
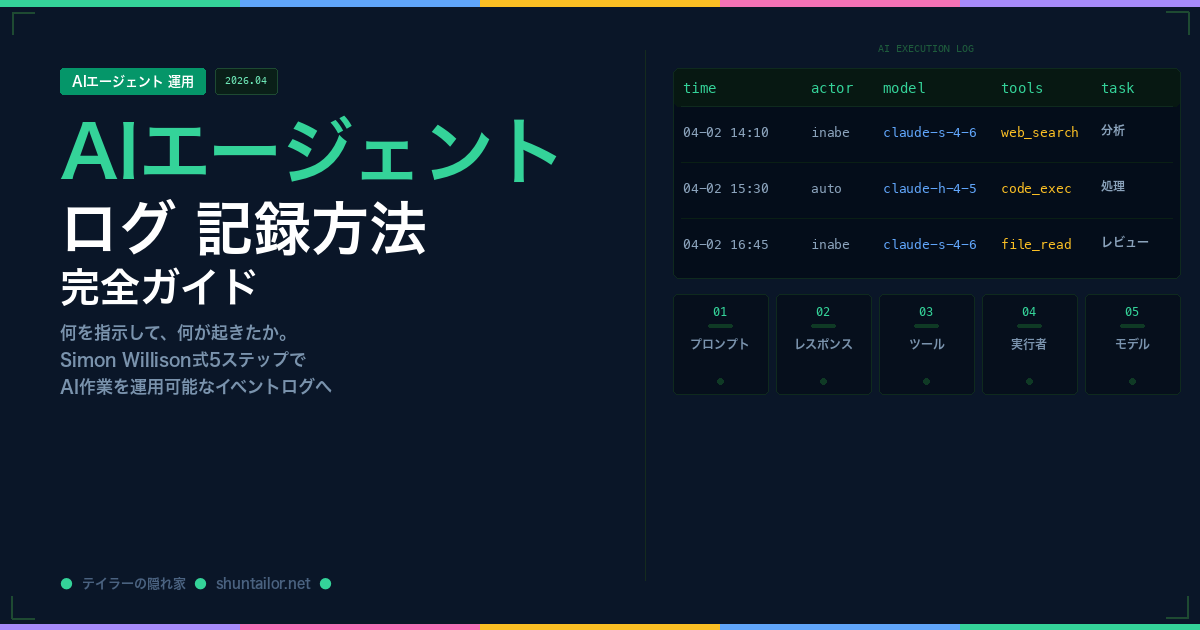
AIエージェント ログ 記録方法【2026年最新】Simon Willison式5ステップ完全ガイド
AIエージェント ログ 記録方法とは、AIに仕事を任せた後で「何を指示したか」「AIがどう動いたか」「どのツールを使ったか」を追跡できるよう、プロンプト・レスポンス・ツール使用・実行者・使用モデルの5要素を構造化して保存するワークフローのことだ。2026年4月、Simon Willisonが公開したLLMツールのリリースを読むと、彼がこのワークフローを「チャットして終わり」ではなく「SQLiteに記録してDatasette(データ探索ツール)で再閲覧できる運用システム」として設計していることがわかる。
この記事では、そのアプローチを日本語で体系的に解説する。ファイルログから始めて、最終的にはSimon式のSQLite+ビューア構成まで、自分のペースで取り組める3段階で紹介する。
AIエージェント ログ 記録方法——なぜ今これが必要なのか
AIを1回使って結果をコピペして終わり、という使い方をしている人が多い。それで問題ないケースもある。でも、こんな経験はないだろうか。
- 先週AIに作らせたコードの「なぜこうなっているのか」がわからなくなった
- 同じプロンプトを再現しようとしたが、うまくいかなかった
- チームのメンバーがAIに何を指示したか把握できない
- コスト最適化のために、どのモデルをどの作業に使ったか振り返りたい
これらはすべて、ログがないことで起きる問題だ。AIエージェント ログ 記録方法を実践すれば、結果が想定外になったときに「プロンプトが問題だったのか」「ツールが誤作動したのか」「モデルの限界だったのか」を正確に追跡できるようになる。
Simon Willisonはこれをこう表現している——「AIに仕事を任せたら、何が起きたか後から見返せるようにしろ」。シンプルだが、AIが業務に入り込んだ2026年においては、これが運用の基本になる。
関連: ハーネスエンジニアリング完全ガイド / エージェンティックエンジニアリング完全ガイド
AIエージェント ログ 記録方法——記録すべき5つの要素
AIエージェント ログ 記録方法で保存すべき情報は5つに絞れる。どのレベルの実装から始めるにせよ、この5要素が揃えば「後から追跡可能なログ」になる。
指示したか
答えたか
行動ログ
動かしたか
どの作業に
1. プロンプト——指示の記録
AIに何を言ったか残す。結果が想定外だったとき、プロンプトの書き方が原因だったのかどうか判断できる。「あのとき何て入力したっけ」が起きなくなる。
2. レスポンス——AIの判断の記録
AIの答えを残す。結果だけでなく、AIがどんな判断フローで答えたかを後から読めるようになる。微妙に違う結果が出たときの比較分析にも使える。
3. ツール使用——中間行動の記録
ウェブ検索、ファイル読み込み、コード実行といった中間的な行動を残す。エージェントが「何を調べて、何を実行した結果この答えになった」という行動ログが生まれる。
4. 実行者(actor)——責任の記録
自分が実行したのか、チームメンバーが実行したのか、自動化が実行したのかを残す。誰の指示で何が起きたかが明確になり、運用上の責任範囲が整理される。
5. 使用モデル——コスト・品質の記録
どの作業にどのモデルを使ったか残す。後から「この作業はOpusより安いモデルで十分だった」「この作業だけ精度が落ちた」という最適化ができるようになる。
AI業務自動化に興味がある方は、Instagram(@taro_taro609)にDMで「診断」と送ってください。
