 한 달 안에 뒤집힌다. 같은 축인데 반감기가 완전히 다르다.
그래서 “판단축은 빨리 변한다, 세계관은 느리다”라고 축 전체를 통째로 말하면 거의 반드시 틀어진다.
필요한 것은:
- 축 분리
- 요소별 가중치 — 직접 진술, 반복 행동, 공개 관찰은 같은 무게로 읽지 않는다. 증거 유형마다 강도를 다르게 매긴다
- 요소별 반감기 — 세계관 수준 신념은 반감기가 길다. 도구 우열 판단은 짧다
- 사람마다 다른 변화 속도 측정
- 축 사이 bridge 설계
bridge가 중요한 이유는, 세 축이 서로 고립된 박스가 아니기 때문이다.
세계관은 판단에 영향을 준다. “AI 시대에 지식보다 문제 정의가 중요하다”는 세계관을 가진 사람은, 코딩 실력을 평가할 때도 “얼마나 잘 짜느냐”보다 “무엇을 만들지 먼저 정의할 수 있느냐”를 더 본다.
성격은 같은 판단이라도 실행 방식을 바꾼다. 논리적으로 같은 결론이어도, 빠르게 실행하는 사람과 오래 주저하는 사람은 결과가 다르다.
반복된 판단은 다시 세계관을 강화하거나 수정할 수 있다.
그래서 폴더 3개를 만드는 것만으로는 안 된다. bridge가 없으면 분리한 게 아니라 분해만 한 것이다.
내 시스템에서는 이 변화를 stale 판정으로 다룬다. 가상 상황을 만들어서 persona의 대답과 실제 내 판단을 비교한다. 같은 차이가 반복되면 “이 부분은 낡았다”고 판정하고 업데이트한다.
파일이 아니라 연결 구조를 만든다
이 프로젝트의 깊이는 취향이 아니라 methods에 있다.
파일을 많이 쌓는 것만으로는 의미가 없다. 표지 없는 책이 쌓인 도서관과 같다. 책은 많은데, 어떤 책이 무엇이고, 왜 중요하고, 어떤 책과 연결되는지가 안 보이면 쓸 수 없다.
그래서 두 가지를 고집한다.
첫째, md-first. AI가 읽고, 연결하고, 다시 쓰고, 비교하려면 마크다운이 훨씬 낫다. 동시에 사람도 텍스트 에디터 하나로 바로 읽고 고칠 수 있다.
둘째, graph-first. 모든 문서에 역할이 있어야 하고, 문서 사이의 연결이 보여야 한다. 현재 내 시스템은 100개 이상의 마크다운 파일이 서로 연결돼 있다. 판단 기준 문서는 증거 장부와 연결돼 있고, 증거 장부는 원본 프롬프트와 연결돼 있다.
프롬프트 원문에 당신의 사고방식이 들어있다
입력 프롬프트는 되도록 원문 그대로 남겨야 한다.
AI에게 뭔가를 시킬 때, 당신이 치는 프롬프트에는 생각보다 많은 정보가 들어 있다.
- 무엇을 먼저 말하는지 → 우선순위가 보인다
- 어떤 단어를 쓰는지 → 사고방식이 보인다
- 무엇을 빠뜨리는지 → 당연하게 여기는 것이 보인다
- 어떤 순서로 요구하는지 → 문제 해결 구조가 보인다
출력은 요약해도 된다. AI가 뱉은 결과는 짧게 정리해도 핵심이 남는다.
하지만 입력은 다르다. 당신이 “이 구조에서 제일 위험한 게 뭐야?”라고 물었는지, “이거 괜찮아?”라고 물었는지는 완전히 다른 사고방식이다. 요약하면 이 차이가 사라진다.
프롬프트를 쌓다 보면 하루에도 상당한 양이 기록된다. 텍스트 기반이라 용량 자체는 부담이 안 되지만, AI에 넣을 수 있는 토큰 한도는 금방 찬다.
며칠치만 모여도 모델 컨텍스트에 통째로 넣기엔 너무 커진다. 그래서 다음 이야기가 나온다.
