

2026年2月、Andrej Karpathy——OpenAI共同創業者にしてバイブコーディングの名付け親——が、Xへの投稿でこう書いた。
“agentic” because the new default is that you are not writing the code directly 99% of the time, you are orchestrating agents who do and acting as oversight — “engineering” to emphasize that there is an art & science and expertise to it.
人間がコードを直接書くのではなく、AIエージェントを指揮して開発を進める手法。これがエージェンティックエンジニアリングの定義だ。
ただし「AIを監督する」という説明だけでは、実務で何をすればいいのか分からない。実際に品質を安定させている開発者たちが何をやっているかを見ると、プロンプトの書き方よりも作業システムの設計——ハーネス、検証ループ、運用ルール——に時間を使っている。
この記事では、エージェンティックエンジニアリングを「監督する」の先にある設計の問題として整理する。
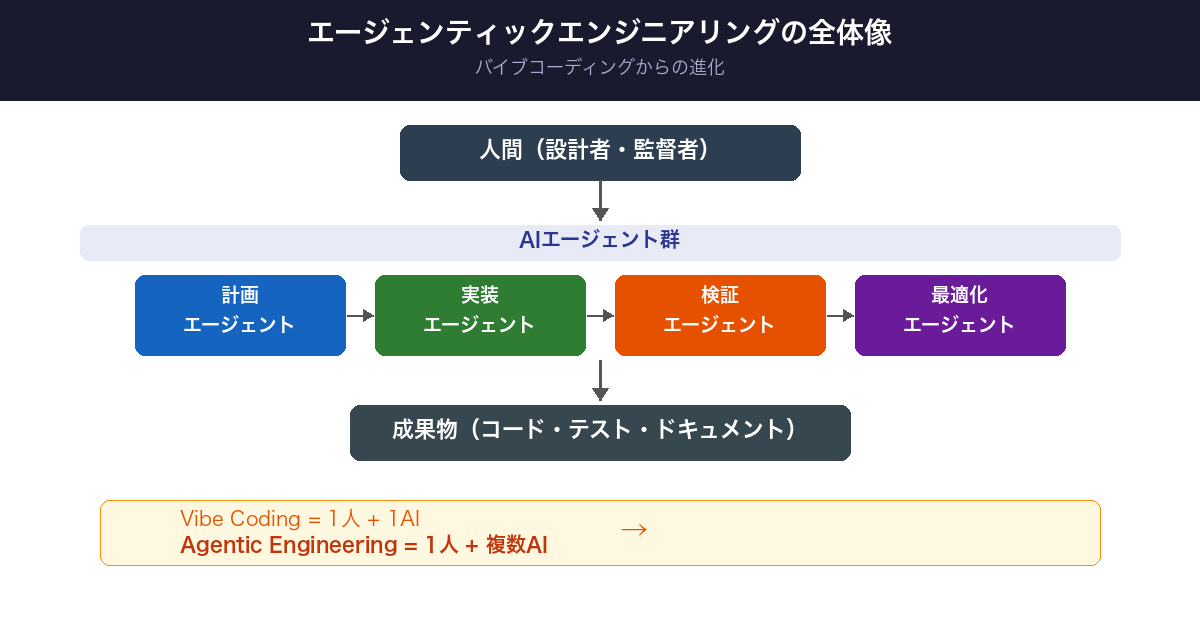
バイブコーディングとの違い——比較表の先にあるもの
バイブコーディングとエージェンティックエンジニアリングの違いは、よく以下の表で説明される。
| 項目 | バイブコーディング | エージェンティックエンジニアリング |
|---|---|---|
| 人間の役割 | プロンプトを投げる | 設計・監督・品質保証 |
| コードレビュー | しない | PRレビューと同等の確認 |
| テスト | 「動けばOK」 | テストスイートを組み込む |
| 計画 | なし。即実行 | 設計書を書き、タスクを分解 |
| 対象 | 趣味・デモ | 本番環境 |
この表は正しい。だが「設計・監督」の中身が見えない。実際にAIエージェントで安定した品質を出している開発者は、4つの層を意識して作業システムを組んでいる。
ハーネス4層モデル——プロンプトの代わりに設計するもの
はじめに、分かりやすいたとえを使おう。
AIエージェントを「新しく入った優秀なアルバイト」だと思ってほしい。頭は良い。でも、店のルールを知らない。何が禁止か分からない。仕事が終わったかどうかの判断基準も持っていない。
だから必要なのは「もっと上手な声のかけ方」ではなく、ルールブック(guidance)、道具箱(tool connectivity)、チェックリスト(verification)、業務日報(visibility)だ。
これがハーネス4層モデルの基本的な考え方で、OpenAI公式ガイドやAnthropicのエージェント設計ドキュメントでも繰り返し強調されている構造だ。
第1層:持続的ガイダンス(Durable Guidance)
チャットで毎回同じ指示を繰り返していないだろうか。「TypeScriptのstrictモードで書いて」「テストは必ずvitest」「このディレクトリには触らないで」——こうした繰り返しプロンプトを、ドキュメントに昇格させるのが第1層だ。
具体的には、リポジトリに置く設計書がこれにあたる。
| ファイル | 役割 | 主な利用ツール |
|---|---|---|
| AGENTS.md | リポジトリ全体のルール・禁止コマンド・検証基準 | OpenAI Codex |
