
LLM학습。LLM 이론 집중코스 · 2편
1-A편 (가중치 80억 개의 정체) 을 안 읽으셨다면 먼저 보고 오시면 좋아요.
1-A편을 다 읽고 자연스럽게 떠오르는 질문이 있어요. 저도 그랬어요.
“그 80억 개 숫자는 도대체 누가, 어떻게 정한 거예요? 사람이 하나하나 정했을 리는 없을 텐데.”
답부터 말씀드리면 — 사람이 정하지 않아요. 데이터가 정합니다. 이게 학습이라는 거예요.
이 글에서는 그 학습이 실제로 어떻게 일어나는지 끝까지 따라가 볼 거예요. 산을 내려가는 등산가 비유부터 시작해서, 결국에는 “왜 AI 학습이 도시 하나의 전기를 먹는지” 까지 도달할 거예요. 한 번 가봅시다.
이번 편에서 잡고 가는 것 3가지:
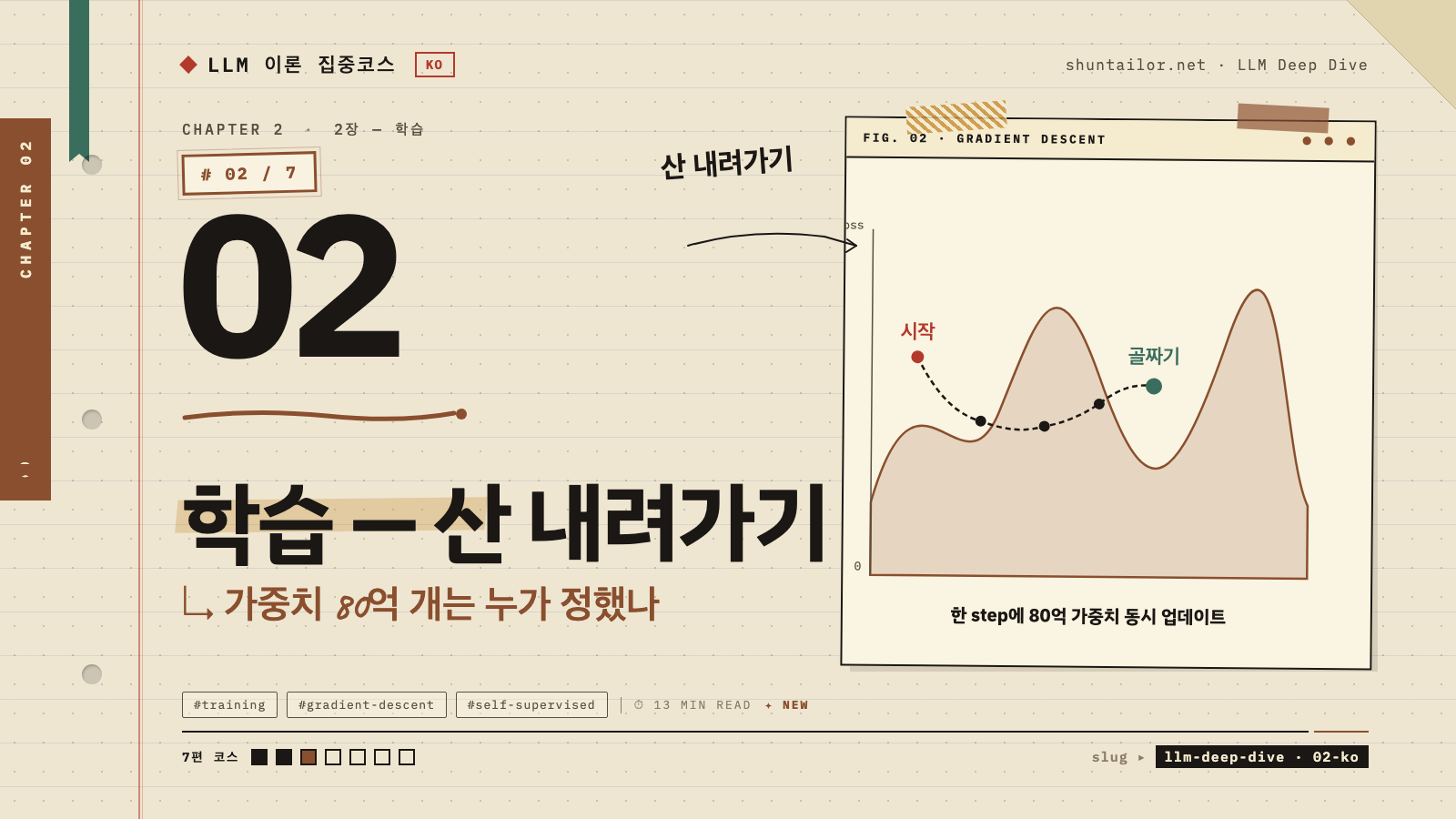
1. 학습이 “산 내려가기”라는 게 정확히 뭔지
2. 한 step에 80억 가중치가 어떻게 한 번에 움직이는지
3. AI 학습이 왜 자본·반도체·전력 경쟁이 됐는지
가장 직관적인 비유부터 — 산에서 내려오는 등산가
눈을 감은 등산가가 산 정상에 서 있다고 해봅시다. 목표는 가장 낮은 골짜기로 내려가는 거예요. 눈이 안 보이니까 지도도 못 봐요. 할 수 있는 건 딱 하나.
