먼저 쉽게: 미래산업을 인체에 비유하면
미래산업을 처음 접하는 분을 위해 비유로 시작합니다.
사람의 몸을 떠올려 보세요. AI는 두뇌입니다. 생각하고 판단합니다. “이 이메일에 뭐라고 답할까”, “이 사진에서 불량품은 어디인가”——이런 판단을 내리는 역할입니다. 로봇은 손과 발입니다. 두뇌가 “저 물건을 집어”라고 판단하면, 실제로 팔을 뻗어서 집는 건 손입니다. 공장에서 용접하고, 조립하고, 물건을 옮기는 게 로봇의 역할입니다. 에너지는 혈액과 산소입니다. 두뇌가 아무리 똑똑하고 손발이 아무리 빨라도, 혈액이 산소를 공급하지 않으면 몸은 멈춥니다. 전기가 없으면 AI 서버도, 로봇 팔도 작동하지 않습니다.
셋 중 하나만 빼고 보면 어떻게 될까요? 두뇌(AI)만 보면 “모델이 똑똑해졌다”는 뉴스만 보입니다. 손발(로봇)만 보면 “데모 영상이 멋지다”만 보입니다. 혈액(에너지)만 보면 “발전소를 더 지어야 한다”만 보입니다. 하지만 세 가지를 같이 봐야 “산업이라는 몸 전체가 어떻게 움직이는지”가 보입니다.
이 글은 그 전체 그림을 펼치는 첫 번째 글입니다.
흔한 오해: “AI 뉴스만 따라가면 미래산업을 이해할 수 있다”
미래산업을 처음 공부하려는 사람이 가장 많이 하는 실수가 있습니다. AI 뉴스만 따라가는 것입니다. 모델 순위, 신제품 발표, CEO 발언——이것들만 보면 미래산업을 이해한 기분이 듭니다. 하지만 AI 기사를 깊이 따라가다 보면 결국 “데이터센터 전력이 부족하다”, “공장 자동화가 안 따라간다”, “로봇 도입 비용이 높다”라는 이야기를 만나게 됩니다. AI만 보고 있으면 이 물리 층의 제약은 보이지 않습니다.
이 글은 미래산업 카테고리의 첫 번째 글입니다. AI·로봇·에너지를 왜 하나의 연결 산업으로 봐야 하는지 설명하고, 이 카테고리에서 어떤 순서로 공부하면 되는지 안내합니다.
왜 이 오해가 생기는지도 이해할 수 있습니다. AI 뉴스는 매일 나오지만, 변압기 조달이나 인터커넥션 큐 같은 뉴스는 거의 보이지 않습니다. 뉴스의 빈도가 산업의 중요도와 비례한다고 착각하기 쉽습니다. 하지만 실제로는 뉴스에 자주 나오는 것(AI 모델 발표)이 산업의 표면이고, 뉴스에 거의 안 나오는 것(전력 장비 조달, 공장 자동화 경제학)이 산업의 속도를 결정하는 기반입니다. 이 시리즈는 그 기반까지 같이 보는 법을 알려줍니다.
왜 이 오해가 생기는지도 이해할 수 있습니다. AI 뉴스는 매일 나오고, 로봇 뉴스는 가끔 나오고, 에너지 인프라 뉴스는 거의 안 나옵니다. 뉴스의 빈도가 산업의 중요도와 비례한다고 착각하기 쉽습니다. 하지만 실제로는 뉴스에 자주 나오는 것(AI 모델 발표)이 산업의 표면이고, 뉴스에 거의 안 나오는 것(변압기 조달, 전력망 연결)이 산업의 속도를 결정하는 기반입니다.
이 시리즈는 그 “뉴스에 안 나오는 기반”까지 같이 보는 법을 알려줍니다.
숫자로 확인하기: AI만 보면 왜 부족한가
2024년 미국의 AI 민간 투자는 1,091억 달러를 기록했습니다(Stanford HAI AI Index Report 2025). 생성형 AI에만 339억 달러가 몰렸습니다. 기업의 AI 도입률은 78%입니다. 숫자만 보면 미래산업 = AI 산업이라는 생각이 자연스럽습니다.
하지만 이 숫자는 반만 보여줍니다. AI 산업이 실제로 돌아가려면 데이터센터가 필요하고, 데이터센터는 전력이 필요하고, 전력을 공급하려면 변압기와 전력망 연결이 필요합니다. 그리고 이 변압기의 조달 리드타임은 현재 2~3년입니다. AI 모델은 몇 달 만에 업데이트되지만, 그 모델을 돌릴 전력 인프라는 몇 년 단위로 움직입니다.
여기서 비자명한 포인트가 하나 있습니다. 미래산업의 속도를 결정하는 건 빠른 기술(모델, 소프트웨어)이 아니라 느린 층(전력망 연결, 장비 리드타임, 공장 건설)입니다. 빠른 뉴스만 보면 느린 층이 만드는 실제 병목이 보이지 않습니다.
미래산업의 두 가지 속도
빠른 층 (뉴스에 나오는 것)
AI 모델 업데이트: 수개월
소프트웨어 배포: 수일~수주
투자 발표: 수시
추론 비용 하락: 280배/2년
느린 층 (뉴스에 안 나오는 것)
변압기 조달: 2~3년
데이터센터 전력 연결: 수년
공장 건설·자동화 셀 구성: 1~3년
전력망 인터커넥션 큐: 수년 대기
빠른 기술 뉴스만 보면 느린 인프라가 만드는 실제 병목을 놓치게 된다
왜 AI·로봇·에너지를 같이 봐야 하는가——3층 구조
미래산업을 AI 하나로만 이해하려는 시도가 잘 안 되는 이유는, 이 산업이 세 개의 층으로 작동하기 때문입니다.
왜 “층”이라고 부르는가? 건물을 생각해 보세요. 1층(에너지)이 없으면 2층(로봇)을 올릴 수 없고, 2층이 없으면 3층(AI의 물리 실행)이 불가능합니다. 동시에, 3층(AI)의 판단이 좋아져야 2층(로봇)이 더 효율적으로 움직이고, 2층의 수요가 늘어야 1층(에너지)의 투자가 정당화됩니다. 위에서 아래로 의존하고, 아래에서 위로 수요를 밀어 올리는 구조입니다.
각 층이 무엇을 하는지, 왜 하나만 빼도 안 되는지를 구체적으로 봅니다.