| CLAUDE.md | プロジェクト固有のコンテキスト・作業手順 | Claude Code |
| .cursorrules | エディタ固有のコーディングルール | Cursor |
| DESIGN.md | デザインの制約条件・ブランドルール | 汎用 |
OpenAI公式ガイドは「繰り返しのプロンプトをAGENTS.mdに昇格させよ」と明記している。2,500以上のリポジトリがAGENTS.mdを採用し、関連する設定ファイルを持つプロジェクトは60,000を超える。
なぜこれが重要か。ハーネスエンジニアリングの考え方では、モデルの性能を「天井」ではなく「ばらつき」として見る。弱いハーネスだと、良いモデルでも結果が不安定になる。強いハーネスがあれば、モデルが変わっても結果の安定性が保たれる。
プロンプトを上手に書くことと、ガイダンスを設計することは、似ているようで違う。プロンプトはセッションが終われば消える。ガイダンスはリポジトリに残り、次のセッション、次のチームメンバー、次のモデルにも引き継がれる。
第2層:ツール接続(Tool Connectivity)
エージェントは「考える」だけでは仕事ができない。ファイルを読み、APIを叩き、データベースに書き込み、外部サービスと連携する必要がある。この接続を標準化する仕組みがMCP(Model Context Protocol)だ。
MCPの役割は「AIアプリのUSB-Cポート」と考えると分かりやすい。どのモデルでも、同じ規格でツールやデータに接続できる。
MCPには3つの基本要素がある。
| 要素 | 役割 | 例 |
|---|---|---|
| Tools | 実行可能な関数 | ファイル作成、API呼び出し、DB操作 |
| Resources | 読み取り専用データ | 設定ファイル、ドキュメント |
| Prompts | 再利用可能なコマンド | スラッシュコマンド |
ここで経験者が見落としがちなポイントがある。ツール接続が増えるほど、エラーの増幅リスクも上がる。ツールが多い=能力が高い、は半分だけ正しい。もう半分は「プロンプトインジェクション、破壊的操作、古いコンテキストの混入」というリスクの増大だ。
だからこそ、第1層のガイダンスで「触っていいファイル」「叩いていいAPI」「禁止操作」を明示する必要がある。ツール接続とガイダンスは、セットで設計するものだ。
第3層:検証ループ(Verification Loop)
エージェントが作ったコードを「信じる」のではなく、検証してから進む。これが第3層だ。
Mitchell Hashimoto(HashiCorpの共同創業者)のClaude Codeの運用例が参考になる。彼はスクリーンショット確認、専用検証スクリプト、フィルタテストを組み合わせて、繰り返しのミスをハーネスの改善で吸収していった。
検証ループには4つの段階がある。
| 段階 | 問い | 具体例 |
|---|---|---|
| 仕様確認 | 成功とは何か | AGENTS.mdの完了定義、引用基準 |
| 実行確認 | 実際に動いたか | テスト、lint、ビルド、コマンド出力 |
| 現実確認 | ユーザーの現実と合っているか | スクリーンショット、UXレビュー、価格確認 |
| 記録確認 | 次のセッションが学べるか | ログ、引き継ぎメモ |
ここに、経験者でも見落としやすい構造がある。エージェントの本当の競争力は、生成速度ではなく「間違った結果を早く発見して、再現可能な形で修正する速度」にある。
