시리즈 최종편을 읽기 전에
이 글을 최대한 깊이 이해하려면 1~5편을 먼저 읽는 것이 좋습니다. 하지만 시간이 없다면, 각 편의 “가장 중요한 한 문장”만이라도 기억해 두세요.
- 1편: “미래산업은 AI·로봇·에너지가 같은 전력망과 공장에서 만나는 연결 산업이다”
- 2편: “AI 산업은 모델 랭킹이 아니라 R&D→인프라→추론비용→배포→운영→거버넌스의 6층 스택이다”
- 3편: “휴머노이드는 466만 대 설치 기반 위의 다음 층이지, 독립 시장이 아니다”
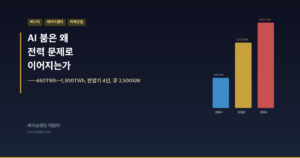
- 4편: “AI 확장의 진짜 속도 제한은 모델보다 변압기 4년과 큐 2,500GW에서 먼저 나타난다”
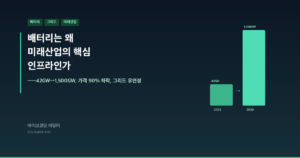
- 5편: “배터리는 EV 부품이 아니라 전력망의 시간 이동 장치(그리드 인프라)다”
이 5문장을 머릿속에 넣고 이 글(6편)을 읽으면, 세 축이 공장에서 만나는 구조가 훨씬 선명하게 보입니다.
이 글은 미래산업 시리즈의 마지막 편입니다. 1편에서 AI·로봇·에너지의 3축 구조를, 2편에서 AI 산업의 6층 스택을, 3편에서 휴머노이드의 상용화 병목을, 4편에서 전력 인프라의 시간 미스매치를, 5편에서 배터리의 그리드 역할을 봤습니다.
이번 글에서는 질문을 하나로 좁힙니다. “이 모든 축이 실제로 만나는 물리적 장소는 어디인가?”
정답은 공장과 전력망입니다. 앱 화면도, 모델 데모도, 투자 발표도 아닙니다. 배터리를 만드는 공장, 반도체를 찍는 팹, 데이터센터를 돌리는 전력 설비——이 물리 공간에서 AI, 로봇, 에너지가 실제로 만나고, 서로를 제약하고, 서로를 밀어 올립니다.
먼저 쉽게: 미래산업을 요리에 비유하면
미래산업을 처음 접하는 분을 위해 비유로 시작합니다.
레스토랑을 연다고 생각해 보세요. 좋은 레시피(AI 모델)가 있고, 훌륭한 조리 도구(로봇)가 있습니다. 하지만 주방에 가스(전력)가 안 들어오면 요리를 할 수 없습니다. 가스가 들어와도 주방(공장)이 없으면 손님에게 음식을 낼 수 없습니다.
미래산업도 같습니다. AI가 아무리 똑똑해도, 그 AI를 돌리는 데이터센터에 전기가 안 들어오면 서비스가 안 됩니다. 로봇이 아무리 좋아도, 공장에 자리가 없으면 만들 수 없습니다. 배터리가 아무리 싸도, 배터리를 만드는 공장에 전력이 부족하면 생산이 안 됩니다.
그래서 미래산업의 진짜 현장은 주방, 즉 공장과 전력망입니다. 레시피(AI)와 도구(로봇)와 가스(에너지)가 모두 이 주방에서 만나야 비로소 산업이 됩니다.
왜 미래산업 뉴스에 공장 이야기가 자꾸 나오는가
이 시리즈를 따라온 독자라면 알겠지만, AI 뉴스를 깊이 따라가면 데이터센터 건설 기사가 나오고, 로봇 뉴스를 따라가면 자동차 공장 자동화 기사가 나오고, 에너지 뉴스를 따라가면 배터리 공장 전력 수요 기사가 나옵니다.
세 축의 뉴스가 결국 같은 곳으로 모입니다. 공장과 산업 설비입니다. 이것은 우연이 아닙니다.
배터리 공장, 반도체 팹, 데이터센터, 자동화 장비——이들은 모두 두 가지를 동시에 요구합니다.
- 대형 전력 부하: 소규모 도시 수준의 전기를 소비합니다
- 제조 능력: 정밀한 공정, 클린룸, 자동화 라인이 필요합니다
이 두 가지가 동시에 필요한 곳이 바로 공장입니다. 미래산업의 실제 결절점(node)은 앱 스토어가 아니라 이런 물리 설비가 모이는 제조 현장입니다.
숫자로 보기: 제조업은 세계 에너지의 얼마를 쓰는가
IEA에 따르면 산업(제조업 포함)은 전 세계 최종 에너지 소비의 37%를 차지합니다. 이 숫자의 의미를 풀어 봅니다.
세계에서 쓰는 에너지를 100이라고 하면, 그 중 37은 공장과 산업 설비가 쓴다는 뜻입니다.
왜 이렇게 큰가? 철을 녹이고, 시멘트를 굽고, 화학 반응을 일으키고, 제품을 조립하는 과정이 모두 에너지를 씁니다. 주택에서는 에어컨과 조명이 전기를 쓰지만, 공장에서는 용광로와 전기로가 전기를 씁니다. 규모가 다릅니다. 주택(약 21%)보다도, 교통(약 26%)보다도 큽니다. 가장 큰 단일 소비자가 산업입니다.
쉬운 비유: 가정에서 전기를 가장 많이 쓰는 기기가 에어컨이라면, 산업에서 전기를 가장 많이 쓰는 “기기”는 공장 전체입니다. 에어컨 하나가 2~3kW인 반면, 배터리 공장 하나가 수십~수백 MW입니다. 수만 배 차이입니다.
그리고 이 비중은 전기화가 진행될수록 커집니다. IEA의 정책 방향에 따르면, 산업에서 전기가 차지하는 비율은 2022년 23%에서 2030년 30%로 올라가야 합니다.
“7%포인트면 별로 안 크지 않나?”라고 생각할 수 있습니다.