1층: AI는 판단을 바꾼다
AI는 소프트웨어 작업을 재구성하는 범용 지능 층입니다. 쉽게 말해, 사람이 하던 “판단”을 기계가 대신하거나 도와주는 기술입니다.
구체적으로 어떤 판단을 바꾸나요?
- 코딩: Claude Code나 Cursor 같은 도구가 개발자 대신 코드를 쓰고 수정합니다. 개발자는 “무엇을 만들지” 판단하고, AI가 “어떻게 만들지”를 실행합니다.
- 리서치: 논문 수백 편을 읽고 요약하는 작업을 AI가 몇 분에 합니다. 사람은 “어떤 질문을 할지” 판단하고, AI가 “답을 찾는 과정”을 실행합니다.
- 품질 검사: 공장 생산 라인에서 불량품을 찾는 작업을 컴퓨터 비전이 담당합니다. 사람 눈보다 빠르고 일관됩니다.
- 의사결정 보조: 데이터 분석, 예측, 패턴 인식을 AI가 수행해서 사람의 판단을 돕습니다.
2024년 미국의 AI 민간 투자 1,091억 달러, 기업 도입률 78%, GPT-3.5급 추론 비용 280배 하락——이 숫자들은 AI가 “실험실의 기술”에서 “산업의 기반”으로 이동하고 있다는 뜻입니다.
왜 “추론 비용 280배 하락”이 산업 전체를 바꾸는가
이 숫자를 그냥 지나치기 쉽습니다. 하지만 280배 하락이 실제로 무엇을 의미하는지 풀어 봅니다.
2022년 말에 GPT-3.5 수준의 AI를 한 번 호출하는 데 1원이 들었다고 합시다. 2024년 10월에는 같은 품질의 호출이 약 0.004원이 됩니다. 이 차이가 왜 중요한가?
비용이 내려가면 사용량이 폭발합니다. 1원짜리 AI를 100번 쓸 수 있는 예산으로, 0.004원짜리 AI를 25,000번 쓸 수 있습니다. 그래서 추론 비용이 내려가면 “더 저렴하게 쓴다”가 아니라 “폭발적으로 더 많이 쓴다”가 됩니다.
여기서 중요한 메커니즘이 작동합니다. 경제학에서 제본스 역설(Jevons Paradox)이라고 부르는 현상입니다. 기술이 효율적이 되면 비용이 줄어서 덜 쓸 것 같지만, 실제로는 싸진 만큼 더 많이 써서 총 소비가 오히려 늘어납니다.
쉬운 비유: LED 전구가 백열등보다 전기를 90% 적게 씁니다. 하지만 LED가 싸지면서 사람들이 집 안에 조명을 10배 더 많이 달았습니다. 결과적으로 조명용 전력 소비는 줄지 않았습니다.
AI도 같습니다. 추론 비용이 280배 내려가면, 기업들은 “이제 AI를 아껴서 쓰자”가 아니라 “모든 곳에 AI를 넣자”가 됩니다. 그래서 추론 비용 하락은 → 사용량 폭발 → 데이터센터 수요 급증 → 전력 수요 급증으로 이어집니다. AI 모델이 좋아지는 건 소프트웨어 이야기지만, 그 결과는 전력과 인프라라는 물리 세계의 문제가 됩니다.
이것이 “AI만 보면 안 되는” 첫 번째 이유입니다. AI의 성공이 에너지 문제를 만들고, 에너지 문제가 AI의 확장 속도를 제한합니다. 좋은 소식(비용 하락)이 새로운 문제(인프라 부족)를 만드는 이 순환을 이해하는 것이, 미래산업을 피상적으로 읽는 것과 구조적으로 읽는 것의 차이입니다.
2편에서는 이 메커니즘을 AI 산업 안에서 더 자세히 봅니다. AI 산업을 모델 랭킹이 아니라 R&D, 인프라, 추론 비용, 배포, 운영, 거버넌스의 6개 층으로 분해하면, “AI 기사를 읽고 5분에 끝내는 것”이 “15분 읽고 산업 구조를 이해하는 것”으로 바뀝니다.
하지만 AI만 보면 놓치는 것이 있습니다. AI 모델이 아무리 똑똑해도, 그 모델을 대규모로 돌리는 데이터센터가 없으면 서비스가 안 됩니다. 데이터센터를 지으려면 전력이 필요합니다. 그래서 AI를 제대로 이해하려면 “아래층”인 에너지를 같이 봐야 합니다.
개발자/전문가가 놓치기 쉬운 포인트
개발자는 모델 성능(accuracy)에 집중하지만, 산업적으로는 추론 비용(cost per inference)이 더 큰 변수입니다. 정확도 95%→97% 개선보다 비용 $0.01→$0.001 하락이 시장 크기를 10배 바꿉니다. SaaS 개발자가 “기능 추가”보다 “가격 인하”가 사용자 수를 더 크게 바꾸는 것과 같은 원리입니다. AI 모델 개발에서도 FLOPs당 성능이 아니라 “달러당 유용한 추론 횟수”가 실질적 KPI가 되어 가고 있습니다. 이것은 기술의 성공 지표가 연구실(정확도)에서 시장(비용 효율)으로 이동했다는 뜻입니다.
2층: 로봇은 판단을 물리 작업으로 옮긴다
AI가 판단을 내리면, 누군가가 그 판단을 실제 물리 세계에서 실행해야 합니다. 그 역할을 하는 것이 로봇입니다.
구체적으로 어떤 물리 작업인가요?
- 용접: 자동차 공장에서 차체 부품을 이어붙입니다. 사람보다 정확하고 쉬지 않습니다.
- 조립: 스마트폰, 전자제품의 부품을 정해진 순서대로 끼워 넣습니다.
- 검사: 완성된 제품의 크기, 모양, 표면 상태를 확인합니다.
- 자재 이송: 공장 안에서 부품과 완성품을 정해진 경로로 옮깁니다. AGV(무인운반차)가 대표적입니다.
2024년 전 세계 산업용 로봇 신규 설치는 54만 2천 대, 가동 재고는 466만 4천 대입니다(IFR World Robotics 2025). 이 중 74%가 아시아에 설치됐습니다. 한국은 로봇 밀도 세계 1위(노동자 1만 명당 1,012대)입니다.