로그는 쌓는 게 아니라 꺼내 쓰는 구조여야 한다
log.md에 매일 기록을 쌓으면, 일주일이면 7,000줄이다. 한 달이면 3만 줄.
이걸 매번 통째로 AI에게 넣으면? 느리고, 비싸고, 핵심이 묻힌다.
그래서 log.md 설계의 핵심은 기록량이 아니라 retrieval path(검색 경로)다.
“이 로그를 언제, 왜 다시 읽을 것인가”를 먼저 정해놓는 것이다.
| 질문 | 어디를 읽는가 |
|---|---|
| “이 파일은 언제 바뀌었어?” | 파일 변경 이력 인덱스 |
| “지난주에 어떤 판단을 했어?” | 주간 rollup 요약 |
| “이 규칙은 왜 만들어졌어?” | 해당 증거 장부 + 원본 프롬프트 |
| “persona가 낡았는지 확인해” | 최근 shadow 평가 결과 |
이렇게 질문 → 어디를 볼지를 미리 매핑해놓으면, 3만 줄의 로그에서 필요한 200줄만 꺼내 쓸 수 있다.
나는 이걸 use-case-first retrieval이라고 부른다. 데이터를 먼저 쌓고 나중에 뒤지는 게 아니라, “이 데이터를 어떤 상황에서 쓸 것인가”를 먼저 설계하는 방식이다.
내 시험공부에도 이 시스템을 쓰고 있다
이 프로젝트는 “나를 닮은 AI”를 만드는 데서 끝나지 않는다.
지금 나는 대학 시험공부에서 이 시스템의 first-party 실험을 하고 있다. 물리화학 시험 자료를 전부 AI에게 주고, 내 PERSONA에 맞는 공부 설계를 받는 실험이다.
난이도 조절이 아니라 인지 구조가 다른 문제
지금까지 교육 분야에서 AI 개인화라고 불리는 건, 대부분 진도 추천, 문제 추천, 난이도 조절에서 멈춘다.
하지만 같은 열역학 제2법칙을 배워도, A라는 학생은 식에서 시작해야 잡히고 B라는 학생은 카르노 사이클 그림에서 시작해야 잡힌다. C라는 학생은 “왜 엔트로피가 항상 증가해야 하는가?”라는 질문에서 들어가야 이해가 된다.
이건 난이도 문제가 아니라 인지 구조 문제다. 같은 내용, 같은 수준인데 진입 방식이 다르다. 기존 AI 학습 도구는 이 차이를 못 본다.
세션마다 몇 가지 이해 패턴을 짧게 기록한다
여기서 기록하는 건 시험 성적이 아니다. 공부한 시간도 아니다. 내가 공학이라는 전문분야를 어떤 인지 구조로 이해하려 하는가를 기록하고 있다.
세션 하나가 끝나면 아래 5가지만 남긴다. 짧게 남긴다.
- 시작 층위 — 새 개념을 만났을 때 어디서부터 들어가는가.
- 첫 이해 방식 — 식, 그림, 메커니즘, 사례 중 무엇으로 먼저 잡는가.
- 연결 방식 — 개념을 어떤 축으로 이어 붙이는가.
- 반복 끊김 — 어디서 자주 막히는가.
- 회복 방식 — 교정을 주면 어떤 포맷에서 가장 빨리 돌아오는가.
예를 들면 이런 식이다. 예를 들어 물리화학을 공부할 때, 나는 에너지 층위에서 진입해서 식으로 먼저 잡으려 하고, 부호 조건에서 자주 헷갈리고, 원리를 한 문장으로 다시 말해보게 하면 가장 빨리 회복된다. 이런 패턴을 짧게 기록한다.
5단계 학습 루프
이 기록은 공부 방법론과도 연결된다. 내가 쓰는 학습 루프는 5단계다.
- 압축 — 현재 범위를 핵심 개념 몇 개와 핵심 식 몇 개로 줄인다.
- 의미 확인 — 각 식과 개념을 “정의 / 조건 / 물리적 의미”로 다시 말해본다. 막히면 외운 거지 이해한 게 아니다.
- 닫힌 책 회상 — 자료를 닫고 바로 적거나 말한다.
