[1편] 인터넷 네트워크 차이 — 바이브코더 CS심화코스

인터넷 네트워크 차이를 5단 동심원으로 풀어가는 첫 글. 같은 LAN 두 기기·사설IP/공인IP·traceroute로 동심원을 직접 본다 — AI로 앱 만드는 사람의 디버깅 첫 분기점.

자연어로 세계를 설계하다|Vibe Coding 미디어
인터넷 네트워크 차이를 5단 동심원으로 풀어가는 첫 글. 같은 LAN 두 기기·사설IP/공인IP·traceroute로 동심원을 직접 본다 — AI로 앱 만드는 사람의 디버깅 첫 분기점.
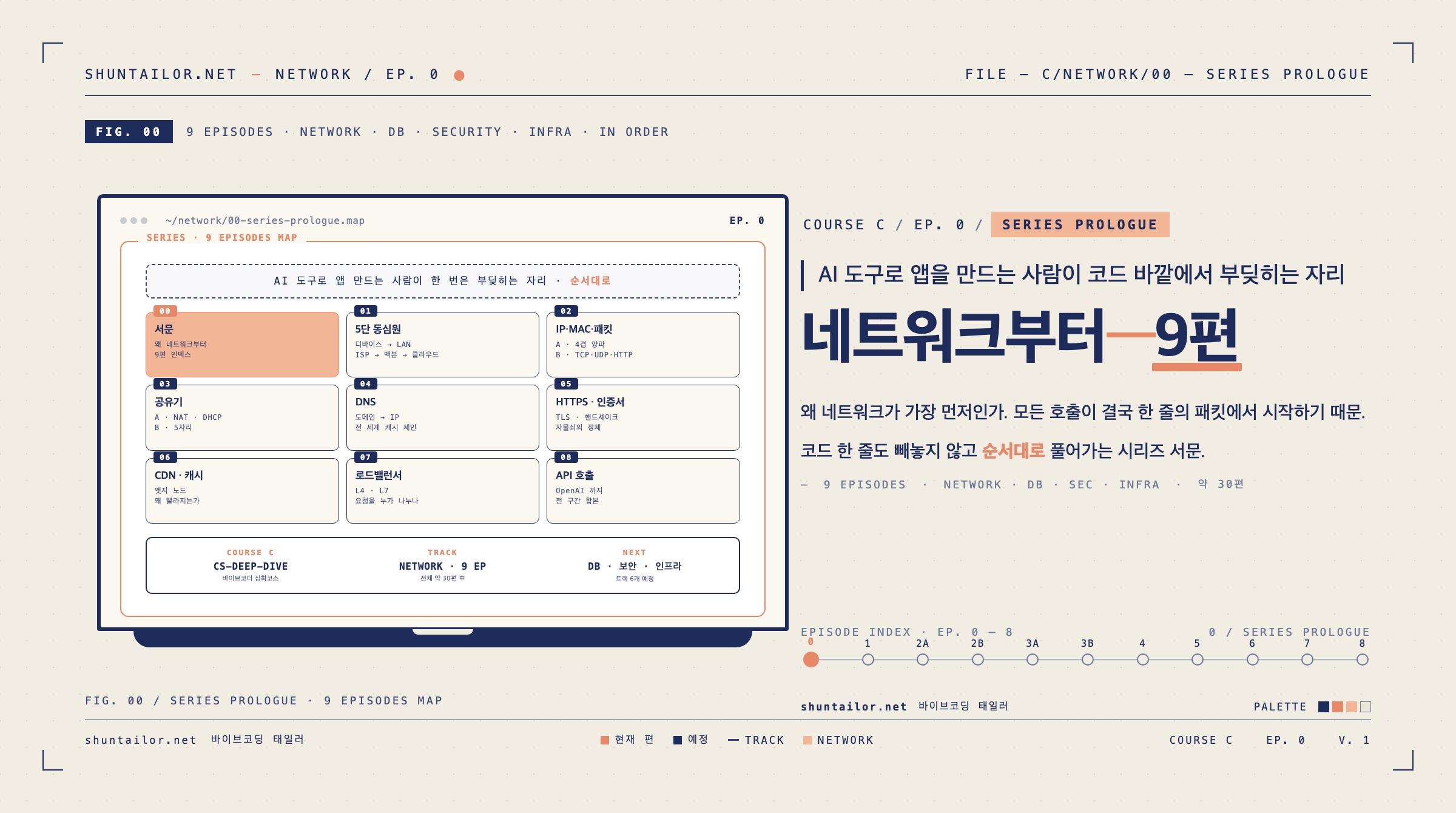
바이브코더 네트워크 9편 시리즈의 서문. AI로 앱을 만드는 사람이 코드 바깥에서 일어나는 일을 한 번은 정공법으로 보기 시작하는 첫 글. CS심화코스 첫 트랙.