이 숫자에서 읽어야 할 것: 로봇 산업은 “앞으로 올 미래”가 아니라 이미 수백만 대가 돌아가는 거대한 현재입니다. 휴머노이드 기사를 읽을 때마다 “로봇 산업이 시작된다”는 표현을 보지만, 산업용 로봇은 진작부터 돌아가고 있습니다. 휴머노이드는 이 거대한 설치 기반 위에 새로 쌓이는 층이지, 제로에서 출발하는 독립 시장이 아닙니다.
466만 대라는 숫자가 왜 중요한가——”설치 기반 시장”의 의미
“466만 대”를 그냥 큰 숫자로 넘기기 쉽습니다. 하지만 이 숫자는 로봇 산업을 읽는 핵심 열쇠입니다.
설치 기반(installed base)이란, 이미 현장에 깔려서 돌아가고 있는 장비의 총량입니다. 스마트폰으로 비유하면, “올해 팔린 스마트폰 수”가 아니라 “현재 전 세계에서 쓰이고 있는 스마트폰 총 대수”입니다.
설치 기반이 왜 중요한가?
- 부품과 서비스 시장이 따라옵니다. 466만 대의 로봇이 매년 부품 교체, 소프트웨어 업데이트, 유지보수를 필요로 합니다. 이 시장만 해도 엄청난 규모입니다.
- 새 기술의 진입 장벽이 됩니다. 휴머노이드가 들어오려면, 기존 466만 대가 “못하는 일”을 더 싸고 안정적으로 해야 합니다. 기존 장비보다 비싸거나 불안정하면 교체 이유가 없습니다.
- 산업 표준이 이미 만들어져 있습니다. 안전 규격, 통신 프로토콜, 프로그래밍 방식이 466만 대를 기준으로 형성돼 있습니다. 새 로봇이 이 표준을 따르지 않으면 기존 공장에 들어갈 수 없습니다.
그래서 휴머노이드 뉴스를 볼 때 “와, 사람처럼 움직인다”가 아니라 “이 로봇이 466만 대 기존 장비가 하는 일 중 어떤 부분을 더 잘할 수 있는가?”를 먼저 봐야 합니다. 이것이 3편에서 자세히 다루는 내용입니다.
그리고 이 466만 대의 로봇이 돌아가려면 전기가 필요합니다. 로봇의 가동 패턴이 곧 공장의 전력 소비 패턴이 됩니다. 로봇 수백 대가 동시에 가동하면 전력 피크가 치솟고, 교대 시간에는 전력이 빠집니다. 이 피크와 골짜기를 관리하는 것이 5편에서 다루는 배터리 저장의 역할입니다. 그래서 로봇을 이해하려면 “아래층”인 에너지를 같이 봐야 합니다.
3층: 에너지는 둘의 속도를 결정한다
AI가 판단을 내리고, 로봇이 실행합니다. 하지만 둘 다 전기 없이는 작동하지 않습니다. 에너지는 AI와 로봇의 “속도 제한 층”입니다.
이것을 이해하려면 구체적인 숫자를 봐야 합니다.
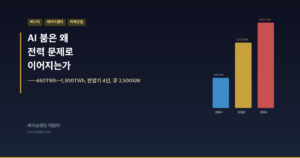
데이터센터 전력 수요: IEA에 따르면 전 세계 데이터센터 전력 소비는 2024년 460TWh에서 2035년 1,300TWh로 약 3배 늘어납니다. 1,300TWh는 한국 전체 연간 전력 소비(약 580TWh)의 2배가 넘는 양입니다.
왜 전력이 병목인가: 전기를 만드는 것(발전)은 상대적으로 빠릅니다. 하지만 만든 전기를 데이터센터나 공장까지 보내는 장비(변압기, 케이블, 전력망 연결)가 느립니다.
- 변압기는 전기의 전압을 바꾸는 장치입니다. 발전소에서 만든 고압 전기를 공장이나 데이터센터에서 쓸 수 있는 전압으로 낮춰줍니다. 이 대형 변압기의 제조 리드타임이 현재 최대 4년입니다.
- 인터커넥션 큐는 전력망에 연결하려는 시설(발전소, 데이터센터 등)의 대기줄입니다. 현재 전 세계에서 2,500GW 이상의 프로젝트가 줄을 서고 있습니다.
- 데이터센터는 1~3년이면 짓지만, 전력을 연결하는 데 5~15년이 걸릴 수 있습니다.
왜 “발전량”이 아니라 “연결”이 진짜 병목인가
“전기가 부족하다”고 하면 보통 “발전소를 더 지으면 되지 않나?”라고 생각합니다. 하지만 실제 병목은 발전이 아니라 연결에서 먼저 나타납니다. 이것을 단계별로 풀어 봅니다.
1단계: 전기를 만든다 (발전). 태양광 패널을 깔거나, 풍력 터빈을 세우거나, 가스 터빈을 돌려서 전기를 만듭니다. 이 단계는 상대적으로 빠릅니다. 태양광 발전소는 1~2년이면 짓습니다.
2단계: 전기를 보낸다 (송전). 만든 전기를 수백 km 떨어진 도시나 산업단지까지 보내야 합니다. 고압 송전선, 변전소, 변압기가 필요합니다. 이 장비들은 대형이고 무겁고, 제조에 수년이 걸립니다.
3단계: 전기를 내려준다 (배전). 도시나 산업단지 안에서 각 건물, 공장, 데이터센터에 적합한 전압으로 바꿔서 전달합니다. 이것도 변압기와 배전 설비가 필요합니다.
병목은 2단계와 3단계에서 생깁니다. 왜?
- 변압기는 맞춤 제작품입니다. 대형 변압기는 공장에서 찍어내는 표준 제품이 아닙니다. 각 설치 위치의 전압, 용량, 크기에 맞춰 주문 제작합니다. 무게가 수백 톤에 달해서 특수 운송 장비가 필요합니다. 그래서 제조에 최대 4년이 걸립니다.
- 송전선은 땅을 지나갑니다. 송전선을 깔려면 토지 허가, 환경 심사, 지역 주민 동의가 필요합니다. 기술적으로는 6개월이면 깔 수 있는 선이, 허가 절차 때문에 5~10년이 걸리기도 합니다.
- 인터커넥션 큐는 선착순입니다. 전력망에 연결하려는 발전소, 데이터센터, 저장 시설이 줄을 서서 기다립니다. 현재 전 세계에서 2,500GW 이상이 대기 중인데, 큐를 처리하는 속도가 프로젝트가 쌓이는 속도를 따라가지 못합니다.