왜 7%포인트가 “별로 안 크지 않은” 게 아닌지 계산해 봅니다. 전 세계 최종 에너지 소비가 약 400EJ(엑사줄)입니다. 산업이 37%니까 약 148EJ. 여기서 전기 비율이 23%→30%로 오르면, 전기로 바뀌는 에너지가 148EJ × 7% ≈ 10.4EJ입니다. 이걸 TWh로 바꾸면 약 2,900TWh. 현재 전 세계 전체 전력 생산이 약 29,000TWh이니까, 산업 전기화만으로 전 세계 전력 수요의 약 10%가 추가되는 겁니다.
이 규모는 4편에서 봤던 데이터센터 전력(460→1,300TWh)과 맞먹거나 더 큽니다. 산업 전체 에너지의 37%라는 거대한 파이에서 전기 비율이 7%포인트 오른다는 건, 전력 수요가 수백~수천 TWh 단위로 늘어난다는 뜻입니다. 4편에서 봤던 데이터센터 전력(460→1,300TWh)과 맞먹는 규모의 변화가 제조업에서도 일어나고 있습니다.
특히 중요한 숫자: 신에너지 제품 제조
IEA Electricity 2025에 따르면, 중국에서 “신에너지 제품”(배터리, 태양광 모듈, EV, 관련 소재) 제조에 사용되는 전력만 연간 300TWh를 넘습니다. 이 숫자는 중국 산업 전력 성장의 약 50%를 차지합니다.
무슨 뜻인가. 중국 공장이 더 많은 전기를 쓰게 된 이유의 절반이 “배터리·태양광·전기차를 만드는 공장”이라는 겁니다. 미래산업의 제품(배터리)을 만드는 공장이 미래산업의 인프라(전력)를 대량으로 소비하는 순환 구조입니다.
제조업 에너지의 세 가지 구조적 변화
이 세 가지가 같은 전력망에서 경쟁합니다. 변압기 하나를 배터리 공장이 쓰면 데이터센터는 기다려야 합니다.
공장에서 세 축이 만나는 5가지 메커니즘
이제 “공장이 교차점이다”라는 말이 구체적으로 무엇을 뜻하는지, 5가지 메커니즘으로 분해합니다.
메커니즘 1: 같은 전력망을 놓고 경쟁한다
배터리 공장, 반도체 팹, 데이터센터가 같은 지역에 들어서면, 세 시설이 같은 전력망에 부하를 겁니다.
4편의 숫자를 다시 봅니다. 변압기 리드타임은 최대 4년, 인터커넥션 큐에는 2,500GW가 대기 중입니다. 이 장비와 연결 용량은 유한합니다. 배터리 공장이 변압기 하나를 가져가면, 같은 지역의 데이터센터는 다음 변압기를 기다려야 합니다.
쉬운 비유: 한 동네에 대형 식당 세 곳이 동시에 열린다고 생각하세요. 가스관이 하나인데 세 곳이 다 써야 합니다. 누가 먼저 연결되느냐가 누가 먼저 장사를 시작하느냐를 결정합니다.
메커니즘 2: 자동화가 전력 소비 패턴을 결정한다
3편에서 봤듯이, 전 세계 산업용 로봇 가동 대수는 428만 대(IFR 2024)입니다. 이 로봇들은 공장에서 용접, 조립, 검사, 자재 이송을 합니다.
로봇 가동 스케줄이 전력 프로파일을 만드는 메커니즘:
- 1교대(주간만): 오전 8시에 전력 급상승, 오후 6시에 급하락. 하루에 피크가 1번.
- 2교대(주간+야간): 교대 시간(오후 6시, 오전 6시)에 전력이 잠깐 빠졌다가 다시 오름. 하루에 피크가 2번.
- 3교대(24시간): 반도체 팹처럼 24시간 풀가동. 전력이 거의 일정하지만, 장비 유지보수 시간에 살짝 빠짐. 기저 부하 형태.
이 전력 프로파일에 따라 5편에서 본 배터리 저장의 역할이 달라집니다. 1교대 공장에서는 퇴근 후 남는 전력을 충전→다음 날 출근 시 방전. 3교대 공장에서는 외부 전력 피크 시간에 방전→비피크 시간에 충전. 로봇의 가동 패턴(3편) → 전력 소비 패턴(4편) → 배터리 완충 패턴(5편)이 한 공장 안에서 연결되는 구조입니다.
여기서 중요한 점: 로봇의 가동 패턴이 곧 공장의 전력 소비 패턴입니다. 로봇이 동시에 풀가동하면 전력 피크가 생기고, 교대 시간에는 전력이 빠집니다. 이 피크와 골짜기를 관리하는 데 5편에서 본 배터리 저장이 들어옵니다.
쉬운 비유: 집에 에어컨 5대를 동시에 켜면 두꺼비집(차단기)이 내려갑니다. 공장에서 로봇 수백 대를 동시에 돌리면 같은 일이 전력망 차원에서 일어납니다. 배터리는 이 피크를 완충하는 역할을 합니다.
메커니즘 3: AI가 공장의 두뇌가 된다
2편에서 본 AI 산업 6층 스택의 ④배포·제품 층이 공장에서 어떻게 실현되는지, 구체적인 기술별로 봅니다.
공장에서 AI가 하는 4가지 일
- 공정 최적화: 수백 개의 공정 파라미터(온도, 압력, 속도, 시간)를 AI가 실시간으로 조율합니다. 사람이 한 번에 3~5개 변수를 관리하는 반면, AI는 수백 개를 동시에 최적화할 수 있습니다. 반도체 팹에서 수율 1% 차이가 수백억 원 매출 차이를 만들기 때문에, 공정 최적화 AI의 ROI가 매우 높습니다.
- 예측 정비(Predictive Maintenance): 로봇이나 기계의 진동, 소음, 온도 패턴을 AI가 분석해서 “이 장비가 2주 후에 고장날 확률이 높다”고 예측합니다. 고장 후 수리(reactive)보다 고장 전 교체(predictive)가 다운타임을 80% 이상 줄일 수 있습니다. 다운타임 1시간이 수천만 원의 손실인 공장에서 이 차이는 엄청납니다.