- 빠른 검증 — 단위, 부호, 조건을 짧게 확인한다.
- 즉시 패치 — 오답을 길게 반성하지 않고 바로 고친다.
세션이 끝나면 남기는 건 딱 세 가지다. 오늘 배운 구조 1개, 오늘 헷갈린 지점 1개, 다음에 먼저 볼 cheap check 1개. 이 이상은 안 남긴다. 예쁜 노트를 만드는 게 공부가 아니기 때문이다.
전공 선택도 세계관의 결과였다
여기서 재미있는 건, 내 세계관축이 공부 방식에도 드러난다는 점이다.
나는 고등학생 때부터 “사람들이 착하게 살아도 지구환경이 망가지면 끝 아닌가”라고 생각했다. 환경 문제를 도덕 문제가 아니라 기술 기반 문제로 읽었다. 그래서 “가장 아래층 소재를 바꾸는 게 노력 대비 영향력이 크다”고 판단해서 공학을 선택했다.
이건 전공을 공부해서 그렇게 된 게 아니다. 원래 기반층을 먼저 보는 세계관이 있었고, 그 결과 전공을 선택한 것이다. 인과 방향이 반대다.
그리고 지금 AI 도구를 볼 때도, 미래산업을 분석할 때도, PERSONA 시스템을 설계할 때도 같은 패턴이 나온다. 표면 기능보다 아래층 구조와 병목을 먼저 본다. 물리화학을 공부할 때도 “이 식은 뭘 정의하는가, 뭘 근사하는가”를 먼저 묻는다. 이 반복되는 진입 패턴 자체가 세계관축의 evidence다.
다만 이걸 “전공자니까 맞다”로 승격하지는 않는다. 학습 방식에서 보이는 반복 패턴은 학습 전용 projection에서 관찰할 뿐, master persona로 바로 올리지 않는다.
실패 패턴이 쌓이면 공부법 자체가 바뀐다
이 시스템은 정적인 공부법이 아니다. 기록된 패턴에 따라 공부 방법 자체가 바뀐다.
- 의미 설명에서 자주 막히면 → 설명형 질문 비중을 늘린다
- 식 회상이 약하면 → equation sheet와 회상 드릴 비중을 늘린다
- 그래프 해석이 자주 틀리면 → graph-reading note와 시각 자료 렌더링 비중을 늘린다
- 부호/조건 실수가 반복되면 → cheap check 리스트를 세션 시작에 먼저 본다
- 기록 때문에 속도가 떨어지면 → 세션 메모를 3줄 규칙으로 다시 줄인다
마지막 규칙이 중요하다. 기록이 학습 속도를 떨어뜨리면 기록을 줄인다. 이 시스템은 “기록을 줄이는 공부법”이 아니라 “기록의 위치를 바꾸는 공부법”이다. 프롬프트 원문은 저장하지 않지만, 이해 구조와 반복 오류는 더 선명하게 남긴다.
학생마다 다른 교과서를 만들 수 있다
이런 식으로 데이터가 쌓이면 무엇이 가능해지는가.
- 같은 진입 층위가 반복되면 → 이 학생의 기본 시작점을 알게 된다
- 같은 이해 방식이 반복되면 → 이 학생에게 가장 잘 맞는 설명 포맷을 알게 된다
- 같은 연결 축이 반복되면 → 이 학생이 지식을 조직하는 방식을 알게 된다
- 같은 끊김이 반복되면 → 공부법 수정의 최우선 대상을 알게 된다
- 같은 회복 방식이 반복되면 → 이 학생에게 맞는 교정 포맷을 알게 된다
장기적으로는, 학생마다 다른 이해 구조에 맞는 개인 교과서, 개인 학습지, 개인 개념 지도를 만드는 방향으로 갈 수 있다. “어떤 문제를 더 풀어야 하나”가 아니라, “이 학생에게는 열역학을 에너지 보존에서 시작하는 게 나은가, 엔트로피에서 시작하는 게 나은가”를 설계할 수 있게 된다.