수도관 비유로 다시 설명합니다. 수도꼭지(발전소)는 충분한데, 수도관(변압기, 전력선)이 가늘어서 물이 느리게 나옵니다. 수영장(데이터센터)은 이미 만들어졌는데, 굵은 수도관을 설치하려면 3~5년 걸립니다. 이 “수도관 병목”이 AI와 로봇의 확장 속도를 실제로 결정합니다.
이 메커니즘을 숫자로 정리하면:
| 항목 | 소요 시간 | 왜 이렇게 오래 걸리나 |
|---|---|---|
| 태양광 발전소 건설 | 1~2년 | 표준화된 모듈 설치 |
| 데이터센터 건설 | 1~3년 | 건물+서버+냉각 설치 |
| 케이블 조달 | 2~3년 | 구리/알루미늄 원자재+제조 |
| 대형 변압기 제조 | 최대 4년 | 맞춤 설계+특수강+조립+운송 |
| HVDC 케이블 | 5년+ | 해저/장거리 특수 케이블 |
| 전력망 전체 구축 | 5~15년 | 토지 허가+환경 심사+장비 조달+시공 |
IEA는 이 격차를 메우기 위해 연간 전력망 투자를 현재 약 4,000억 달러에서 약 6,000억 달러로(50% 증가) 끌어올려야 한다고 추정합니다. 부족한 2,000억 달러는 발전소가 아니라 “만든 전기를 보내는 인프라”에 필요한 투자입니다.
IEA Electricity 2025에 따르면, 중국에서 “신에너지 제품”(배터리, 태양광 모듈, EV) 제조에 사용되는 전력만 연간 300TWh를 넘습니다. 미국에서는 데이터센터와 반도체 팹이 새로운 대형 전력 부하로 떠오르고 있습니다. 에너지 문제는 AI와 로봇 양쪽 모두의 확장 속도를 결정합니다.
미래산업 3층 구조——서로를 밀어 올리고 서로를 제한한다
세 층 중 하나만 빼고 보면 미래산업의 실제 속도와 병목을 놓치게 된다
개발자/전문가가 놓치기 쉬운 포인트
클라우드 개발자는 “scale-up = 서버 추가”라고 생각합니다. kubectl scale –replicas=100 한 줄이면 됩니다. 하지만 물리 인프라에서 scale-up은 “변압기 추가”이고, 리드타임이 최대 4년입니다. 소프트웨어의 스케일링 시간 단위(분~시간)와 하드웨어의 스케일링 시간 단위(년)가 근본적으로 다릅니다. 이 간극을 이해하지 못하면 “GPU만 늘리면 AI가 더 빨라진다”는 오해에 빠집니다. 실제로 hyperscaler들이 겪는 최대 병목은 컴퓨팅이 아니라 전력 인프라 확보입니다. AWS, Google, Microsoft가 원자력 발전소 계약을 맺는 이유가 여기에 있습니다.
메커니즘: 세 축은 구체적으로 어디에서 만나는가
AI, 로봇, 에너지가 따로 떠오르는 별개의 시장이라면 굳이 같이 볼 이유가 없습니다. “AI는 AI끼리, 로봇은 로봇끼리, 에너지는 에너지끼리 보면 되지 않나?” — 이렇게 생각할 수 있습니다.
하지만 실제로는 이 셋이 같은 물리 공간에서 만나고, 서로의 속도를 제한합니다. 별도의 시장이 아니라 같은 공장, 같은 전력망, 같은 산업단지에서 부딪칩니다.
하나의 장면으로 봅니다. 충청남도 서산에 배터리 공장이 들어섰다고 합시다. 이 공장은 전기를 대량으로 씁니다(에너지). 공장 안에는 산업용 로봇 수백 대가 배터리 셀을 조립합니다(로봇). AI가 공정을 최적화하고 불량을 검출합니다(AI). 그리고 같은 산업단지에 데이터센터도 있습니다. 이 데이터센터도 전기를 대량으로 씁니다. 배터리 공장과 데이터센터가 같은 변전소에서 전기를 받습니다. 변전소의 용량이 부족하면 둘 중 하나가 기다려야 합니다.
이것이 “같은 물리 공간에서 만난다”의 실체입니다. 추상적 개념이 아니라 같은 변전소, 같은 전력선, 같은 산업단지 안에서 벌어지는 물리적 경쟁입니다. 그 만남의 구조를 3가지로 분해합니다.
1. 같은 전력망에 동시에 부하를 건다
이것을 이해하는 가장 쉬운 방법은 “한 동네의 전기 콘센트”를 생각하는 겁니다.
한 산업단지에 배터리 공장, 반도체 팹, 데이터센터가 동시에 들어선다고 합시다. 세 시설 모두 대형 전력 소비자입니다. 배터리 공장 하나가 소규모 도시 수준의 전기를 씁니다. 반도체 팹도 마찬가지입니다. 데이터센터도 마찬가지입니다.
문제는, 이 세 시설이 같은 전력망에 연결돼 있다는 점입니다. 전력망의 용량은 유한합니다. 변압기 하나를 배터리 공장이 가져가면, 같은 지역의 데이터센터는 다음 변압기를 기다려야 합니다. 그리고 그 다음 변압기가 도착하는 데 최대 4년이 걸립니다.
쉬운 비유: 한 집에 콘센트가 3개인데, 에어컨·전기 히터·전기 오븐을 동시에 켜면 차단기가 내려갑니다. 산업 규모에서 같은 일이 벌어지고 있습니다. “콘센트를 더 만들려면”(변압기·전력선 증설) 수년이 걸립니다.
구체 숫자로 보면: IEA에 따르면 전 세계 데이터센터 전력만 2024년 460TWh에서 2035년 1,300TWh로 증가합니다. 여기에 배터리 공장 전력(중국만 300+TWh), 반도체 팹 전력, EV 충전 인프라 전력이 동시에 늘어납니다. 이 모든 수요가 같은 전력망의 같은 변압기와 같은 인터커넥션 큐를 통해 연결돼야 합니다.
한 지역에 배터리 공장과 데이터센터가 동시에 들어서면, 둘 다 변전소 용량 확대를 요청합니다. 하지만 변전소의 변압기 교체에는 3~4년이 걸립니다. 누가 먼저 연결되느냐가 누가 먼저 가동하느냐를 결정합니다. 이것이 “같은 전력망 경쟁”의 실체입니다.