テストが通った、ビルドが成功した——それだけでは「現実確認」が抜けている。画面を見たか。ユーザーの期待と合っているか。価格やリンクは正しいか。この層を入れるだけで、エージェントの出力品質は大きく変わる。
第4層:運用者の可視性(Operator Visibility)
エージェントが何をしているか、どこまで進んだか、いくらかかったか——これが見えないと、チームでは使えない。
可視性が必要な理由は、「信頼」のためだけではない。ダッシュボード、セッションログ、引き継ぎ記録がなければ、成功したときにも「なぜうまくいったのか」が残らない。同じ成功を再現できないなら、それは運用とは呼べない。
個人開発なら「ログを見ればいい」で済むかもしれない。だがチームでエージェントを使うなら、トークン消費量、セッション時間、未完了タスクの一覧、次のアクションが全員に見える状態が前提になる。
なぜ「プロンプトを上手に書く」では足りないのか——メカニズムの話
ここまで読んで「結局、プロンプトの書き方の話と何が違うのか」と思った人もいるだろう。違いは、効果が持続する期間にある。
プロンプトは、1回のセッションで消える。良いプロンプトを書いても、次のセッションではゼロから。チームメンバーには共有されない。モデルが変わったら効果も変わる。
一方、AGENTS.mdに書かれたルールはリポジトリに残る。次のセッションでも、別の開発者が使っても、モデルが変わっても、同じ基準で動く。
同じモデルを使っていても、ハーネスの有無で結果の安定性が大きく変わる。これは「モデルの能力」の問題ではなく「作業環境の設計」の問題だ。
OpenAI Codex公式ドキュメントもAnthropicのエージェント設計ガイドも、繰り返し強調しているのはプロンプトの巧みさではなく、リポジトリルール、完了定義、検証基準の設計だ。
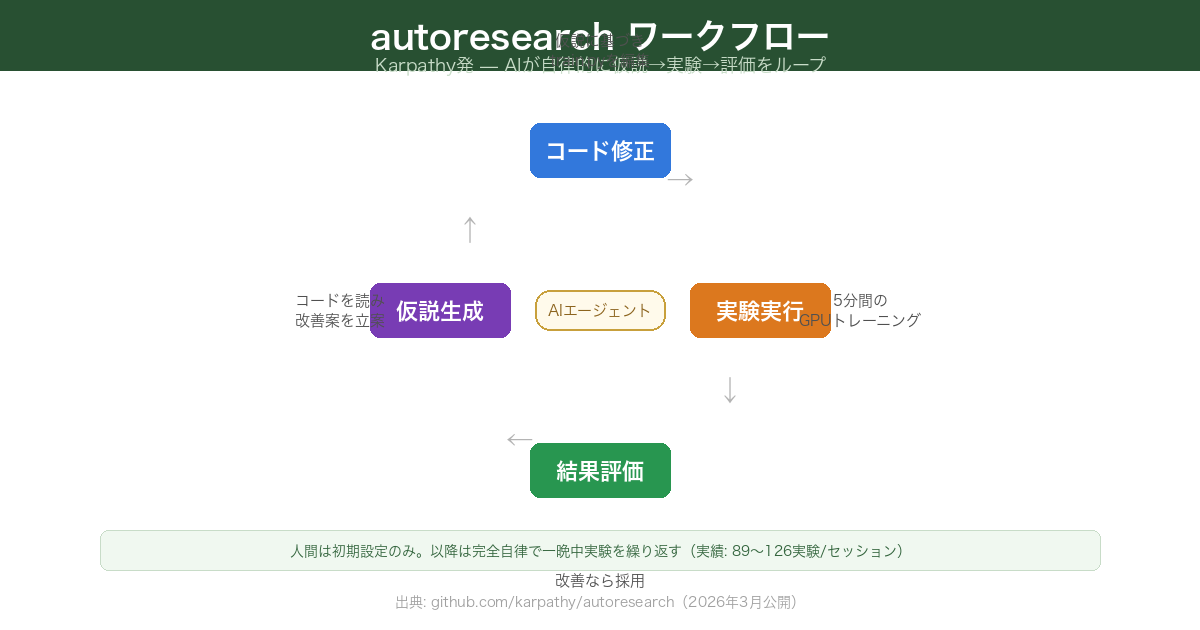
autoresearch——630行に見えるハーネス設計
2026年3月、Karpathyが公開したautoresearchは、エージェンティックエンジニアリングの実践例として注目された。630行のPythonスクリプトで、AIエージェントが自律的にML実験を繰り返す。
構造はシンプルだ。
| ファイル | 役割 | ハーネス4層との対応 |
|---|---|---|
| program.md | AIへの行動指示書(人間が設計) | 第1層:持続的ガイダンス |
| prepare.py | データ準備・ユーティリティ(固定) | 第2層:ツール接続 |
| train.py | モデル訓練スクリプト(AIが編集) | 第3層:実行→検証のループ対象 |
| 実験ログ | 各実験の結果記録 | 第4層:可視性 |
1時間あたり約12回の実験。一晩で約100回。公開5日でGitHubスター27,900以上。
ここで注目すべきは、630行という短さではなく、program.mdの設計だ。「何を研究するか」「どう評価するか」「何をしてはいけないか」——これがなければ、エージェントはただランダムに実験を繰り返すだけになる。
autoresearchが示しているのは「AIが賢いから100回実験できる」ではなく、「ハーネスがしっかりしているから、100回の実験が意味のある方向に進む」ということだ。
なぜ今、この変化が起きているのか
3つの条件が揃った。
1. モデルの能力が「仕事に使える」水準に達した
SWE-Bench Verifiedでの成績は18ヶ月で33%から80%超に伸びた。コード修正の精度が上がったことで、「エージェントに任せる」が現実の選択肢になった。