발 밑을 더듬어서, 지금 이 자리에서 가장 가파르게 내려가는 방향으로 한 발만 내딛는다.
한 발 내딛고, 또 발 밑을 더듬고, 또 가장 가파른 방향으로 한 발. 이걸 무한 반복.
이게 경사하강법(Gradient Descent) 이에요. AI 학습의 핵심 알고리즘이에요. 이름은 거창하지만 하는 일은 딱 이거예요. 현재 위치에서 가장 가파르게 내려가는 방향으로 한 걸음씩 옮기기.
근데 이 비유를 들으면서 솔직히 처음에 “산이 어디 있어요?”라고 생각했어요. 등산가는 알겠는데 산은요? 그게 막힌 첫 번째 지점이었어요. 그래서 산부터 잡고 갈게요.
산이 도대체 뭐예요?
산 = 틀린 정도(loss)의 풍경이에요.
다시 1-A편의 스팸 메일 모델로 돌아가 봅시다. 가중치가 3개 있었죠. 당첨 +2.0, 회의 -1.5, 느낌표 +0.3. 그런데 처음에는 이 숫자들을 모릅니다. 모를 수밖에 없어요. 학습 시작 전이니까. 랜덤으로 시작해요. 예를 들면 이렇게요.
처음 가중치: [당첨: 0.1, 회의: 0.1, 느낌표: 0.1] ← 아무거나
이 가중치로 정답이 있는 메일 1만 통을 돌려봅니다. 결과는 당연히 엉망이에요. “스팸인데 정상으로 분류”, “정상인데 스팸으로 분류”가 잔뜩 나와요.
이때 틀린 정도를 숫자로 셉니다.
1만 통 중에 5,234통 틀림 → 틀린 정도 = 5234
이 “5234”가 산의 높이예요. 가중치를 바꾸면 이 숫자가 바뀌어요.
가중치 [0.5, 0.1, 0.1] · 산 높이 4800 ← 한 걸음 내려옴
가중치 [1.2, -0.5, 0.2] · 산 높이 800 ← 더 내려옴
가중치 [2.0, -1.5, 0.3] · 산 높이 100 ← 거의 골짜기!
→ 가중치를 바꾼다 = 산 위에서 자리를 옮긴다.
→ 틀린 정도가 줄어든다 = 산을 내려간다.
학습이라는 건 결국 이거 한 줄이에요. 틀린 정도가 가장 작아지는 가중치를 찾는다 = 산의 가장 낮은 골짜기를 찾는다.
잠깐, 이거 학습 이야기예요? 추론 이야기예요?
여기서 제가 한 번 멈췄어요. 1-A편에서 “가중치는 학습이 끝나면 고정된다”고 했잖아요. 근데 지금 가중치를 바꾸고 있다는 거예요? 그럼 이게 학습 단계의 이야기인지 추론 단계의 이야기인지 헷갈려요.
이거 진짜 헷갈리는 지점이라 짚고 가야 해요. 답은 100% 학습 단계 이야기예요.
| 단계 | 무엇을 하나 | 가중치는? |
|---|---|---|
| 학습 (Training) | 데이터로 가중치를 만든다 | 계속 바뀜 |
| 추론 (Inference) | 만들어진 가중치로 사용한다 | 고정 (절대 안 바뀜) |
지금까지 한 “산 내려가기” = 학습 단계에서만 일어나는 일이에요.
ChatGPT를 우리가 쓸 때(이게 추론) 가중치는 한 비트도 안 바뀌어요. 이미 OpenAI가 학습 단계에서 다 정해놓은 그 80억 개(혹은 더 많은) 숫자가 그대로 박혀 있고, 우리 질문은 그 고정된 숫자들 사이를 한 번 통과해서 답을 만들어내는 거예요.
비유하면 이래요.
- 학습 = 요리 레시피를 수만 번 시행착오로 완성하는 과정
- 추론 = 완성된 레시피대로 한 번 요리하는 것
이 글에서 다루는 건 전부 학습 이야기예요. 추론은 3편에서 따로 다룰 거예요.
이걸 잡고 가야 다음이 안 헷갈려요. 가중치를 바꾸는 모든 이야기는 학습 단계 안에서만 일어나는 일.
발 밑을 어떻게 더듬는다는 거예요?
다시 등산가로 돌아와서. “발 밑을 더듬는다”가 실제로 뭐냐는 거예요.
답은 가중치를 아주 살짝 흔들어 보고, 틀린 정도가 어떻게 변하는지 본다예요.
구체적으로요.