개발자/전문가가 놓치기 쉬운 포인트
마이크로서비스 아키텍처에서 리소스 경쟁(CPU/memory contention)을 경험한 개발자라면 이 구조가 익숙할 것입니다. Kubernetes 클러스터에서 여러 Pod가 같은 노드의 CPU를 두고 경쟁하듯, 전력망의 변압기 용량 경쟁은 같은 구조의 물리 세계 버전입니다. 차이점은 k8s에서는 노드를 추가하면 되지만, 전력망에서는 변전소를 추가하는 데 수년이 걸린다는 것입니다. “noisy neighbor” 문제가 클라우드에서는 VM 마이그레이션으로 해결되지만, 전력망에서는 해결할 수 없습니다. 물리 세계에는 live migration이 없습니다.
2. 공장이 세 축의 교차점이 된다
배터리 공장을 구체적으로 봅시다.
- 에너지 측면: 배터리를 만드는 공정(전극 코팅, 건조, 충방전 테스트)이 대량의 전기를 씁니다. 공장 자체가 소도시급 전력 소비자입니다.
- 로봇 측면: 공장 안에 수백 대의 산업용 로봇이 셀 조립, 품질 검사, 자재 운반을 합니다. 이 로봇들의 가동 패턴이 공장의 전력 소비 프로파일을 결정합니다.
- AI 측면: 공정 최적화(수율 개선), 품질 검사(컴퓨터 비전), 에너지 관리(디지털 트윈으로 전력 사용 최적화)에 AI가 들어갑니다.
왜 공장이 “교차점”이 되는가——세 축의 비용이 한 곳에서 결정된다
공장이 교차점이 되는 근본적인 이유는, 세 축의 비용이 공장이라는 물리 공간에서 동시에 결정되기 때문입니다.
- 배터리 공장의 생산 비용 = 원자재 비용 + 전력 비용(에너지) + 자동화 효율(로봇) + 공정 최적화(AI)
- 반도체 팹의 수율 = 장비 정밀도(로봇·자동화) + 결함 검출(AI) + 24시간 안정 전력(에너지)
- 데이터센터의 운영 비용 = 서버 전력(에너지 60%) + 냉각(에너지 25%) + 자동 모니터링(AI) + 자재 관리(로봇)
어느 시설이든, 최종 경쟁력은 AI·로봇·에너지 세 축의 조합으로 결정됩니다. 하나만 잘한다고 공장이 잘 돌아가지 않습니다. 전력이 불안하면 수율이 떨어지고, 자동화가 약하면 인건비가 올라가고, AI가 없으면 공정 최적화가 안 됩니다. 공장은 세 축의 성적표가 한 장소에서 합산되는 곳입니다.
이 공장에서 만들어진 배터리는 어디로 갈까요? 일부는 전기차에 들어갑니다. 일부는 태양광 발전소 옆의 에너지 저장 시설에 들어갑니다. 일부는 다른 데이터센터의 피크 전력을 완충하는 데 쓰입니다. 즉, 공장의 제품(배터리)이 다른 곳의 에너지 인프라가 됩니다.
같은 구조가 반도체 팹에서도 반복된다
반도체 팹(fabrication plant)을 같은 프레임으로 봅니다.
- 에너지 측면: 반도체 팹은 24시간 365일 가동됩니다. 순간이라도 전기가 끊기면 제조 중인 웨이퍼가 전부 불량이 됩니다. 그래서 이중 전력 공급, 대형 UPS(무정전전원), 자체 발전기가 필수입니다. 팹 하나의 전력 소비는 소도시급입니다.
- 로봇 측면: 클린룸 안에서 웨이퍼를 옮기는 것은 사람이 아니라 자동 반송 시스템(AMHS)입니다. 수백 대의 반송 장비가 24시간 움직입니다. 이 장비의 가동률이 곧 팹의 생산성입니다.
- AI 측면: 반도체 공정은 수백 단계입니다. 각 단계에서 AI가 결함을 검출하고, 공정 파라미터를 최적화하고, 수율(양품률)을 예측합니다. 수율 1%의 차이가 수백억 원의 매출 차이를 만듭니다.
그리고 이 반도체 팹에서 만든 칩이 어디로 가는가? AI 서버의 GPU에 들어갑니다. AI 서버가 데이터센터에서 돌아갑니다. 데이터센터가 전기를 대량으로 씁니다. 그 전기를 공급하는 전력망에 반도체 팹도 연결돼 있습니다. 제품을 만드는 곳과 제품이 쓰이는 곳이 같은 인프라를 공유하는 순환 구조입니다.
데이터센터도 사실 “공장”이다
데이터센터를 “서버를 쌓아 놓은 건물”로 생각하기 쉽지만, 실제로는 AI 서비스를 제조하는 공장에 더 가깝습니다.
- 서버 랙을 “생산 라인”처럼 배치합니다
- 냉각 시스템이 공장의 환경 관리 시스템과 같은 역할을 합니다
- 전력 변환·분배 시스템이 공장의 유틸리티 시스템과 동일합니다
- 가동률(uptime)이 공장의 가동률처럼 핵심 지표입니다
4편에서 자세히 다루지만, 데이터센터의 전력 구성은 서버 ~60%, 냉각 ~25%, 전력 변환 ~10%, 기타 ~5%입니다. 서버만 보면 전력의 60%만 보입니다. 나머지 40%가 “공장의 유틸리티”에 해당합니다.
이런 구조가 배터리 공장, 반도체 팹, 데이터센터, 태양광 모듈 공장에서 모두 반복됩니다. 미래산업의 실제 결절점은 앱 화면이 아니라 이런 물리 설비가 모이는 공장과 전력망입니다. 이것이 6편에서 “미래산업의 진짜 현장은 제조업이다”라고 말하는 이유입니다.
개발자/전문가가 놓치기 쉬운 포인트
풀스택 개발자가 프론트엔드·백엔드·DB를 모두 다루듯, 미래의 스마트 팩토리 엔지니어는 AI 모델 배포(MLOps) + 로봇 제어(ROS/PLC) + 에너지 관리(SCADA/디지털 트윈)을 동시에 다뤄야 합니다. 세 기술 스택이 하나의 공장이라는 런타임 위에서 동시에 돌아가기 때문입니다. 로봇의 동작 패턴이 전력 소비 프로파일을 바꾸고, AI의 추론 결과가 로봇의 동작 패턴을 바꿉니다. 이 피드백 루프를 이해하지 못하면 각 시스템을 따로 최적화하게 되고, 전체 효율은 오히려 떨어집니다.