- 에너지 관리: 디지털 트윈(공장의 가상 복제본)이 공장 전체의 전력 사용을 시뮬레이션합니다. “지금 로봇 A 라인을 10% 감속하면 전력 피크를 15% 줄일 수 있고, 생산량 감소는 3%에 그친다”같은 실시간 최적화를 합니다. 이것이 메커니즘 2(자동화=전력 패턴)에서 설명한 “AI가 로봇과 에너지를 동시에 조율하는” 구체적 방법입니다.
- 품질 검사: 컴퓨터 비전(CV)이 카메라로 제품을 촬영하고, AI가 밀리초 단위로 불량 여부를 판단합니다. 사람 검사원은 피로로 집중력이 떨어지지만, AI는 24시간 동일한 정확도를 유지합니다. 검사 속도도 사람의 10~100배입니다. 단, 새로운 불량 유형이 나타나면 학습 데이터를 업데이트해야 하므로 완전 무인은 아닙니다.
이 AI 기능을 돌리려면 컴퓨팅 자원이 필요하고, 그 컴퓨팅 자원은 전력을 씁니다. 공장 안에서도 AI→전력→에너지 연결이 반복됩니다.
메커니즘 4: 배터리는 제품이면서 동시에 공장의 인프라다
5편에서 본 순환 구조를 공장 차원에서 다시 봅니다.
배터리 기가팩토리는 배터리를 만드는 공장입니다. 그런데 이 공장 자체가 대형 전력 소비자입니다. 피크 전력을 관리하기 위해 공장 옆에 배터리 저장 시설을 둡니다. 즉, 배터리 공장이 만드는 제품(배터리)이 그 공장의 전력 인프라(배터리 저장)로도 쓰입니다.
이 순환 구조가 미래산업의 특징입니다. 제품과 인프라의 경계가 흐려지는 겁니다.
쉬운 비유: 빵집이 밀가루를 만드는 공장을 운영하는데, 그 밀가루 공장의 전력을 빵집의 태양광 패널이 공급하는 것과 비슷합니다. 만드는 것과 돌리는 것이 서로 물려 있습니다.
메커니즘 5: 작업셀(work cell) 경제학이 모든 판단의 기준이다
3편에서 휴머노이드의 ROI가 “고정 작업셀에서 기존 방법 대비 얼마나 나은가”로 판단된다고 했습니다. 이 원리는 공장의 모든 투자 결정에 적용됩니다.
작업셀이란, 공장에서 하나의 작업을 수행하는 최소 단위입니다. 예를 들어 “부품 A를 잡아서 조립 위치 B에 놓는” 작업을 하나의 셀이 담당합니다.
이 셀의 경제학은 다음으로 판단됩니다:
| 판단 기준 | 의미 | 쉬운 비유 |
|---|---|---|
| 통합 시간 | 새 장비를 기존 라인에 붙이는 데 걸리는 시간 | 새 가전제품을 집에 설치하는 시간 |
| 사이클 타임 | 작업 1회에 걸리는 시간. 기존보다 느리면 도입 이유 없음 | 한 그릇 만드는 시간 |
| 유지보수 비용 | 연간 수리·교체·점검 비용. 총소유비용(TCO)의 핵심 | 자동차 유지비 |
| 에너지 소비 | 셀 하나가 쓰는 전력. 전체 공장 전력 프로파일에 영향 | 가전제품 전기 요금 |
| 안전 인증 | 사람과 같이 일하려면 규격 통과 필수. 미달이면 배치 불가 | 식품 위생 허가 |
| 전환 비용 | 다른 제품으로 바꿀 때 걸리는 시간과 비용 | 메뉴를 바꿀 때 주방 재배치 비용 |
ABB 같은 로봇 기업이 셀 경제성을 말할 때 쓰는 언어가 바로 이겁니다. “통합 시간, 전환 비용, 멀티 사이트 확장성, 지원 시스템.” 제품 데모의 화려함이 아닙니다.
개발자와 엔지니어가 이 시리즈에서 가져갈 수 있는 핵심 통찰
소프트웨어 세계에서 일하는 개발자가 미래산업을 읽을 때 놓치기 쉬운 구조적 차이 5가지입니다.
- 스케일링 시간 척도가 근본적으로 다릅니다. 클라우드에서 서버를 추가하는 건 분~시간입니다(auto-scaling). 하지만 물리 인프라에서 변압기를 추가하는 건 최대 4년, 전력망을 증설하는 건 5~15년입니다. 소프트웨어의 ‘scale-up’과 하드웨어의 ‘scale-up’은 같은 단어지만 시간 척도가 1000배 이상 다릅니다.
- 배포(deployment) 비용 구조가 다릅니다. 소프트웨어에서 배포는 코드를 서버에 올리는 것(CI/CD, 수분~수시간)입니다. 제조업에서 배포는 장비를 공장에 설치하고(수주), 기존 라인에 통합하고(수주~수개월), 안전 인증을 받고(수개월), 작업자를 교육하는 것(수주)입니다. 소프트웨어의 ‘git push → production’에 해당하는 것이 제조업에서는 ‘발주 → 설치 → 통합 → 인증 → 교육 → 가동’이고, 이 과정이 수개월~수년 걸립니다.
- 리소스 경쟁이 물리적입니다. 마이크로서비스에서 CPU/메모리 contention을 아는 개발자라면, 전력망의 변압기 용량 경쟁은 같은 구조의 물리 세계 버전입니다. 다만 소프트웨어에서는 리소스를 동적으로 재배치할 수 있지만(Kubernetes 스케줄러), 전력에서는 변압기를 동적으로 이동할 수 없습니다. 200톤짜리 장비를 실시간으로 옮길 수는 없습니다.