지금 가중치: [당첨: 0.1, 회의: 0.1, 느낌표: 0.1] → 틀린 정도 5234
질문 1: "당첨" 가중치만 0.1 → 0.11로 살짝 올려보면?
실험: [0.11, 0.1, 0.1] → 틀린 정도 5230 (4 줄어듦!)
질문 2: "회의" 가중치만 0.1 → 0.11로 살짝 올려보면?
실험: [0.1, 0.11, 0.1] → 틀린 정도 5240 (10 늘어남!)
질문 3: "느낌표" 가중치만 0.1 → 0.11로 살짝 올려보면?
실험: [0.1, 0.1, 0.11] → 틀린 정도 5233 (1 줄어듦)
이 실험 결과가 “발 밑의 경사” 예요. 각 가중치를 미세하게 흔들었을 때 산 높이가 어떻게 변했는지.
- “당첨”은 올리면 산 높이가 확 줄어듦 → 더 올려야 함
- “회의”는 올리면 산 높이가 늘어남 → 반대로 내려야 함
- “느낌표”는 올리면 살짝 줄어듦 → 살짝만 올려야 함
이걸 한 번에 모든 가중치에 적용해서 한 걸음 내딛어요.
한 걸음 후: [당첨: 0.5, 회의: 0.05, 느낌표: 0.12] → 틀린 정도 4500
산이 5234 → 4500으로 내려왔어요. 한 걸음 성공.
가중치를 흔들었는데 산이 올라가버리는 경우는요?
이게 다음에 떠오른 질문이에요. “내려간다고만 했는데, 잘못해서 올라갈 수도 있는 거 아니에요?”
당연히 있어요. 사실 자주 있어요. 세 가지 경우로 나눠서 보면 좋아요.
첫 번째, 한 걸음이 너무 컸을 때.
발 밑 경사를 보고 “오른쪽이 내리막”이라고 판단해서 한 걸음 옮겼는데, 너무 큰 걸음이라 골짜기를 지나쳐 반대쪽 비탈로 올라가 버려요.
산 높이 변화:
5234 → 4500 → 3200 → 1500 → 800 → 200 → 1100 (앗, 올라가버림!)
↑
한 걸음이 너무 컸음
이걸 발산(diverge) 이라고 해요. 한 걸음의 크기를 학습률(learning rate) 이라고 부르는데, 이게 너무 크면 골짜기를 지나치고 너무 작으면 영영 못 도착해요. 학습률 조정이 AI 학습에서 가장 까다로운 부분 중 하나예요. 잠시 후에 더 자세히 다룰게요.
두 번째, 발 밑 측정 자체가 부정확할 때.
실제 학습은 1만 통 전부 보고 경사를 재는 게 아니라, 일부만 무작위로 뽑아서 경사를 재요. 표본이니까 경사 측정에 노이즈가 섞여요. 가끔 잘못 잰 경사 방향으로 한 걸음 옮기면 산 높이가 올라가요.
한 걸음마다:
4500 → 4200 → 4350 (살짝 올라감) → 4100 → 4000 → 4150 → 3800 ...
전체 추세는 내려가지만 중간중간 올라가요. 이게 정상이에요. 학습이 끝날 때까지 산 높이는 톱니 모양으로 진동하면서 점진적으로 낮아져요.
양자화 비트랑 학습률은 같은 거예요?
여기서 솔직히 헷갈렸어요. “한 걸음 크기를 미세하게 만들고 싶으면 양자화 비트수를 올리면 되나?” 이런 직감이 들었거든요. 1-A편에서 양자화라는 단어가 나왔으니까요.
아니에요. 둘은 완전히 다른 이야기예요. 짚고 갑시다.
- 학습 때 정밀도: 항상 32비트(또는 16비트)로 함. 가중치 한 개가 32비트짜리 소수예요. 이 정밀도라야 발 밑 경사를 정확히 재요.
- 양자화: 학습 다 끝난 뒤, 32비트로 저장된 가중치를 8비트나 4비트로 압축하는 작업이에요. 모델 파일을 작게 만들고 추론 속도를 올리려고 해요.
원본 (32비트): 0.347291482763
8비트 양자화: 0.35
4비트 양자화: 0.3
양자화 비트를 올리면 추론 시 가중치가 더 정밀하게 보존된다는 뜻이에요. 학습 중 한 걸음 크기와는 전혀 다른 이야기예요.
다시 정리하면.
- 학습률 (learning rate) = 학습 중 한 걸음 크기. 학습 단계의 일.
- 양자화 (quantization) = 학습 끝난 모델을 추론용으로 압축할 때 정밀도. 추론 단계의 일.
같은 “정밀도”라는 단어를 쓰지만 다른 단계의 이야기예요. 헷갈리지 마세요.
한 번에 80억 개를 다 흔드는 거예요?
다음 질문. 가중치가 80억 개라면, 80억 개를 하나씩 다 흔들어봐야 한다는 거예요? 그럼 한 번 산 내려가는 데 얼마나 걸려요?