Simon Willisonが2026年4月に実装したログシステム
Simon Willisonは、オープンソースツール「llm」の作者であり、PythonのDjangoフレームワークのコアメンバーでもある開発者だ(出典: Simon Willison April 2026 archive)。彼の公開リリースを追うと、AIエージェント ログ 記録方法の実装が具体的に見えてくる。
2026年4月1日のリリースで繰り返し登場するポイントはこれだ。
- llm_prompt_context() によるチェーン内プロンプト追跡とtool call loop追跡
- prompts・responses・tool callsを内部SQLiteテーブルに記録
- usageページにpermission追加(誰が何を使えるかの管理)
- モデル構成を作業目的別に分類:enrichments purpose、extract purpose
- actorを
llm.mode(... actor=actor)で伝達 - default modelとallowed modelsの整理
注目すべきは「actorを渡せるようにした」変更だ。これにより、ログに「誰が実行したか」が入るようになった。ツールを使ったという事実だけでなく、誰の意思決定でそのツールが動いたかが記録される。これは、個人利用から小チームへのスケールアップに不可欠な変更だ。
📩 毎週月曜日、AIトレンドをまとめたニュースレターを配信中
登録すると毎週月曜日に「今週のAI・バイブコーディング最新情報」をお届けします。
記事では書けないリアルな実践ノウハウも会員限定で公開しています。
AIエージェント ログ 記録方法——Simon式5ステップワークフロー
Simonのpublicなツールとリリースから確認できるワークフローを5段階で整理する。
ターミナルで
llm CLIを使う。
実行が自動的に
SQLiteに記録される
自動保存
tool calls・usageが
ローカルDBに
蓄積される
ログを閲覧
logs path)”を実行。
ブラウザでログを
検索・フィルタ
モデルを分ける
extract用など
作業ごとに許可
モデルを制御
ログに含める
actor=で指定。
個人→チームへの
スケールが容易に
Simon式の重要なポイントは「保存は目的ではなく、後から見返せることが目的だ」という姿勢だ。SQLiteにデータが溜まっても、Datasetteで検索できる状態にしておかなければ意味がない。datasette "$(llm logs path)"という1行のコマンドで、ブラウザからすべてのAI実行ログを検索・フィルタできるようになる(出典: simonw/llm README)。
AIエージェント ログ 記録方法——3つの実装レベル
今日から始められる最もシンプルな実装から、Simon式に近い本格的な実装まで、3つのレベルで紹介する。
| レベル | 方法 | 必要スキル | 適した規模 | Simon式との距離 |
|---|---|---|---|---|
| Level 1 | Markdown / テキストファイル | なし | 個人・月10回以下 | 遠い(手動) |
| Level 2 | CSV / Googleスプレッドシート | スプレッドシート基礎 | 個人〜小チーム | 中間 |
| Level 3 | llm CLI + SQLite + Datasette | ターミナル基礎・pip | 小チーム〜中規模 | 近い(自動記録) |
AIエージェント ログ 記録方法——今日から始める実践5ステップ