ChatGPT 작동 원리 — 컨텍스트 윈도우(책상)·시스템 프롬프트·스킬 메타데이터(표지 비유)·md vs PDF·JSON streaming까지 LLM 추론의 입출력 구조를 학습자가 막히는 자리 그대로 정리한 LLM 이론 집중코스 3-B편.

ChatGPT 작동 원리 — 한 글자씩 답이 나오는 메커니즘부터 KV 캐시·GPU·VRAM·HBM·양자화·Softmax·Sampling·BPE·한글 토큰까지. LLM 추론의 본체를 학습자가 막히는 자리 그대로 정리한 LLM 이론 집중코스 3-A편.
AI 추론 모델 (o1·GPT-5.4 Pro·Claude Extended Thinking) 작동 원리. 23×47도 못 풀던 LLM이 60년 미해결 Erdős 수학을 80분에 푼 사건과 변형적 창의성 9개 사례까지 LLM 이론 집중코스 3.5편.

같은 ChatGPT인데 누군 60년 난제를 풀고 누군 저녁 메뉴를 정한다. AI 격차 프롬프트 한 방의 진짜 전제 조건과 AI에 끌려다니지 않기 위한 3가지 액션.
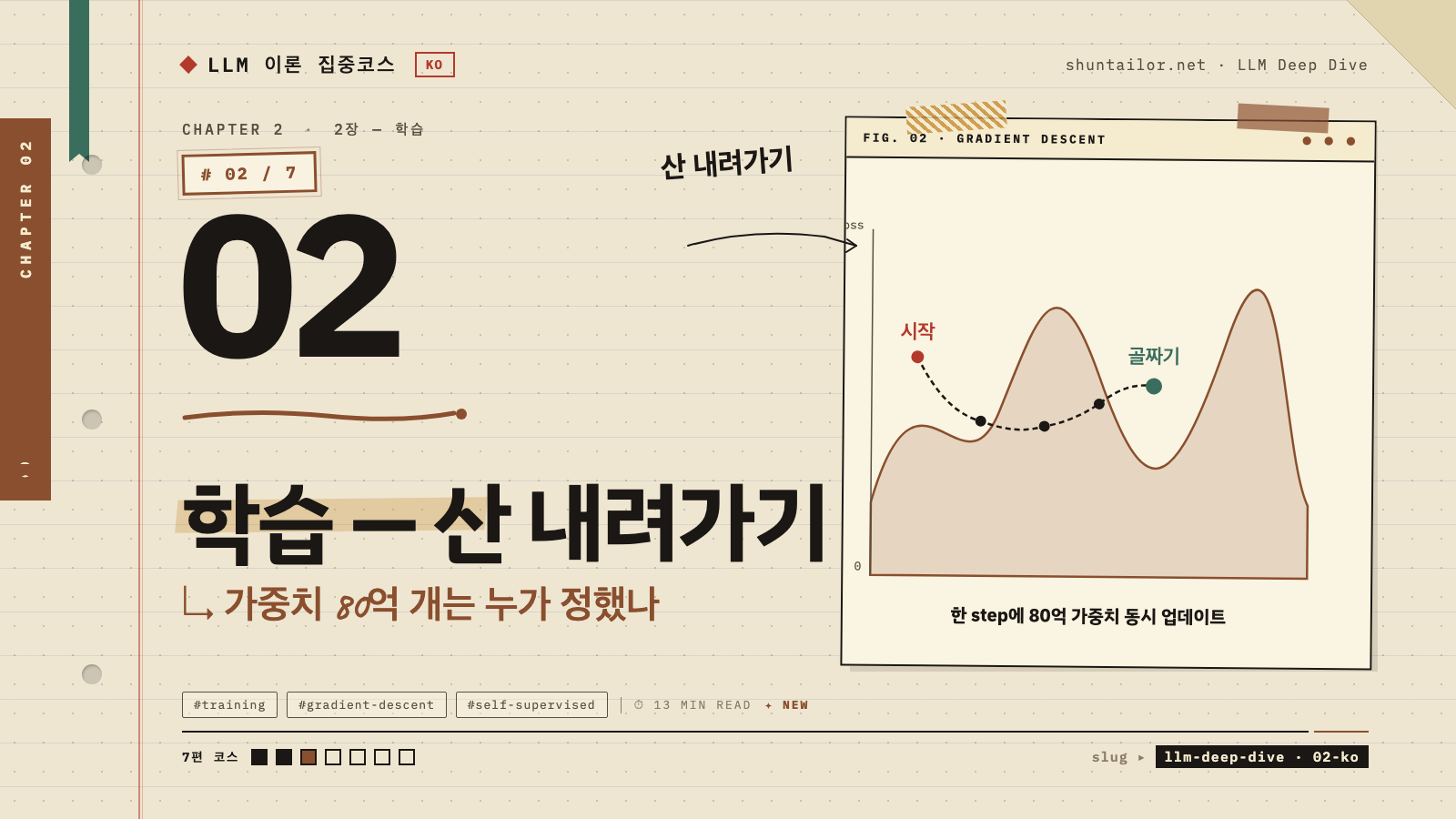
가중치 80억 개는 사람이 정하지 않는다. 데이터가 정한다. 학습이라는 산 내려가기를 직관으로 끝까지 따라가며, 왜 AI 학습이 도시 하나의 전기를 먹는지까지 도달하는 LLM 이론 집중코스 2편.