- failover가 없습니다. 소프트웨어에서 서버가 죽으면 다른 서버로 트래픽을 넘깁니다(failover). 대형 변압기가 고장나면? 같은 사양의 여분이 없습니다. 교체에 2~4년 걸립니다. 물리 인프라에는 ‘hot standby’가 경제적으로 불가능한 경우가 많습니다.
- 제본스 역설이 물리 세계에서도 작동합니다. 소프트웨어에서 비용 최적화가 사용량 증가를 부르는 건 익숙합니다(무료 API tier → 사용량 폭발). 미래산업에서도 같습니다. 추론 비용 280배 하락 → AI 사용량 폭발 → 전력 수요 급증. 배터리 가격 90% 하락 → ESS 설치 폭발 → 배터리 공장 전력 수요 급증. ‘좋은 소식이 새 문제를 만드는’ 이 구조는 소프트웨어와 물리 세계 양쪽에서 반복됩니다.
이 5가지를 이해하면, 소프트웨어 경험으로 미래산업을 읽을 때 “왜 이렇게 느린가?”라는 답답함이 “물리 세계의 시간 척도가 다르구나”라는 구조적 이해로 바뀝니다.
이것이 3편에서 말한 “데모 경제 vs 현장 경제의 간극”의 구체적 실체입니다.
왜 이 간극이 좁혀지기 어려운가. 소프트웨어에서는 제품을 만들고(개발) → 바로 배포(deploy) → 바로 피드백(monitoring) → 바로 개선(iteration)하는 사이클이 수일~수주입니다. 하지만 제조업에서는:
- 장비 선택 → 발주 → 납품: 수개월~수년
- 설치 → 기존 라인 통합 → 시운전: 수주~수개월
- 안전 인증 → 작업자 교육 → 본가동: 수주~수개월
- 피드백 → 사양 변경 → 재발주: 다시 수개월
한 사이클이 수개월~수년입니다. 소프트웨어의 “weekly sprint”가 제조업에서는 “yearly cycle”에 가깝습니다. 이 시간 척도의 차이가 “데모는 빠르지만 상용화는 느린” 간극의 구조적 원인입니다. 데모(prototype)를 보여주는 건 소프트웨어 속도로 가능하지만, 상용화(production)는 제조업 속도로 진행됩니다.
개발자와 엔지니어가 놓치기 쉬운 포인트: 소프트웨어에서 “배포”는 코드를 서버에 올리는 것(수분~수시간)입니다. 하지만 제조업에서 “배포”는 장비를 공장에 설치하고, 기존 라인에 통합하고, 안전 인증을 받고, 작업자를 교육하는 것(수주~수개월)입니다. 소프트웨어의 CI/CD(지속적 배포)에 익숙한 개발자일수록, 물리 세계의 “배포 비용”을 과소평가합니다. 통합 시간(integration time)이 소프트웨어의 배포 시간과 근본적으로 다른 시간 척도라는 점을 이해하면, 미래산업의 속도를 훨씬 정확하게 읽을 수 있습니다.
공장에서 세 축이 만나는 5가지 메커니즘
대표 장면: 배터리 기가팩토리의 하루를 따라가기
추상적 설명이 아니라 하루 단위로 구체적으로 봅니다.
Before (공장이 없을 때의 미래산업):
투자 발표가 나옵니다. “○○ 기업이 배터리 공장에 5조 원을 투자한다.” 뉴스가 나오고, 주가가 오르고, 분석가가 TAM(시장 규모)을 계산합니다. 이게 미래산업의 전부처럼 보입니다.
전환점 (공장을 짓기 시작하면):
현실이 들어옵니다.
- 전력: 이 공장은 하루 수십 MW의 전력을 씁니다. 전력망 연결을 신청했지만, 인터커넥션 큐에 이미 수십 개의 대형 프로젝트가 대기 중입니다. 변압기가 4년 걸립니다. 공장 건물은 2년에 지었는데, 전기 연결이 3년째 안 됩니다.
- 자동화: 공장 안에 산업용 로봇 300대를 배치합니다. 셀 조립, 전극 코팅 검사, 자재 운반. 이 로봇들이 동시에 돌아가면 전력 피크가 치솟습니다. 피크를 완충하기 위해 공장 옆에 50MWh 배터리 저장 시설을 같이 짓습니다.
- AI: 생산 라인에 AI 기반 품질 검사와 공정 최적화가 들어갑니다. 이 AI를 돌리는 서버도 전력을 씁니다. 디지털 트윈으로 공장 전체의 에너지 사용을 시뮬레이션하고, 로봇 가동 스케줄과 전력 피크를 실시간으로 조율합니다.
After (공장이 돌아가기 시작하면):
이 공장에서 만들어진 배터리가 다른 곳의 데이터센터 옆에 설치됩니다. 그 데이터센터는 AI 모델을 돌리고, 그 AI는 또 다른 공장의 공정을 최적화합니다. 순환이 시작됩니다.
처음에 “5조 원 투자”라는 한 줄 뉴스였던 것이, 실제로는 전력망 연결(4년), 변압기 조달, 로봇 300대 배치, AI 시스템 구축, 배터리 저장 설비, 안전 인증——이 모든 것이 동시에 움직여야 돌아가는 복합 시스템이었습니다.
이것이 “투자 발표 ≠ 실제 가동”이라는 4편의 메커니즘이 공장이라는 물리 공간에서 실현되는 장면입니다.
정책 수준에서 확인되는 구조
이 교차 구조가 단지 위키의 해석이 아니라 실제로 정책에서도 확인되는 점을 짚습니다.