2. コストが下がった
AI推論コストは3年間で92%下落。100万トークンあたり$30だったものが$0.10〜$2.50になった。個人開発者でもエージェントを複数動かせる。
3. エージェント基盤が標準化されつつある
2026年に入り、主要企業がエージェント基盤を発表した。
| 企業 | 発表 | 概要 |
|---|---|---|
| OpenAI | AgentKit | エージェント構築・展開ツールセット |
| Anthropic | Managed Agents | session, harness, sandboxを分離したホスト型エージェント |
| Agent2Agent (A2A) | エージェント間相互運用プロトコル |
さらに、Agentic AI Foundation (AAIF)がLinux Foundation傘下で設立された。Microsoft、Google、Anthropic、OpenAIが共同で、AIエージェントのオープンソース標準を策定している。MCPのガバナンスもここに移管された。
モデルの能力が上がり、コストが下がり、接続規格が標準化された。この3条件が「賢いプロンプト」から「作業システム設計」への移行を加速させている。
導入事例——数字で見る効果とリスク
| 企業 | 導入内容 | 結果 |
|---|---|---|
| Mercedes-Benz Financial | マルチエージェントCRM | 新規事業獲得20%増、アップセル15%向上 |
| Walmart | 在庫管理AIエージェント | 売上22%増、在庫切れ削減 |
| 医療スタートアップ | 薬事前承認の自動化 | 承認期間30日→3日 |
Deloitteの調査(24カ国3,235名の経営幹部対象)によると、74%の企業が2年以内にエージェンティックAIを本格導入予定と回答している。
ただし、数字の裏側も見る必要がある。レガシーエージェントの90%が数週間以内に失敗しているというデータもある。ガバナンスの成熟モデルを持つ企業はわずか21%。この差は何か。
失敗するエージェント導入に共通するのは、「モデルを入れたがハーネスを設計しなかった」パターンだ。ガイダンスがない、検証ループがない、可視性がない——つまり第1層から第4層が全部欠けている状態で「AIを導入した」と言っている。
個人開発者が今日から始める4ステップ
ステップ1:リポジトリに設計書を置く
CLAUDE.mdやAGENTS.mdをリポジトリのルートに作る。書く内容は3つ。
- 技術スタック(使う言語・フレームワーク・デプロイ先)
- 禁止事項(触ってはいけないファイル、使ってはいけないコマンド)
- 完了定義(何ができたら「終わり」なのか)
これだけで、エージェントの出力は明らかに安定する。繰り返し伝えていた指示を文書化するだけだからだ。
ステップ2:タスクを分解する
「アプリを作って」ではなく、機能単位で分解して1つずつ任せる。
タスク1: ユーザー認証(Supabase Auth)を実装
タスク2: タスクCRUD APIを実装
タスク3: ダッシュボードUIを実装
タスク4: 各機能のテストを書く各タスク完了後に人間がレビューする。この「分解→実行→確認」のループが、バイブコーディングとの実務上の分岐点になる。
ステップ3:検証を組み込む
AIが書いたコードを信じる前に、最も安い検証から付ける。テストを走らせる。ビルドを通す。画面を確認する。リンクが生きているか確認する。