3. 병목은 “만들기”가 아니라 “연결하기”에서 생긴다
새 기술의 “가능성”은 빠르게 발표됩니다. 하지만 그 기술을 실제 산업으로 만드는 속도는 물리 인프라에 의해 제한됩니다.
구체적 예시:
- 발표: “○○ 기업이 데이터센터에 10조 원을 투자한다” — 이건 뉴스에 나옵니다.
- 현실: 그 데이터센터가 들어설 지역의 인터커넥션 큐에 이미 수십 개의 대형 프로젝트가 대기 중입니다. 변전소의 변압기 교체 리드타임은 3년입니다. 10조 원을 발표했지만, 실제로 전기가 연결되는 시점은 발표로부터 3~5년 뒤입니다.
즉, 투자 발표(capex announcement) ≠ 실제 가동(energized capacity)입니다. 이 간극을 아는 것과 모르는 것이 미래산업을 읽는 깊이의 차이를 만듭니다.
변압기 하나가 2년 걸리면, 10조 원짜리 데이터센터도 2년을 기다립니다. 인터커넥션 큐에 5년 대기면, 5조 원짜리 배터리 공장도 5년을 기다립니다. 새 기술의 가능성보다, 실제 연결 가능 시간과 장비 리드타임이 산업 속도를 더 크게 좌우합니다.
이 구조를 이해하면 뉴스 읽는 법이 바뀝니다:
| 뉴스에서 보이는 것 | 실제로 확인해야 할 것 | 왜 다른가 |
|---|---|---|
| “10조 원 투자 발표” | “언제 전력이 연결되는가?” | 돈 ≠ 전기. 투자는 즉시, 연결은 수년 |
| “공장 착공” | “변압기는 발주했는가?” | 건물은 2년, 변압기는 4년 |
| “AI 서비스 확장 계획” | “데이터센터 전력은 확보됐는가?” | 모델 업데이트는 수개월, 전력 연결은 수년 |
| “배터리 공장 신설” | “인터커넥션 큐에 몇 년 대기인가?” | 발표는 즉시, 큐 대기는 수년 |
이 표를 머릿속에 넣어 두면, 같은 뉴스를 읽어도 “와, 대단하다”에서 끝나지 않고 “실제로 언제 돌아갈 수 있는가?”를 판단할 수 있게 됩니다. 이것이 이 시리즈 전체에서 반복되는 핵심 읽기 방법입니다.
매주 월요일, AI·미래산업 뉴스레터 발행 중
AI 도구부터 로봇·전력·제조 인프라까지, hype와 실체의 경계를 짚는 해설을 보내드립니다.
배너 광고 없는 깨끗한 AI 전문 미디어입니다.
개발자/전문가가 놓치기 쉬운 포인트
소프트웨어 엔지니어링에서 “통합(integration)이 개발보다 어렵다”는 것은 상식입니다. 모듈을 각각 만드는 건 쉽지만 합치는 데서 버그가 터집니다. 물리 산업에서도 똑같습니다. 배터리 셀을 만드는 것보다 전력망에 공장을 연결하는 것이 병목이고, GPU를 조달하는 것보다 데이터센터에 전력을 공급하는 것이 병목입니다. API 연동에서 겪는 인증·호환성·레이턴시 문제가, 물리 인프라에서는 변압기·인터커넥션 큐·규제 승인이라는 형태로 나타납니다. 해결 시간 단위만 다를 뿐, 구조는 동일합니다.
대표 장면: AI 기사 하나가 세 축으로 번지는 순간
추상적인 설명이 아니라, 실제로 뉴스를 읽는 과정을 따라가 봅니다.
Before: AI 뉴스만 따라가고 있었습니다. “OpenAI가 새 모델을 냈다”, “NVIDIA가 새 GPU를 발표했다”——이런 기사를 읽고 미래산업을 이해한다고 생각했습니다. 기사를 읽는 시간은 5분이면 끝났고, “대단하다” 혹은 “별로다”로 판단이 끝났습니다.
전환점: 어느 날 AI 데이터센터 확장 기사를 읽다가 “전력 공급이 안 돼서 완공이 지연된다”는 문장을 만났습니다. 처음에는 무슨 뜻인지 잘 몰랐습니다. 더 읽어보니, 그 기사 안에 변압기 부족, 인터커넥션 큐 대기, 냉각수 확보 문제가 나왔습니다.
거기서 한 발짝 더 가면 이런 연결이 보입니다:
- “이 데이터센터가 쓸 전기를 만드는 태양광 발전소 옆에는 배터리 저장 시설이 있다” — 에너지
- “이 데이터센터를 짓는 공장에서는 산업용 로봇이 자재를 옮기고 있다” — 로봇
- “이 데이터센터에서 돌아가는 AI가 다른 공장의 품질 검사를 하고 있다” — AI
하나의 AI 기사가 에너지, 로봇, 제조업까지 연쇄적으로 연결됩니다.
After: AI 기사를 읽을 때 모델 성능만 보지 않고, “이 서비스가 돌아가려면 어떤 전력과 인프라가 필요한가”, “그 인프라는 지금 얼마나 준비돼 있는가”를 같이 보게 됐습니다. 뉴스 하나를 읽는 시간은 5분에서 15분으로 늘었지만, 이해의 깊이는 완전히 달라졌습니다.
같은 뉴스를 다르게 읽는 구체적 방법
이 경험을 일반화하면 이렇습니다. 미래산업 뉴스를 읽을 때 3가지 질문을 추가로 던지세요.
| 뉴스 유형 | 보통 보는 것 | 추가로 봐야 할 것 |
|---|---|---|
| AI 모델 출시 | 벤치마크 점수 | 추론 비용은? 어떤 데이터센터에서 돌아가나? 전력은 확보됐나? |
| 로봇 데모 | 영상의 화려함 | 연속 가동 시간은? 유지보수 비용은? 기존 장비 대비 사이클 타임은? |
| 공장 투자 발표 | 투자 금액 | 전력 연결은 언제? 변압기는 발주했나? 인터커넥션 큐에 몇 년? |
| 배터리 가격 뉴스 | 셀 가격 | EV용인가 그리드 저장용인가? 어디에 설치되나? 전력망에서 어떤 역할? |
이 표를 머릿속에 넣어 두면, 같은 뉴스를 읽어도 “와, 대단하다”에서 끝나지 않고 “이 발표가 실제로 언제 산업이 되는가?”를 판단할 수 있게 됩니다. 이것이 이 시리즈 6편에서 반복적으로 연습하는 읽기 방법입니다.