지금 나는 그 가능성을 내 자신을 실험 대상으로 삼아 first-party로 시험하고 있다. 현재 물리화학 3개 챕터에 적용했고, 앞으로 전자재료, 재료열역학, 공학수학에도 같은 운영을 확장할 예정이다.
아직 실험 중이다 — 해석 금지 규칙
다만 몇 가지 선을 분명히 해야 한다.
이건 구축 중인 first-party experiment다. 아직 세션 수가 적고, 교차 과목 검증도 시작 단계다.
해석 금지 규칙도 있다.
- 단일 세션 하나로 인지 구조를 확정하지 않는다
- 피곤한 날의 실패를 성격으로 승격하지 않는다
- 특정 과목의 일시적 병목을 전체 인지 능력으로 일반화하지 않는다
- 이 데이터만으로 master PERSONA를 바꾸지 않는다
같은 사람이 물리화학, 재료열역학, 전자재료에서 비슷한 진입/연결 패턴을 보이는지 교차 검토할 때까지는, 반복 패턴이 나와도 즉시 핵심 persona로 올리지 않고 학습 전용 projection에서 먼저 보정한다.
관련 글: 미래 산업의 현장에서 AI가 할 수 있는 것도 이 관점에서 읽으면 새로운 시각이 보인다.
최종 목표: 99% 정확도의 판단 아바타
이 프로젝트의 장기 목표를 먼저 말하겠다.
PERSONA의 최종 목표는 advisory shadow가 아니다. 최종판단까지 99% 수준으로 나와 같은 방향을 내리는 아바타를 만드는 것이다.
결제와 타인에게 영향이 가는 극소수 판단만 인간 승인으로 남기고, 나머지는 PERSONA가 대신한다. 지금 AI 업계가 모든 것을 자동화하려고 확장하고 있지만, 그 자동화에는 마지막 관문이 있다. “이 사람이라면 어떻게 판단했을까.” 내가 만드는 건 그 관문이다.
그리고 이 목표를 향해 지금 돌리고 있는 핵심 메커니즘이 하나 있다.
다음 프롬프트 예측은 문장 맞히기가 아니다. 실제 사용 과정에서 예측과 차이를 계속 비교하며 보정하는 calibration loop다.
시스템이 맥락을 읽고 다음 요청의 방향을 먼저 예측한다. 실제 프롬프트가 들어오면 예측과 비교하고, 차이를 보정 재료로 축적한다. 이 루프가 돌수록 시스템이 사용자의 다음 판단을 더 정확하게 읽게 된다.
지금은 아직 building 상태다
위에 쓴 건 최종 목표: 99% 정확도의 판단 아바타이다. 지금 있는 곳은 아니다.
현재 시스템의 상태를 솔직히 말하면 이렇다.
- 판단축: 아직 building 단계
- 성격축: 점수 미부여
- 세계관축: shadow-only, 비교 실험용
- 전체 상태: building
- 실전 사용: blocked — 별도 검증 게이트를 통과해야 열린다
지금 이 시스템은 내 판단을 대체하지 않는다. shadow 모드에서 내 판단과 비교하고, 차이가 나는 지점을 기록하고, 구조를 보정하는 단계다.
이 프로젝트는 논문 수준의 주장 관리도 같이 돌리고 있다. 모든 주장을 “지금 쓸 수 있는 것”과 “아직 쓰면 안 되는 것”으로 나눠서 관리한다.
- “판단축과 말투를 분리한 구조가 단순 스타일 복제보다 안전하다” → 가설. 구조적 우위는 보였지만 안전성 검증이 아직 부족하다.
- “이 구조가 문제정의와 다음 요청 선택까지 복제할 수 있다” → 비전. 현재는 비전이지 검증된 결과가 아니다.
- “append-only 로그 구조가 감사 가능한 연구 대상을 만든다” → 부분 지지. 추적 가능성은 강하지만 외부 재현은 아직이다.
“하고 싶은 말”과 “입증 책임이 있는 문장”을 섞지 않는 것이 이 프로젝트의 원칙이다.
이 시스템이 위험해지는 지점
이 시스템은 심리 진단 도구가 아니다. 누군가를 임상적으로 해석하거나, 치료를 대체하거나, “마음을 읽는다”고 말하는 시스템이 아니다. 판단과 해석의 구조를 장기적으로 기록하고 모델링하는 methods-heavy prototype이다.