Ollama에서 시작해 LLM 본체까지 궁금해진 분들께. 가중치·벡터·토큰·임베딩의 정체를 직관으로 끝까지 파헤치는 LLM 이론 집중코스 1편.

📍 AI 공부 지도 — 29/29편 이 글은 AI의 기초부터 Meta-Harness·응용 비교까지 순서대로 읽는 29편 시리즈의 29편입니다.📚 전체 지도 보기 ← 이전 편: P5. 오픈 3강 Llama·Qwen·DeepSeek 📚 이 글을 읽기 전에: 22편 + P1~P5 (특히 F7 파라미터·P2 API 호출·P3 오픈 vs 클라우드) 가 핵심. ·LM Studio ― 로컬에서 LLM 돌리는 기술 스택 “API를 호출하는 … Read more

📍 AI 공부 지도 — 28/29편 이 글은 AI의 기초부터 Meta-Harness·응용 비교까지 순서대로 읽는 29편 시리즈의 28편입니다.📚 전체 지도 보기 ← 이전 편: P4. 클로즈드 4사 비교 · 다음 편: P6. Ollama·LM Studio 로컬 → 📚 이 글을 읽기 전에: 22편 + P1~P4를 읽으셨다면 OK. 특히 F7 파라미터·F2 Transformer가 핵심. Llama·· ― 오픈소스 3강의 기술 … Read more