여기가 진짜 마법이에요. 80억 개 가중치 전부의 경사를 한 번에 계산해서, 한 번에 동시에 한 걸음 옮겨요. 이게 가능한 이유는 역전파(backpropagation) 라는 알고리즘 덕분이에요.
역전파의 마법은 이거예요.
80억 개 가중치 각각을 하나씩 흔들어보지 않고도, 한 번의 계산 흐름으로 80억 개의 경사를 동시에 다 알 수 있다.
원리는 미분의 연쇄법칙(chain rule)인데, 수학을 빼고 직관만 말씀드릴게요. 이건 회사 부서 책임 추궁 비유로 풀면 잘 잡혀요.
역전파 = 회사 부서 책임 추궁
회사 분기 실적이 안 좋아서 책임 소재를 찾는다고 해봅시다.
원자재 → 생산부 → 가공부 → 조립부 → 마케팅부 → 매출
↓
매출 -1억 (목표 미달)
한 부서씩 거꾸로 추궁해 가요.
1단계, 마케팅부 추궁.
“매출 -1억의 직접 원인은 마케팅부야.” 마케팅부 책임 = 100%.
마케팅부 안의 직원 A·B·C·D 중 누구 책임인지 또 분해. A가 30%, B가 20%, C가 40%, D가 10%.
→ “마케팅부 100% 중 A가 30% → A의 진짜 책임 = 30%”
2단계, 마케팅부에 들어간 입력은 조립부 결과물이었지.
“마케팅부가 -1억을 만든 데에 조립부 입력이 70% 영향이었다.” → 조립부 책임 = 70%.
3단계, 조립부에 들어간 입력은 가공부 결과물.
조립부 70% 중 가공부 영향 50%. → 가공부 책임 = 70% × 50% = 35%.
4단계, 생산부.
가공부 35% 중 생산부 영향 80%. → 생산부 책임 = 35% × 80% = 28%.
이런 식으로 거꾸로 거슬러 올라가면서 책임을 곱셈으로 분해해요. 이게 체인 룰(chain rule) = “사슬처럼 책임이 이어진다”는 거예요.
LLM에서 똑같은 일이 일어나요.
입력 → 1층 → 2층 → … → 32층 → 출력 → 틀린 정도 100
[역방향 = 책임 추궁]
틀린 정도 100
↓ 32층에 분배
32층 가중치들 자기 몫 받음
↓ 31층에 분배 (32층 책임 × 31→32 영향)
31층 가중치들 자기 몫 받음
↓ … 계속 거슬러 올라감 …
↓
1층 도달 — 모든 80억 가중치가 자기 경사 받음
각 가중치가 “내가 틀린 정도에 얼마나 기여했나”라는 자기 경사를 받아요. 이 경사 방향의 반대로 한 걸음 옮기면 산이 내려가요.
신기한 건요. 80억 개를 따로따로 흔들지 않아도, 한 번의 곱셈 사슬 흐름으로 80억 개의 책임이 다 분배돼요. 라이프니츠와 뉴턴이 만든 미적분의 핵심이 이거였어요.
GPU는 이걸 어떻게 빠르게 해요?
여기서 GPU가 등장해요. 4096차원을 한 번에 다 조절한다고 해도, 1677만 개 곱셈(한 층 안의 가중치 수)을 어떻게 동시에 해요?
GPU의 본질을 짚고 갈게요.
- CPU = 한 번에 1개 계산을 매우 빠르게
- GPU = 한 번에 수천 개를 동시에 계산 (각각은 CPU보다 느려도 됨)
LLM 한 층의 4096 × 4096 = 1677만 개의 곱셈이 있는데, GPU는 이걸 수천 개씩 병렬로 끊어서 동시에 돌려요. 사람이 끊는 게 아니라 GPU가 알아서 해요.
1677만 개 곱셈
↓ GPU가 자동으로 분할
수천 개씩 동시 처리 → 수천 개씩 동시 처리 → ... (반복)
↓ 0.001초 후
완료
근데 여기서 또 한 가지 헷갈리는 게 있어요. “그럼 32층도 한 번에 할 수 있어요?”
답은 아니요. 층끼리는 순서대로예요.
이유는 역전파의 특성이에요. 32층 경사를 알아야 31층 경사를 알 수 있어요(체인 룰의 곱셈 사슬). 그래서 층은 순차적으로 거꾸로 풀어야 해요.
정리하면 이래요.
- 수학적으로: 한 층의 1677만 개 가중치는 동시에 처리됨
- 물리적으로: GPU가 수천 개씩 끊어서 처리하지만 너무 빨라서 사실상 동시
- 층끼리는?: 순서대로 (역전파 특성상)
층은 순차, 층 내부는 동시. 이렇게 잡으면 돼요.
한 step의 정체 — 솔직히 처음에 헷갈렸어요
여기서 진짜 중요한 게 있어요. 저도 처음에 한 step이 1층 처리하는 걸 말하는 줄 알았어요. 아니에요.