그리고 이 시스템이 문제정의와 다음 요청 생성까지 복제하기 시작한다면, 기존의 “인간이 최종판단을 가진다”는 운영 규범을 직접 압박하게 된다. 그래서 이 프로젝트는 기능 확장보다 안전 질문을 먼저 다룬다. “이게 되면 뭐가 좋아지는가”보다 “이게 되면 뭐가 위험해지는가”를 먼저 물어야 한다고 본다.
persona를 자동으로 수집하는 것과 자동으로 승격하는 것도 다르다. 말버릇이나 반복 행동은 자동으로 모아도 된다. 하지만 “이 사람의 핵심 가치관이 이것이다”라고 올리는 건, 반드시 본인이 확인해야 한다. 자동 수집과 자동 승격을 혼동하는 순간, AI가 당신을 잘못 이해한 채로 잘못된 판단을 내리게 된다.
지금 바로 할 수 있는 한 가지
여기까지 읽고 “그래서 나는 뭘 하면 되는데?”라고 생각할 것이다.
하나만 하면 된다.
프로젝트를 시작할 때마다 log.md를 하나 만들고, AI에게 보낸 프롬프트를 원문 그대로 남겨라.
출력은 짧게 요약해도 된다. “이런 결과가 나왔다” 한 줄이면 충분하다. 하지만 입력 프롬프트는 그대로 복사해서 넣어라.
당신의 프롬프트에는 당신의 우선순위, 사고방식, 표현 습관, 문제 해결 순서가 다 들어 있다. 이게 쌓이면 나중에 AI가 당신을 이해하는 재료가 된다.
AI가 당신을 이해하게 만드는 첫 번째 단계는, 당신이 당신을 기록하는 것이다.
이 글의 내용은 현재 구축 중인 PERSONA 시스템에서 나온 것입니다. 시스템은 building 상태이며, 모든 판단 보조 결과는 사람의 최종 확인을 거칩니다.
자주 묻는 질문 (FAQ)
Q. PERSONA 시스템은 MBTI나 성격 유형 테스트와 뭐가 다른가요?
MBTI는 고정된 유형 분류입니다. PERSONA는 판단축·성격축·세계관축 3축으로 나눠서 기록하되, 시간에 따라 변하는 것까지 추적합니다. “이 사람은 INTJ다”로 끝나는 게 아니라, “이 상황에서 이 사람은 어떤 순서로 판단하고, 어디서 멈추는가”를 기록합니다.
Q. log.md를 시작하려면 어떤 형식이 필요한가요?
형식은 중요하지 않습니다. 날짜와 함께 AI에게 보낸 프롬프트 원문을 그대로 붙여넣으면 됩니다. 출력은 한 줄 요약이면 충분합니다. 중요한 건 입력 원문이 남아 있는 것입니다. 나중에 로그가 커지면 그때 retrieval 구조를 설계하면 됩니다.
Q. 이 시스템이 완성되면 AI가 자동으로 판단을 대신 내려주나요?
완성되면 맡길 수 있습니다. 이 프로젝트의 최종 목표는 99% 정확도로 나와 똑같은 판단을 내리는 아바타를 만드는 것입니다. 결제와 타인에게 영향이 가는 극소수 판단만 인간 승인으로 남기고, 나머지 판단은 PERSONA가 대신합니다. 지금 AI 업계가 모든 것을 자동화하려고 확장하고 있지만, 그 자동화의 마지막 관문은 “이 사람이라면 어떻게 판단했을까”입니다. 이 시스템은 그 관문을 만드는 프로젝트입니다.
저자: VibeCoding Tailor (Lovable 공식 앰배서더)
참고 자료
- Generative Agents: Interactive Simulacra of Human Behavior (Stanford/Google, 2023) — AI 에이전트가 사람처럼 행동하는 시뮬레이션 연구
- 미래 산업의 현장에서 AI가 할 수 있는 것 — shuntailor.net
- 배터리가 미래 인프라의 핵심인 이유 — shuntailor.net