한국 독자에게 왜 중요한가
한국은 이 3축 구조의 모든 요소를 갖춘 나라입니다.
- AI 인프라: 삼성전자와 SK하이닉스가 만드는 HBM(고대역폭 메모리)은 AI 가속기의 핵심 부품입니다. AI 산업의 “2층 인프라”를 한국 기업이 공급합니다.
- 로봇: 로봇 밀도 세계 1위(노동자 1만 명당 1,012대). 이미 가장 깊이 자동화된 나라입니다.
- 배터리: LG에너지솔루션, 삼성SDI, SK온이 글로벌 배터리 시장을 이끕니다.
- 데이터센터: 수도권과 충청권을 중심으로 대형 데이터센터가 빠르게 늘고 있습니다.
이 네 가지가 같은 전력 인프라와 같은 산업 정책 안에서 움직입니다. 한국 독자가 반도체 기사, 배터리 기사, 로봇 기사, 데이터센터 기사를 따로 읽으면 각각의 뉴스가 됩니다. 하지만 이 3층 프레임으로 같이 읽으면 하나의 산업 구조가 됩니다.
구체적으로 어떻게 연결되는가
삼성전자 평택 캠퍼스를 예로 봅니다. 여기서 만드는 HBM(고대역폭 메모리)은 NVIDIA GPU의 핵심 부품입니다. 이 GPU가 데이터센터에 들어가서 AI 모델을 돌립니다. 그 데이터센터가 쓰는 전기를 한국전력이 공급합니다. 한국전력의 전력망에는 SK 배터리 공장과 현대 EV 공장도 연결돼 있습니다.
즉: 삼성 반도체(AI 인프라) → NVIDIA GPU(AI) → 데이터센터(전력 소비) → 한국전력(전력 공급) → 같은 전력망에 SK 배터리 + 현대 EV(전력 경쟁). 한국에서는 이 구조가 물리적으로 같은 전력망 안에서 돌아가고 있습니다.
특히 한국은 전력 믹스(원전·LNG·재생에너지 비율) 논쟁이 치열한 나라입니다. 이 논쟁을 “환경 이슈”로만 보면 AI 산업과의 연결이 안 보입니다. 하지만 이렇게 읽어 보세요:
- “원전을 더 지어야 하나?” → 데이터센터와 반도체 팹에 안정적으로 대용량 전기를 공급할 수 있는 발전원이 뭔가?
- “재생에너지 비중을 높여야 하나?” → 태양광·풍력의 변동성을 배터리 저장으로 완충할 수 있는가? 그 배터리를 만드는 공장의 전력은 어디서 오는가?
- “전기요금을 올려야 하나?” → 산업용 전기요금이 올라가면 반도체 팹과 배터리 공장의 경쟁력에 어떤 영향을 주는가?
이렇게 읽으면 에너지 정책이 곧 산업 정책이라는 구조가 보입니다. 한국의 AI 경쟁력, 배터리 경쟁력, 반도체 경쟁력이 결국 전력 인프라라는 같은 바닥 위에 서 있다는 뜻입니다.
한국이 세계 1위 로봇 밀도(1,012대/만 명), 세계 1~2위 메모리 반도체, 세계 3강 배터리를 동시에 가지고 있다는 건, 이 3축 구조를 가장 밀도 높게 경험하는 나라라는 뜻이기도 합니다. 한국 독자에게 미래산업은 “먼 나라 이야기”가 아니라 “삼성, SK, 현대, LG, 네이버가 같은 전력망 안에서 벌이는 경쟁”입니다.
이 카테고리에서 공부하는 순서
미래산업 카테고리는 아래 6편을 순서대로 읽으면 첫 학습 루프가 닫힙니다.
“학습 루프가 닫힌다”는 것은, 6편을 다 읽으면 1편의 3층 구조가 왜 그런 구조인지 구체적 숫자와 메커니즘으로 이해하게 된다는 뜻입니다. 1편에서 “에너지가 속도 제한 층”이라고 말했는데, 4편을 읽으면 “왜 변압기 4년이 데이터센터를 멈추는지”를 숫자로 알게 됩니다. 1편에서 “로봇이 물리 실행 층”이라고 말했는데, 3편을 읽으면 “왜 466만 대 설치 기반이 휴머노이드의 판단 기준인지”를 이해하게 됩니다.
각 편이 어떤 역할을 하는지도 함께 적었습니다.
| 순서 | 제목 | 역할 | 읽고 나면 알게 되는 것 |
|---|---|---|---|
| 1 | 미래산업 입문 지도 (이 글) | 전체 지도 | 왜 3축을 같이 봐야 하는지 |
| 2 | AI 산업 스택으로 읽기 | AI축 입문 | 모델 너머 6개 층의 구조 |
| 3 | 휴머노이드: hype vs 다음 층 | 로봇축, hype 필터 | 데모와 상용화의 간극 |
| 4 | AI 붐은 왜 전력 문제로 | 에너지축 입문 | 변압기·큐·투자≠가동의 구조 |
| 5 | 배터리: 그리드 인프라 | 에너지 심화 | EV 부품을 넘어 시스템 자산 |
| 6 | 제조업×전력×로봇 | 3축 합류, 학습 루프 닫기 | 공장이 세 축의 교차점 |
1편(이 글)이 지도를 펴고, 2~5편이 각 축을 하나씩 열고, 6편이 세 축이 공장·전력망·자동화 셀에서 만나는 장면을 보여주면서 첫 학습 루프를 닫는 구조입니다.