1 step = 데이터 한 묶음을 처음부터 끝까지 다 처리하고, 80억 가중치를 한 번 업데이트하는 것
세부 단계로 풀면 이래요.
[1 step의 내부]
1. 데이터 한 묶음 가져오기 (이걸 '미니배치'라고 해요)
2. 순방향: 1층 → 2층 → ... → 32층 → 출력
3. 틀린 정도 측정
4. 역방향: 32층 → 31층 → ... → 1층 (80억 경사 다 구함)
5. 80억 가중치 한 번에 업데이트
↑
여기까지가 1 step
한 층 처리 = step 아닙니다. 한 층 처리는 그냥 “1층 통과”일 뿐이에요. 32층 전부 통과 + 역전파 + 가중치 업데이트까지 다 끝나야 step 1번이에요.
이걸 잡고 나면 다음 충격이 와요. 이 1 step을 LLM은 수십만 ~ 수백만 번 반복해요.
| 모델 | 학습 step 수 (대략) |
|---|---|
| 작은 실험 모델 | 수만 ~ 수십만 |
| GPT-2 (15억) | 수십만 |
| LLaMA 2 (70억) | 약 50만 ~ 100만 |
| GPT-3 (1750억) | 수백만 |
| GPT-4 추정 | 수백만 ~ 수천만 |
수십만에서 수백만 번이에요. “몇만 번 정도?”라고 생각했다면 한 자릿수 더 위로 가야 해요.
이번 주 AI 흐름
미니배치 — 다 보면 안 돼요?
step 이야기에서 “미니배치”라는 단어가 나왔어요. 이게 뭐냐면 학습 데이터 전체에서 일부만 무작위로 뽑아서 한 step에 사용하는 것을 말해요.
전체 학습 데이터: 1조 개 토큰 (인터넷 텍스트 다)
미니배치: 그중 일부만 뽑아서 1 step에 사용
자연스럽게 의문이 생겨요. “왜 다 안 보고 일부만 봐요? 다 보면 더 정확하지 않아요?”
좋은 질문이에요. 이게 1960년대부터 50년 동안 고민됐던 진짜 문제예요. 세 가지 방식이 역사적으로 있었어요.
방식 A, 전체 다 보기 (Batch Gradient Descent).
– 1 step마다 1조 개 토큰 전부 계산
– 장점: 경사가 정확함 (노이즈 없음)
– 단점: 1 step에 수 시간 ~ 수일. 수백만 step 돌리면 우주가 끝남
방식 B, 1개씩 보기 (Stochastic Gradient Descent).
– 1 step마다 1개 토큰만 계산
– 장점: 한 step이 매우 빠름
– 단점: 경사가 너무 부정확 (1개로 산 전체 경사 추정?)
방식 C, 미니배치 (Mini-batch).
– 128개 ~ 수만 개씩 뽑아서 계산
– A의 정확성과 B의 속도 사이 균형
– 현재 표준
미니배치 크기는 누가 정하느냐. 사람(연구자)이 학습 시작 전에 정해요. 이런 걸 하이퍼파라미터(hyperparameter) 라고 해요.
파라미터 = 학습 중에 자동으로 정해지는 숫자 (= 가중치, 편향)
하이퍼파라미터 = 학습 시작 전에 사람이 정하는 숫자 (= 미니배치 크기, 학습률, 층 수 등)
“하이퍼”는 “위에 있다”는 뜻이에요. 가중치들 위에서 학습 자체를 조종하는 숫자들이라서요.
LLM 미니배치는 사실 어마어마하게 커요. 일반적인 직관에선 “128개 정도”라고 생각하기 쉬운데, 진짜 LLM은 한 step에 수백만 토큰을 봐요. LLaMA 같은 큰 모델은 미니배치가 약 400만 토큰이에요. 그래서 GPU가 수만 대 필요해요. 한 대로는 그 큰 미니배치를 메모리에 못 올려요.
또 한 가지 신기한 건, 미니배치 노이즈는 사실 도움이 돼요. 가짜 골짜기에 빠져도 노이즈 때문에 튕겨 나와서 진짜 골짜기로 굴러갈 수 있어요. 노이즈가 약이 되는 신기한 경우예요.
학습률 — 한 걸음의 크기
앞에서 발산 이야기할 때 잠깐 나왔던 거예요. 한 걸음의 크기, 학습률.
새 가중치 = 현재 가중치 - (학습률 × 경사)
↑
이 값이 학습률
너무 크면 발산, 너무 작으면 영영 못 도착. 그림으로 보면요.
학습률 너무 작음:
5234 → 5230 → 5226 → 5222 → ...
(영원히 골짜기에 못 도착)
학습률 적당:
5234 → 4500 → 3200 → 1500 → 800 → 200 → 100
(효율적으로 도착)
학습률 너무 큼:
5234 → 4500 → 1100 → 8000 → 50000 → ∞
(발산. 산을 뛰어넘어 더 높은 곳으로 튕겨나감)
여기서 진짜 신기한 게 있어요. 학습률은 학습 도중에 바꿔요.