検証で見つかった問題は、プロンプトで直すのではなく、設計書に追記する。「次のセッションで同じミスが起きない」ようにする。これが検証ループの本質だ。
ステップ4:ログを残す
何をやったか、何がうまくいったか、何が失敗したか。引き継ぎメモを残す習慣をつける。個人開発でも、3日前の自分は「別のチームメンバー」だと思ったほうがいい。
よくある質問(FAQ)
Q: プログラミング知識がなくても始められますか?
バイブコーディングほどゼロ知識では始められない。少なくとも「何を作りたいか」を技術的に分解できる力が必要だ。ただし、コードを書く力よりも「設計力」と「レビュー力」が重要になるため、従来のプログラミング学習とは求められるスキルが違う。
Q: バイブコーディングはもう使えないのですか?
使える。Karpathy自身が述べている通り、プロトタイプやデモにはバイブコーディングが有効だ。エージェンティックエンジニアリングは「本番環境で品質を維持したい場合」の進化形であり、用途に応じた使い分けが適切だ。
Q: おすすめのツールは?
現時点ではClaude Codeが最も実用的だ。CLAUDE.md、Skills、Hooks、MCPを活用することで、ハーネス4層のうち3層(ガイダンス・ツール接続・検証)をカバーできる。他にはCursor、OpenAI Codexが対応を進めている。
Q: 「ハーネス」とは何ですか?
エージェントが正しく動くための作業環境全体を指す。ルール文書、ツール接続設定、テスト・検証の仕組み、ログ・可視化の仕組みの4つを合わせたもの。プロンプトが「1回の指示」なら、ハーネスは「繰り返し使える作業システム」だ。
このカテゴリの読み順
AI Agent Design カテゴリでは、以下の順序で読むと全体像が掴みやすい。
AI Agent Design 読み順
- この記事 — エージェンティックエンジニアリングの全体像
- ハーネスエンジニアリング完全ガイド — ハーネス設計の実践
- AIエージェント ログ記録方法 — 第4層(可視性)の実装
次の記事では、ハーネスエンジニアリングの実践——AGENTS.md、検証ループ、スキルパッケージングの具体的な作り方を詳しく扱う。
まとめ
| 時代 | 人間の役割 | 品質を決めるもの |
|---|---|---|
| 従来のプログラミング | コードを書く | コーディング能力 |
| バイブコーディング(2025年) | プロンプトを投げる | プロンプトの質 |
| エージェンティックエンジニアリング(2026年) | 作業システムを設計する | ハーネスの設計 |
エージェンティックエンジニアリングの核心は「AIを監督する」ではない。ガイダンス、ツール接続、検証ループ、可視性という4つの層で作業システムを設計することだ。
プロンプトを上手に書くことも大事だが、それはセッションが終われば消える。ハーネスとして設計されたルールは、リポジトリに残り、チームに引き継がれ、モデルが変わっても機能し続ける。
参考ソース
- Andrej Karpathy — X投稿(2026年2月8日)
- Addy Osmani — Agentic Engineering
- Karpathy — autoresearch(GitHub)
- Agentic AI Foundation(Linux Foundation)
- Deloitte — State of AI Report 2026
- Anthropic公式 — Claude Codeドキュメント
著者: VibeCoding Tailor
運営: テイラーの隠れ家(shuntailor.net)