- FERC Order 2023 (미국): 인터커넥션 절차 자체를 독립적인 주요 규제 명령으로 다룸. “전력 연결이 곧 산업 속도를 결정한다”는 구조가 정책으로 확정된 것
- DOE GDO TRAC Program (미국): 변압기 회복력과 첨단 전력 부품을 명시적으로 공급망 정책 대상으로 지정. “전력 장비가 산업 병목”이라는 인식이 정부 프로그램이 된 것
- IEA 전력망 현대화 프레임: Non-firm 연결, 동적 선로 정격, 동적 변압기 정격을 “시간을 버는 임시 조치”로 분류. 근본 해결(변압기·케이블 증설)은 여전히 수년이 걸린다는 전제
이 정책들의 공통점: “연결(connection)”과 “장비(equipment)”를 병목으로 지목합니다. 발전량이 아니라 전력을 보내는 인프라가 실제 산업 속도를 결정한다는 구조를 정부와 국제기구가 인정하고 있습니다.
한국 독자에게: 왜 이 구조가 한국에서 특히 중요한가
한국은 이 교차점의 모든 요소를 갖춘 나라입니다. 구체적으로 봅니다.
삼성전자 평택 캠퍼스
세계 최대 규모의 반도체 캠퍼스입니다. 메모리 반도체와 파운드리를 동시에 생산합니다. 이 캠퍼스의 전력 소비는 소도시 수준이고, 내부에는 수천 대의 자동화 장비가 돌아갑니다. 반도체(AI 인프라) + 전력 + 자동화가 한 장소에서 만나는 대표 사례입니다.
SK 배터리 공장 (서산·울산)
EV 배터리와 ESS(에너지 저장 시스템)를 만듭니다. 배터리 제조 자체가 대형 전력 부하이고, 완성된 배터리 중 일부는 공장의 피크 전력을 완충하는 데 쓰입니다. 5편의 순환 구조가 실제로 일어나는 현장입니다.
현대자동차 울산 공장
세계 최대 규모의 자동차 공장입니다. 로봇 밀도가 극히 높고, EV 전환으로 생산 라인이 재편되고 있습니다. 전기차를 만드는 공장의 전기 수요가 올라가고, 그 전기차에 들어가는 배터리를 다른 공장에서 만들고, 그 배터리 공장도 전기를 대량으로 씁니다.
이 세 공장이 같은 전력 인프라와 같은 산업 정책 안에서 움직입니다. 한국 독자가 반도체 기사, 배터리 기사, 자동차 기사를 따로 읽으면 각각의 뉴스가 됩니다. 하지만 이 6편의 프레임으로 같이 읽으면 하나의 산업 구조가 됩니다.
개발자와 엔지니어가 이 시리즈에서 가져갈 수 있는 핵심 통찰
소프트웨어 세계에서 일하는 개발자가 미래산업을 읽을 때 놓치기 쉬운 구조적 차이 5가지입니다.
- 스케일링 시간 척도가 근본적으로 다릅니다. 클라우드에서 서버 추가는 분~시간(auto-scaling). 변압기 추가는 최대 4년. 전력망 증설은 5~15년. 소프트웨어의 scale-up과 하드웨어의 scale-up은 같은 단어지만 시간 척도가 1000배 이상 다릅니다.
- 배포(deployment) 비용 구조가 다릅니다. 소프트웨어에서 배포는 git push → production (수분). 제조업에서 배포는 발주 → 설치 → 통합 → 인증 → 교육 → 가동 (수개월~수년). CI/CD에 익숙한 개발자일수록 물리 세계의 배포 비용을 과소평가합니다.
- 리소스 경쟁이 물리적입니다. Kubernetes에서 CPU/memory contention은 스케줄러가 동적으로 조정합니다. 전력망의 변압기 용량 경쟁은 같은 구조이지만, 200톤짜리 장비를 동적으로 재배치할 수 없습니다.
- failover가 없습니다. 서버가 죽으면 다른 서버로 failover. 대형 변압기가 고장나면? 같은 사양의 여분이 없고 교체에 2~4년. hot standby가 경제적으로 불가능합니다.
- 제본스 역설이 양쪽에서 작동합니다. 무료 API tier → 사용량 폭발은 익숙합니다. 추론 비용 280배↓ → AI 사용량 폭발 → 전력 수요 급증도 같은 구조입니다. 좋은 소식이 새 문제를 만드는 패턴은 소프트웨어와 물리 세계 양쪽에서 반복됩니다.
이 5가지를 이해하면, 소프트웨어 경험으로 미래산업을 읽을 때 “왜 이렇게 느린가”가 “물리 세계의 시간 척도가 다르구나”로 바뀝니다.
최종 개발자 통찰: SW 아키텍처의 monolith vs microservice 논쟁처럼, 미래산업도 AI·로봇·에너지를 microservice처럼 따로 보면 실제로는 monolith처럼 묶여 있는 물리 현실과 충돌합니다. 공장에서 세 축은 같은 전력, 같은 자동화 라인, 같은 AI를 공유합니다. 논리적으로는 microservice이지만 물리적으로는 monolith. 이것이 미래산업의 아키텍처입니다.
이 시리즈 전체를 관통하는 하나의 구조
6편을 관통하는 구조를 한 문단으로 정리합니다.
AI가 추론 비용 280배 하락으로 사용량이 폭발합니다(2편). 사용량이 폭발하면 데이터센터가 늘어나고, 데이터센터는 전력을 대량으로 소비합니다(460→1,300TWh, 4편). 그 전력을 보내는 변압기는 4년, 전력망 연결은 5~15년 걸립니다(4편). 이 간극을 배터리가 부분적으로 메우는데(42→1,500GW, 5편), 배터리를 만드는 공장도 전력을 대량 소비합니다(중국만 300+TWh). 공장 안에서는 466만 대의 로봇이 돌아가면서(3편) 전력 소비 패턴을 만들고, AI가 공정을 최적화합니다. 이 모든 것이 같은 전력망, 같은 산업단지, 같은 공장에서 만납니다(이 글).
이것이 “미래산업은 AI·로봇·에너지가 공장과 전력망에서 만나는 결합 구조”라는 한 문장의 풀어쓰기입니다. 6편이 이 한 문장을 숫자와 메커니즘으로 뒷받침한 것입니다.