학습 시작 (랜덤 가중치, 산 위쪽): 큰 학습률 (예: 0.001)
중반: 점점 줄임
끝물 (이미 골짜기 근처): 작은 학습률 (예: 0.00001)
이걸 학습률 스케줄(learning rate schedule) 이라고 해요. 비유하면, 산 위쪽에선 성큼성큼 빨리 내려오고, 골짜기 근처에선 작은 보폭으로 정밀하게 도착. 산악 등반의 상식과 똑같아요.
첫 학습률 자체는 어떻게 정하느냐. 선행 연구 참고하고, 작은 모델로 0.0001·0.0003·0.001·0.003 등 시도해보고, 경험으로 잡아요. GPT-4 같은 거대 모델은 첫 학습률 잘못 정하면 1억 달러를 그냥 날려요. 그래서 학습 시작 전에 작은 모델로 수많은 실험을 해요.
그럼 틀린 정도가 0이 될 때까지 학습하나요?
이게 자연스럽게 나오는 다음 질문이에요. “산을 끝까지 내려가면 0이잖아요? 0이 될 때까지 하면 되나요?”
아니에요. 0까지 가지 않아요. 가서도 안 돼요.
세 가지 이유가 있어요.
첫째, 0에 도달 불가능.
LLM의 산은 80억 차원 공간이에요. 그 안의 진짜 최저점(global minimum)은 우주가 끝나도 못 찾아요. 대신 “충분히 낮은 골짜기”에 도착하면 그걸로 끝내요.
둘째, 0이 되면 오히려 망가져요.
이게 진짜 중요한 개념이에요. 예시로 갈게요.
스팸 모델을 학습 데이터 1만 통으로 훈련하는데, 학습 데이터에서 틀린 정도 0까지 갔다고 해봐요. 모델이 1만 통을 100% 맞춰요. 완벽하죠?
그런데 새로운 메일 1통이 들어오면 처참하게 틀려요. 왜 그럴까요?
모델이 “스팸의 본질”을 배운 게 아니라, 그 1만 통의 사소한 특징까지 외워버린 거예요. 예를 들면요.
- “보내는 사람 이메일이 김xxx@… 으로 끝나면 스팸” ← 학습 데이터에선 우연히 그랬을 뿐
- “메일 길이가 정확히 327자면 정상” ← 우연히 그랬을 뿐
새 메일에는 이런 우연이 안 통하니까 와르르 무너져요. 이걸 과적합(overfitting) 이라고 해요.
비유하면 이래요. 시험 문제집을 외우면 그 문제집은 100점이지만, 진짜 시험에서는 망함. 외우지 말고 원리를 익혀야 함. 같은 거예요.
셋째, 그래서 학습은 항상 적당한 곳에서 멈춰요.
실제 학습은 두 가지 산 높이를 동시에 봐요.
학습 데이터 산 높이 (training loss)
검증 데이터 산 높이 (validation loss) ← 모델이 본 적 없는 새 데이터
학습이 진행될수록 학습 데이터 산 높이는 계속 내려가요. 그런데 검증 데이터 산 높이는요.
처음: 둘 다 같이 내려감 (잘 배우는 중)
중간: 학습 ↓, 검증도 ↓ (계속 좋아짐)
어느 순간: 학습 ↓, 검증 ↑ (외우기 시작 = 과적합)
검증 산 높이가 다시 올라가기 시작하는 순간 학습을 멈춰요. 이걸 조기 종료(early stopping) 라고 해요. 그 시점이 모델의 진짜 골짜기예요.
검증 데이터는 따로 빼두는 거예요?
네. 학습 시작 전에 미리 떼어둬요.
전체 데이터
├─ 학습용 (Training): 98% (9800억 개)
├─ 검증용 (Validation): 1% (100억 개)
└─ 테스트용 (Test): 1% (100억 개)
세 가지 데이터의 역할이 달라요.
- 학습용: 가중치를 직접 업데이트하는 데 사용. 모델이 본 데이터.
- 검증용: 학습 도중에 “지금 모델이 일반화 잘 되고 있나?” 체크. 모델이 본 적 없는 데이터(학습엔 안 씀). 검증 산 높이가 올라가기 시작하면 학습 멈춤.
- 테스트용: 학습 끝난 뒤 딱 한 번 쓰는 최종 시험. 검증용으로 하이퍼파라미터 조정하다 보면 검증 데이터에도 간접적으로 과적합 가능. 그래서 완전히 손도 안 댄 데이터를 따로 빼두고 마지막에 평가.
비유로 정리하면 이래요.
- 학습 데이터 = 평소 푸는 문제집
- 검증 데이터 = 모의고사
- 테스트 데이터 = 본 수능 (한 번뿐, 진짜 실력)
그럼 정답은 누가 매겨놨어요?
여기가 이번 편의 진짜 마법이에요. 자연스러운 질문이거든요. “인터넷 텍스트에 ‘이건 정답, 저건 오답’ 같은 표시가 있을 리가 없잖아요?”