どのレベルから始めるにせよ、この5つを意識するだけで「追跡可能なAI運用」に変わる。
- AIに指示したプロンプトを残す——コピペでいい。どこかに記録する習慣だけ持てばいい
- AIの答えも残す——結果だけでなく、判断の流れを後から読めるようにする
- 使ったツールを書き添える——「web_search」「code_execution」「file_read」など中間行動も記録
- 誰が実行したかを入れる(actor)——自分の名前でいい。チーム化したときの責任追跡に使える
- どのモデルをどの作業に使ったか残す——後からコスト最適化・品質分析に活きる
この5つが積み重なると、それが個人または小チームのAI運用ハーネスになる(関連: ハーネスエンジニアリングとは)。日記のように「使って終わり」のAIから、「使ったことが資産になる」AIへの転換だ。
Simonの言葉を借りれば——「AIに仕事を任せたら、何が起きたか後から見返せるようにしろ。それが唯一、AIを組織に組み込める条件だ」。
AIエージェント ログ 記録方法 よくある質問
Q. AIエージェント ログ 記録方法はどのツールから始めればいいですか?
最も手軽なのはMarkdownファイルへの手動記録(Level 1)です。今日使ったプロンプト・レスポンス・ツール・actor・モデルを1ファイルに書くだけで始められます。続けられるようになったらCSV(Level 2)→ llm CLI + SQLite(Level 3)と段階を上げるのが現実的です。
Q. AIエージェント ログ 記録方法でactorとは何を指しますか?
「誰がその実行を行ったか」を示すフィールドです。個人利用なら自分の名前(例: inabe)で十分です。チームで使う場合は、担当者名・ボット名・自動化システム名などを入れます。Simon Willisonはllm.mode(... actor=actor)で明示的に渡せるよう実装しました。actorがあることで、問題発生時に「誰の指示が原因だったか」を追跡できます。
Q. SimonのllmツールとDatasette、日本語環境でも動きますか?
はい、どちらもPython製のCLIツールで、日本語環境でも問題なく動作します。pip install llmでllmをインストールし、pip install datasetteでDatasetteをインストールできます。詳細はsimonw/llm GitHubを参照してください。APIキーの設定はllm keys set openaiやllm keys set anthropicで行えます。
Q. AIエージェント ログ 記録方法はどのくらいのストレージが必要ですか?
1回のLLM呼び出しのログは数KBから数十KB程度です。1日100回実行しても月に数MBのオーダーです。SQLiteは圧縮が効くため、数万回分のログでも数百MBに収まるケースが多いです。ローカル保存なのでクラウドストレージのコストは発生しません。
著者: VibeCoding Tailor
運営: テイラーの隠れ家(shuntailor.net)
- Simon Willison April 2026 archive: simonwillison.net/2026/Apr/
- simonw/llm GitHub README: github.com/simonw/llm
- Language models on the command-line handout: github.com/simonw/language-models-on-the-command-line
- Datasette documentation: datasette.io