시리즈 전체를 하나의 지도로
미래산업 시리즈 종합 지도
| # | 편 | 핵심 숫자 | 독자가 얻는 관점 | 핵심 메커니즘 |
|---|---|---|---|---|
| 1 | 입문 지도 | 빠른 층 vs 느린 층 | 3축을 같이 봐야 하는 이유 | 인체 비유: 두뇌(AI)+손발(로봇)+혈액(에너지) |
| 2 | AI 산업 스택 | $1,091억, 추론비용 280배↓, 도입률 78% | 모델 너머 6층을 동시에 보기 | |
| 3 | 휴머노이드 | 428만 대 가동, 밀도 1위 한국 1,012대 | 데모보다 설치 기반 + 셀 경제학 | 가전 비유: 세탁기(기존)→만능로봇(휴머노이드) |
| 4 | AI 전력 문제 | 460→1,300TWh, 변압기 4년, 큐 2,500GW | 투자 발표 ≠ 실제 가동 전력 | 수도관 비유: 발전(수도꼭지)은 빠르고 연결(수도관)은 느림 |
| 5 | 배터리 인프라 | 42GW→1,500GW, 가격 90%↓ | EV 부품 → 그리드 시스템 자산 | 물탱크 비유: 시간 이동 + 피크 완충 + 주파수 조절 |
| 6 | 제조업 교차점 (이 글) | 산업 에너지 37%, 전기화 23→30%, 신에너지 300+TWh | 공장이 세 축의 실제 전장 | 레스토랑 비유: 레시피(AI)+도구(로봇)+가스(에너지)=주방(공장) |
이 글에서 가장 중요한 한 문장
“미래산업의 실제 전장은 앱 화면보다 공장, 전력망, 자동화가 만나는 제조 현장이다.”
이 한 문장이 시리즈 6편의 결론입니다. 1~5편에서 각 축을 따로 봤고, 6편에서 세 축이 공장이라는 물리 공간에서 만나는 구조를 봤습니다. 이 문장을 기억해 두면, 앞으로 미래산업 뉴스를 읽을 때 “이 발표는 공장과 전력망에 어떤 영향을 주는가?”를 자연스럽게 확인하게 됩니다.
이 시리즈를 읽고 나서 해볼 것
내일 뉴스를 읽을 때, 아래 5가지 중 하나만 해 보세요.
- AI 기사를 보면 → “이 서비스의 데이터센터 전력은 확보됐나?” 확인
- 로봇 영상을 보면 → “이건 편집본인가, 연속 가동 데이터인가?” 확인
- 투자 기사를 보면 → “투자 발표일과 실제 가동일은 몇 년 차이인가?” 확인
- 배터리 기사를 보면 → “이건 EV용인가, 그리드 저장용인가?” 확인
- 공장 기사를 보면 → “이 공장의 전력은 어디서 오는가?” 확인
하나만 해 봐도 “같은 뉴스인데 보이는 것이 다르다”는 경험을 하게 됩니다. 그 경험이 이 시리즈가 제공하는 가장 실질적인 가치입니다.
시리즈를 마치며: 독자에게 남는 5가지 읽기 습관
이 시리즈 6편을 읽고 나면, 같은 뉴스를 읽어도 보이는 것이 달라집니다. 구체적으로 5가지 습관이 생깁니다.
- AI 뉴스를 읽을 때: 모델 성능(①R&D) 다음에 “이 모델을 돌리는 데이터센터의 전력은 확보됐나?”(②인프라), “추론 비용이 기업이 감당할 수준인가?”(③추론 경제학), “어떤 제품에 실제로 들어가나?”(④배포), “품질 유지는 어떻게?”(⑤운영), “규제에 걸리지 않나?”(⑥거버넌스)를 봅니다. 2편에서 배운 6층 체크리스트입니다
- 로봇 뉴스를 읽을 때: 데모 영상의 화려함보다 “기존 장비 대비 사이클 타임은?”, “유지보수 비용은?”, “안전 인증은 받았나?”를 봅니다 (3편)
- 에너지 뉴스를 읽을 때: 발전량(만드는 전기)보다 “변압기는 언제 도착하나?”(보내는 장비), “인터커넥션 큐에 몇 년 대기인가?”(연결 대기줄), “투자 발표와 실제 가동 사이의 간극은?”(capex≠energized). 4편에서 배운 “발전보다 연결이 병목” 프레임입니다
- 배터리 뉴스를 읽을 때: 셀 가격 다음에 “어디에 설치되나?”(EV vs 그리드 저장 vs 공장), “그리드에서 어떤 역할을 하나?”를 봅니다 (5편)
- 공장·제조업 뉴스를 읽을 때: 생산 능력 다음에 “전력은 확보됐나?”, “자동화 구조는?”, “배터리·반도체·데이터센터가 같은 전력망에서 경쟁하고 있지 않나?”를 봅니다 (이 글)
같은 뉴스를 다르게 읽는 구체 예시
| 뉴스 헤드라인 | 이전에 읽던 방식 | 이제 읽는 방식 |
|---|---|---|
| “GPT-5 출시” | 벤치마크 비교 | 추론 비용? DC 전력? 기업 도입? |
| “테슬라 Optimus 투입” | 로봇 시대! | 연속 가동? TCO? 안전 인증? |
| “MS DC 500억$ 투자” | AI 확장 가속 | 전력 연결 언제? 변압기? 큐? |
| “LG 배터리 가격↓” | EV 싸진다 | EV용? 그리드용? 설치 위치? |
| “삼성 평택 3기” | 생산 증가 | 전력? 변전소? 로봇 라인? AI 공정? |
이 다섯 가지 습관이 생기면, 개별 뉴스가 산업 구조로 연결돼서 읽힙니다.
이 다섯 가지 습관이 생기면, 개별 뉴스가 산업 구조로 연결돼서 읽힙니다.
이 변화의 실질적 가치: 미래산업 뉴스는 매일 나옵니다. 대부분의 독자는 “대단하다/별로다”로 5분에 소비합니다. 이 시리즈가 제공하는 것은 “이 발표가 실제로 언제 산업이 되는가?”를 15분 안에 구조적으로 판단하는 프레임입니다.