답: 다음 단어가 정답이에요.
이걸 자기지도학습(self-supervised learning) 이라고 해요. 데이터 자체에서 정답이 자동으로 만들어져요.
어떻게 하느냐. 인터넷 문장 하나를 가져옵시다.
"오늘 날씨가 정말 좋다"
이걸 토큰으로 쪼개고, 앞부분을 입력 / 뒷부분을 정답으로 자동 생성해요.
입력: "오늘" → 정답: "날씨가"
입력: "오늘 날씨가" → 정답: "정말"
입력: "오늘 날씨가 정말" → 정답: "좋다"
한 문장에서 학습 데이터 3개가 자동으로 나와요. 사람이 라벨링 안 해요. 문장 자체가 정답을 품고 있어요.
학습이 진행되는 모습은 이래요.
입력: "오늘 날씨가 정말"
모델이 12만 8천 개 토큰 각각의 확률을 출력:
"좋다" → 23% ← 모델 예측
"많다" → 8%
"춥다" → 4%
"덥다" → 3%
...
정답: "좋다"
틀린 정도 = "좋다" 확률이 100%가 아닌 만큼 (예: 77만큼 틀림)
이 틀린 정도를 줄이려고 80억 가중치를 조정해요. 인터넷 문장 1조 개에 대해 이걸 반복하면, 모델이 다음 단어를 잘 예측하게 돼요. 이게 LLM 완성이에요.
다음 단어 예측 단 하나만으로 모델이 세상의 거의 모든 패턴을 배워요.
- “수도는 ___” → “서울”을 잘 예측 → 모델이 지리를 배움
- “1+1=___” → “2”를 잘 예측 → 모델이 산수를 배움
- “Pythagoras 정리는 ___” → 모델이 수학을 배움
- “오늘 기분이 안 좋다. 그래서 나는 ___” → 모델이 감정과 인과를 배움
다음 단어를 잘 맞추려면 결국 세상을 이해해야 한다는 게 LLM의 핵심 철학이에요.
자기지도가 혁명적인 이유는 사람 라벨이 0개라는 거예요. 인터넷 텍스트 그냥 쏟아붓기만 하면 돼요. GPT-3 학습 데이터가 약 5,000억 토큰, 책 수백만 권 분량이에요. 사람이 라벨링했다면 불가능했을 양이에요. 자기지도라서 가능했어요.
이 단순한 차이가 2017년 Transformer 등장 → 2020년 GPT-3 → 2026년 GPT-5.5까지 이어진 AI 혁명의 시작이에요.
그래서 — 학습은 결국 자본주의
자, 이제 큰 그림으로 가요.
지금까지 정리한 학습 한 사이클은 이래요.
미니배치 → 32층 순방향 → 틀린 정도 → 32층 역전파 → 80억 가중치 업데이트
↓
1 step 완료
이걸 수십만 ~ 수백만 번 반복.
이게 GPU 시간으로 환산하면 어떻게 될까요.
1 step ≈ 1~2초 (수천 GPU 동시)
전체 학습: 50만 step × 1~2초 = 1~3주
GPU 한 대로? 수십 년
GPT-4 (추정)
GPU 25,000개 × 90~100일 풀가동
전기: 약 50,000 MWh = 소도시 1년 전기
비용: 약 1억 달러 (1,400억 원) 추정
GPT-3 (2020)
전기: 약 1,287 MWh
= 한국 4인 가구 4,290가구의 한 달 전기
여기서 자연스럽게 산업 구조가 보여요.
H200 GPU 한 대 가격이 약 4,000만 원이에요. GPT-4 학습용 GPU 25,000대면 그것만으로 약 1조 원어치 GPU예요. 전기 따로, 냉각 따로, 데이터센터 부지 따로.
그래서 GPU를 많이 가진 회사가 LLM 개발 경쟁에서 이겨요. 자본이 곧 모델 성능이에요.
이게 지난 몇 년 동안 일어난 일들의 본질이에요.
- Anthropic ↔ AWS 1,000억 달러 10년 계약
- Google → Anthropic 400억 달러 투자
- NVIDIA 시가총액 4조 달러 돌파
- TSMC가 미국·일본에 새 팹 짓는 이유
- 데이터센터 전력 부족 → 미국 원전 재가동
- 애플이 하드웨어 출신 CEO를 고른 이유
전부 같은 흐름이에요.
AI 모델 경쟁
↓
GPU 경쟁 (반도체 경쟁)
↓
전력 경쟁 (원전·태양광·배터리·송전망)
↓
제조업·건설·소재 경쟁
그래서 지금 미래 산업을 보려면 AI·로봇·에너지 세 축을 같이 봐야 해요. 따로 보이지 않아요. 학습 1 step에 GPU 수천 대가 필요하다는 사실 하나에서 시작해서 전 세계 전력망 재편까지 한 줄로 이어져요.