- 투자자에게: “투자 발표 ≠ 실제 가동”의 타이밍 간극을 읽는 눈
- 개발자에게: 소프트웨어 scale-up과 물리 scale-up의 시간 척도 차이 이해
- 학생에게: “어떤 산업을 공부해야 하나”의 지도
- 정책 관계자에게: AI·로봇·에너지가 같은 전력망에서 만나는 교차 구조
그것이 이 시리즈의 목표였습니다.
이 글의 핵심 통찰 정리
이 글(6편, 시리즈 최종편)에서 가장 중요한 3가지.
- “공장이 세 축의 교차점”이라는 공간적 발견. AI(데이터센터), 로봇(자동화), 에너지(전력·배터리)가 추상적으로 연결되는 게 아니라, 같은 변전소, 같은 산업단지, 같은 공장에서 물리적으로 만납니다. 삼성 평택, SK 서산, 현대 울산이 그 교차점입니다.
- “셀 경제학”이라는 판단 기준. 어떤 기술이든 공장에 들어가려면 기존 작업셀의 비용(통합 시간, 사이클 타임, 유지보수, 에너지, 안전)보다 나아야 합니다. 데모의 화려함이 아니라 셀 단위의 경제성이 실제 채택을 결정합니다.
- “소프트웨어와 물리의 시간 척도 차이.” auto-scaling은 분 단위, 변압기는 년 단위. git push는 분 단위, 공장 통합은 월 단위. failover는 초 단위, 변압기 교체는 년 단위. 이 시간 척도의 차이를 이해하면, “왜 미래산업이 이렇게 느린가”가 “물리 세계의 시간이 다르구나”로 바뀝니다.
반론과 한계
“모든 미래산업이 제조업을 경유하는 건 아니지 않나?”——맞습니다. 소프트웨어 서비스, 콘텐츠, 금융 같은 분야는 공장 없이도 성장합니다. 모든 미래산업이 같은 속도로 전기화나 자동화를 겪는 것도 아닙니다.
“소프트웨어만으로 성장하는 산업도 있지 않나?”
맞습니다. SaaS, 게임, 콘텐츠, 핀테크——공장 없이 성장하는 산업이 많습니다. 이 글은 “모든 산업이 공장을 필요로 한다”고 말하는 게 아닙니다.
하지만 이 시리즈에서 다루는 미래산업——AI 인프라, 로봇, 에너지 전환——은 소프트웨어만으로 완성되지 않는 산업입니다. AI 모델(소프트웨어)은 데이터센터(물리)에서 돌아가고, 로봇(물리)이 공장(물리)에서 움직이고, 배터리(물리)가 전력망(물리)에 연결됩니다. 이 세 축에서 소프트웨어는 “두뇌”이지만, 두뇌만으로는 몸이 움직이지 않습니다.
소프트웨어 산업의 성장 속도에 익숙한 개발자일수록, 이 물리 층의 시간 척도(변압기 4년, 공장 건설 2~3년, 전력망 5~15년)를 과소평가하기 쉽습니다. 이 시리즈의 핵심 가치 중 하나가 바로 이 “시간 척도의 차이”를 구조적으로 이해하게 만드는 것입니다.
하지만 AI 인프라(데이터센터), 로봇 산업(자동화 장비), 에너지 전환(배터리·태양광 제조)——이 세 축을 실제 산업으로 만드는 물리 층은 공장과 전력망입니다. 이 물리 층을 빼면, 미래산업 논의가 소프트웨어 데모와 투자 발표에서 끝나게 됩니다.
또한 이 3축 프레임이 영원히 유효하지는 않을 수 있습니다. 양자컴퓨터, 바이오테크, 우주산업이 산업 인프라 수준에서 영향력을 갖게 되면 축 자체를 다시 봐야 합니다. 현재 시점에서는 투자 규모·설치 기반·전력 부하 세 지표에서 AI·로봇·에너지가 가장 크게 겹치는 영역이 제조 현장입니다.
자주 묻는 질문
Q: 미래산업을 공부하려면 이 시리즈를 어떤 순서로 읽어야 하나요?
A: 1편(입문 지도)→2편(AI 스택)→3편(휴머노이드)→4편(전력)→5편(배터리)→6편(이 글) 순서가 설계된 학습 경로입니다.
Q: 이 시리즈 이후에는 무엇을 읽으면 되나요?
A: IEA의 “Energy and AI”, “Electricity 2025”, “Batteries and Secure Energy Transitions”, IFR의 “World Robotics 2025”, Stanford HAI “AI Index Report 2025″를 직접 읽어 보세요. 모두 무료 또는 요약이 공개돼 있습니다.
Q: 한국에서 이 구조를 가장 잘 보여주는 사례는?
A: 삼성전자 평택 캠퍼스(반도체+전력+자동화), SK 배터리 공장(배터리=제품+인프라), 현대 울산(EV 전환+로봇 밀도)이 모두 세 축의 교차점입니다.
Q: “공장이 미래산업의 전장”이라는 건 소프트웨어가 중요하지 않다는 뜻인가요?
A: 아닙니다. 소프트웨어는 당연히 중요합니다. 하지만 AI 모델을 돌리는 데이터센터도, 로봇을 만드는 공장도, 배터리를 생산하는 팹도 결국 물리 설비입니다. 소프트웨어의 가치가 실현되려면 이 물리 층이 따라줘야 합니다.
Q: 이 블로그에서 계속 미래산업 글이 나오나요?
A: 네. 이 시리즈는 입문 학습 루프를 닫는 6편이고, 이후에는 각 축의 심화 글(전력망 병목 상세, 휴머노이드 ROI 분석, 배터리 공급망 등)을 계속 발행합니다.
회원 등록(무료)으로 매주 월요일 뉴스레터 받기 → 등록하기
저자: VibeCoding Tailor (shuntailor.net 운영. AI 도구 실무 활용과 미래산업 구조 해설을 일본어·한국어로 발신 중. Lovable 공식 앰버서더.)