1-A편을 읽으실 때만 해도 가중치는 그냥 신기한 숫자였을 거예요. 2편을 다 읽으신 지금은 가중치 80억 개를 만들기 위해 인류가 도시 하나의 전기를 태운다는 걸 아시게 됐어요. 이게 LLM을 이해한다는 것의 진짜 의미예요.
핵심 정리 — 3가지 포인트
이번 편 한 줄로 정리하면 이래요.
학습 = 80억 가중치를 데이터에 맞춰 산 내려가듯 조정하는 것. 그리고 이게 도시 하나의 전기를 먹는다.
좀 더 구체적으로요.
- 학습은 산 내려가기다. 산 = 틀린 정도(loss), 위치 = 가중치 값. 한 step = 미니배치 1개 + 32층 순방향 + 역전파 + 80억 가중치 한 번에 업데이트. 이걸 수십만~수백만 번 반복.
- 정답은 사람이 매기지 않는다. 다음 단어가 정답(자기지도학습). 그래서 인터넷 텍스트 1조 개를 사람 라벨 0개로 학습할 수 있다.
- 학습 = 자본·반도체·전력 경쟁. GPT-4 학습 1번 = 도시 1년 전기 = 1억 달러. AI 시장이 클라우드 빅테크의 자본 경쟁이 된 진짜 이유.
자주 묻는 질문
Q. 파라미터와 가중치는 동의어예요?
거의 동의어예요. 일상적으론 똑같이 써도 돼요. 엄밀하게는 파라미터 = 가중치 + 편향(bias). 가중치는 입력에 곱해지는 숫자, 편향은 곱한 결과에 더해지는 숫자예요. 가중치가 99% 이상이고 편향은 소수라서 일상 대화에선 같다고 봐도 무방해요.
Q. 양자화 비트와 학습 정밀도는 다른 거예요?
네. 학습 중에는 32비트(또는 16비트)로 정밀하게 계산하고, 학습 끝난 뒤에 추론용으로 8비트나 4비트로 압축하는 게 양자화예요. 학습 중 한 걸음 크기는 학습률이지 양자화가 아니에요.
Q. 층을 강화하면 더 빨리 0에 도달해요?
학습 데이터에서는 그래요. 그런데 그게 좋은 모델은 아니에요. 층/차원이 많을수록 외울 수 있는 양이 늘어나서 학습 데이터에선 빨리 0이 되지만, 검증 데이터에선 오히려 더 망가져요(과적합). 그래서 큰 모델은 데이터도 같이 어마어마하게 늘려야 해요. GPT-4가 잘 되는 이유 = 1조 가중치 + 그에 맞먹는 데이터. 둘이 맞아야 해요.
Q. “층을 강화한다”가 정확히 뭐예요?
두 가지로 해석돼요. (A) 층의 개수를 늘린다 (32층 → 64층). (B) 한 층을 더 두껍게 한다 (4096차원 → 8192차원). 둘 다 모델 표현력을 키우는 방법이고, 둘 다 가중치 개수가 늘어난다는 게 본질이에요. llama3-8b는 32층 × 4096차원, llama3-70b는 80층 × 8192차원이에요.
Q. AI 학습에 정말 그렇게 많은 전기가 들어요?
GPT-3 학습 1번 ≈ 1,287 MWh ≈ 한국 4인 가구 4,290가구의 한 달 전기. GPT-4는 그 40배. AI 산업이 클라우드 빅테크 자본 경쟁이 된 이유가 여기 있어요.
다음 편 예고
3편: 추론 (Inference)
학습이 끝난 모델이 어떻게 답을 만들어내는지. 가중치는 변하지 않는다는 그 사실이 추론 중에 어떻게 작동하는지. 그리고 우리가 ChatGPT에서 보는 “답이 한 글자씩 나오는” 그 현상의 정체까지 다룰 거예요.
그 이후로는 Attention(4편) → Transformer(5편) → 양자화·RAG·Fine-tuning(6편) 순서로 이어져요. 인코더와 디코더가 가중치를 어떻게 사용하는지도 거기서 본격적으로 다룰게요.
소스 / Sources
- Andrej Karpathy, “Intro to Large Language Models” — YouTube
- 3Blue1Brown, “Backpropagation, intuitively” — YouTube
- David Patterson et al., “Carbon Emissions and Large Neural Network Training” — arXiv:2104.10350
- Meta AI, “Llama 3 training report” — 공식 블로그
- “AI 붐은 왜 전력 문제로 이어지는가” — shuntailor.net
저자: VibeCoding Tailor (테이라)
shuntailor.net 운영. 고려대 공대생 · Lovable 공식 앰버서더. 고려대 캠퍼스타운 창업 경진대회 우수상으로 교내 창업사무실에 입주, 지금은 개발에 집중 중. 내가 IT·AI를 공부하며 막힌 지점은 모두가 막힐 지점이라는 가정으로, 그 막힘을 하나씩 깊이 파헤쳐 「쉽깊잼(쉽고·깊고·재미있게)」을 실현한다. 이 블로그는 AI 시대의 표준을 만들기 위해 시작한 미디어다.