이 글에서 사용한 데이터의 출처
산업 에너지 비중(37%), 전기화 목표(23→30%), 중국 신에너지 제조(300+TWh)는 IEA의 공식 보고서에서 가져왔습니다. 로봇 설치 데이터(428만 대)는 IFR, AI 투자 데이터($1,091억)는 Stanford HAI에서 가져왔습니다. 전력 장비(변압기 4년, 큐 2,500GW)는 IEA + LBNL 데이터입니다. 모든 숫자는 1차 데이터입니다.
왜 “연결”이 “생산”보다 어려운가
발전소를 짓는 것은 “한 장소에서 장비를 설치하는 것”입니다. 태양광 패널을 사막에 깔거나 가스 터빈을 설치합니다. 한 장소, 한 소유자, 비교적 단순한 허가.
하지만 전기를 보내는 것(송전)은 “여러 장소를 관통하는 선을 까는 것”입니다. 수십~수백 km의 송전선이 여러 지자체, 여러 토지 소유자, 여러 환경 구역을 지나갑니다. 각각의 토지 허가, 환경 심사, 주민 동의가 필요합니다. 기술적으로는 6개월이면 깔 수 있는 선이, 허가 때문에 5~10년 걸리기도 합니다.
개발자 비유: 코드를 작성하는 것(발전)은 한 팀이 할 수 있지만, 다른 팀의 API에 연결하는 것(송전)은 인증, 호환성, SLA 협의, 보안 검토가 필요합니다. 코드 자체보다 연결(integration)이 더 오래 걸리는 것과 같은 구조입니다.
한국 3사의 순환 구조
삼성이 만든 반도체 → AI를 돌리고 → 그 AI가 SK 배터리 공장의 공정을 최적화 → SK 배터리가 현대 EV에 들어가고 → 현대 공장의 로봇이 전력을 소비 → 같은 한전 계통. 세 기업이 같은 전력 인프라를 놓고 경쟁하면서 동시에 서로의 제품을 필요로 하는 결합 구조입니다. 뉴스를 따로 읽으면 “삼성은 반도체, SK는 배터리, 현대는 자동차”이지만, 이 프레임으로 읽으면 하나의 산업 구조입니다.
이 시리즈를 마치며
6편을 다 읽은 독자에게 남는 가장 중요한 것: 같은 뉴스를 읽어도 보이는 것이 달라진다. “대단하다/별로다”를 넘어 “이 발표가 실제로 언제 산업이 되는가”를 구조적으로 판단하는 프레임이 생깁니다. 이 프레임은 투자자에게는 타이밍 판단에, 개발자에게는 인프라 제약 이해에, 학생에게는 공부 방향 설정에, 정책 담당자에게는 산업 간 연결 구조 파악에 각각 다르게 쓸 수 있습니다.
이 시리즈의 핵심을 한 문장으로: 미래산업은 AI·로봇·에너지가 따로 뜨는 세 시장이 아니라, 공장과 전력망이라는 물리적 교차점에서 서로를 제약하고 밀어 올리는 결합 구조다.
이 시리즈가 다른 미래산업 콘텐츠와 다른 점: 대부분의 미래산업 콘텐츠는 “이 기술이 대단하다”에서 끝납니다. 이 시리즈는 “대단한 기술이 실제로 산업이 되려면 무엇이 필요한가”를 물리 층까지 내려가서 봤습니다. 변압기 4년, 큐 2,500GW, 466만 대 설치 기반, 배터리 42→1,500GW——이 숫자들은 “대단함”의 반대편에 있는 “현실”입니다. 대단함과 현실을 동시에 보는 것이 미래산업을 구조적으로 읽는 것입니다.
마지막으로 개발자에게: 소프트웨어 세계에서 잘 알려진 격언이 있습니다. “Premature optimization is the root of all evil”(조기 최적화는 만악의 근원). 미래산업에도 비슷한 격언을 제안합니다: “Premature scaling without infrastructure is the root of all delays”(인프라 없는 조기 확장은 모든 지연의 근원). AI 모델이 아무리 좋아도, 전력이 없으면 스케일이 안 됩니다. 인프라가 먼저입니다.
이 시리즈에서 사용한 전체 데이터 출처
이 시리즈 6편에서 사용한 모든 숫자는 아래 5개 기관의 1차 데이터에서 가져왔습니다.
| 기관 | 제공 데이터 | 신뢰도 |
|---|---|---|
| IEA (국제에너지기구) | 전력 수요(460→1,300TWh), 배터리(42GW→1,500GW), 장비 가격, 산업 에너지 37% | 최고 (30개국 에너지부 참여) |
| IFR (국제로봇연맹) | 로봇 설치 대수(466만), 밀도(1,012), 지역 분포(아시아 74%) | 최고 (제조사 직접 집계) |
| Stanford HAI | AI 투자($1,091억), 도입률(78%), 추론 비용(280배↓) | 높음 (연례 종합 보고서) |
| LBNL (버클리연구소) | 인터커넥션 큐(2,500GW), 큐 처리 시간 | 높음 (미국 에너지부 산하) |
| FERC (미국에너지규제위) | 인터커넥션 절차 개혁(Order 2023) | 최고 (정부 공식 명령) |
이 데이터들은 “뉴스 기사의 추정치”나 “개인 블로그의 분석”이 아니라, 각 분야의 공인 기관이 직접 수집·분석한 1차 데이터입니다. 이 시리즈의 숫자가 맞는지 직접 확인하고 싶으면, 아래 원본 보고서를 읽어 보세요. 모두 무료로 공개돼 있거나 요약이 공개돼 있습니다.
소스 목록
- IEA — Electricity 2025
- IEA — Energy and AI (2025)
- IEA — Batteries and Secure Energy Transitions
- IEA — Energy Efficiency Policy Toolkit 2025
- IFR — World Robotics 2025
- Stanford HAI — AI Index Report 2025
- LBNL — Queued Up (2025)
- FERC — Order No. 2023