이 글을 읽고 나면 무엇이 달라지는가
이 글을 읽기 전과 후를 정리합니다.
| 주제 | 읽기 전 | 읽은 후 |
|---|---|---|
| 미래산업이란 | AI 뉴스를 많이 보면 됨 | AI·로봇·에너지 3축이 같은 전력망과 공장에서 만나는 구조 |
| 속도를 결정하는 것 | 모델 성능, 투자 금액 | 변압기 리드타임(4년), 인터커넥션 큐(2,500GW), 공장 전력 연결 시간 |
| 로봇 산업 | 휴머노이드가 곧 온다 | 466만 대의 설치 기반 위에 쌓이는 다음 층 |
| 에너지 | 발전소를 더 지으면 됨 | 발전보다 연결(변압기, 큐)이 병목. 발전은 빠르고 연결은 느림 |
| 뉴스 읽는 법 | “대단하다” / “별로다” | “전력은 확보됐나?” “실제 가동은 언제?” “어떤 축의 이야기인가?” |
이 변화가 한 번에 일어나지는 않습니다. 2~6편을 순서대로 읽으면서 각 축의 깊이를 하나씩 쌓아가면, 6편을 마칠 때쯤 이 표의 “읽은 후” 관점이 자연스러워집니다.
반론과 한계
“AI, 로봇, 에너지 세 축이 항상 같은 비중으로 중요한가?”라는 반론은 타당합니다. 실제로 분야에 따라 비중이 달라집니다.
- 소프트웨어 서비스 기업(SaaS)에게는 에너지보다 규제와 데이터 보안이 더 긴급합니다
- 물류 자동화 기업에게는 에너지보다 로봇의 유지보수 비용이 더 직접적입니다
- 재생에너지 개발사에게는 로봇보다 인허가와 전력망 연결이 더 급합니다
이 글은 모든 기업에게 3축이 똑같이 중요하다고 말하는 게 아닙니다. 이 글은 산업 전체를 읽을 때 3축을 같이 봐야 구조가 보인다고 말하는 겁니다. 개별 기업의 우선순위는 다를 수 있지만, 산업 수준에서는 AI·로봇·에너지가 같은 전력망과 같은 공장에서 만나는 구조적 사실은 바뀌지 않습니다.
이 글은 미래산업의 전체 지도를 넓게 보여주는 역할입니다. 이후 글에서는 각 축의 중심을 더 선명하게 좁힙니다. 다만 “세 축이 서로 제약하고 서로 밀어 올린다”는 구조를 한 번 알고 나면, 각 축을 따로 볼 때도 전체 그림이 보입니다.
“AI가 좋아지면 에너지 문제도 AI가 풀지 않나?”
이 반론도 자주 나옵니다. AI가 전력망을 최적화하고, 에너지 효율을 높이고, 발전소 운영을 개선하면 전력 문제가 해결되지 않겠느냐는 겁니다.
부분적으로 맞습니다. AI는 실제로 전력 수요 예측, 그리드 최적화, 발전소 예측 정비에서 큰 효과를 보이고 있습니다. 하지만 앞서 설명한 제본스 역설을 떠올려 보세요. AI가 에너지 효율을 10% 올리면, 그 10%만큼 비용이 줄고, 비용이 줄면 사용량이 늘어서, 총 전력 수요는 줄지 않을 수 있습니다.
더 근본적으로, AI가 변압기의 물리적 제조 속도를 바꿀 수는 없습니다. 구리와 특수강의 공급량을 AI가 늘릴 수 없습니다. 토지 허가 절차를 AI가 단축할 수 없습니다. 소프트웨어 최적화가 하드웨어 공급망의 물리적 제약을 완전히 대체하지는 못합니다. AI는 에너지 문제의 일부를 풀지만, 에너지 문제를 없애지는 않습니다.
이 3축 프레임이 영원히 유효한가
아닙니다. 양자컴퓨터, 바이오테크, 우주산업이 산업 인프라 수준에서 영향력을 갖게 되면, 축 자체를 다시 봐야 합니다. 10년 후에는 “AI·로봇·에너지”가 아니라 “AI·바이오·양자”가 미래산업의 3축일 수도 있습니다.
하지만 현재 시점(2026년)에서는 투자 규모, 설치 기반, 전력 부하 세 지표에서 AI·로봇·에너지가 가장 크게 겹치는 영역입니다. 이 프레임은 “영원한 진리”가 아니라 “지금 미래산업을 읽는 가장 유효한 지도”입니다. 지도는 지형이 바뀌면 다시 그려야 합니다.
시리즈 안내: 이 글 다음에 무엇을 읽어야 하는가
이 글(1편)은 미래산업의 전체 지도를 펼쳤습니다. 여기서 궁금한 점이 생겼을 겁니다. 각 궁금증에 맞는 다음 글을 안내합니다.
- “AI 산업을 더 자세히 알고 싶다” → 2편에서 AI 산업을 6개 층(R&D, 인프라, 추론 비용, 배포, 운영, 거버넌스)으로 분해합니다. 모델 랭킹이 왜 전체의 1/6만 보여주는지 이해하게 됩니다.
- “휴머노이드 뉴스가 hype인지 현실인지 판단하고 싶다” → 3편에서 466만 대 설치 기반 위에 휴머노이드가 어떤 조건을 증명해야 하는지(신뢰성, 유지보수, 안전, 사이클 타임) 봅니다.
- “전력 문제의 구체적 메커니즘을 알고 싶다” → 4편에서 460TWh→1,300TWh, 변압기 4년, 큐 2,500GW의 구조를 숫자와 정책(FERC Order 2023)으로 풀어 봅니다.
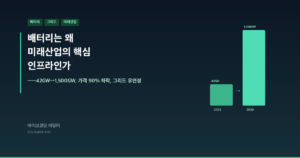
- “배터리가 EV 밖에서 왜 중요한지 알고 싶다” → 5편에서 42GW→1,500GW 성장, 배터리의 4가지 그리드 기능, 제품이면서 인프라인 순환 구조를 봅니다.
- “결국 이 모든 축이 어디서 만나는지 보고 싶다” → 6편에서 공장이라는 물리 공간에서 세 축이 교차하는 5가지 메커니즘을 종합합니다.
2편부터 순서대로 읽는 것을 추천하지만, 관심 축이 뚜렷하면 해당 편부터 읽어도 됩니다. 다만 1편(이 글)은 반드시 먼저 읽으세요. 나머지 글의 맥락이 됩니다.
자주 묻는 질문
Q: 미래산업 공부를 처음 시작하는데 무엇부터 읽으면 되나요?
A: 이 글(1편)을 먼저 읽으세요. 여기서 AI·로봇·에너지의 3층 구조와 왜 같이 봐야 하는지를 이해합니다. 그 다음 2편(AI 스택)→3편(휴머노이드)→4편(전력)→5편(배터리)→6편(제조업 교차점) 순서로 읽으면, 미래산업을 구조적으로 이해하는 첫 학습 루프가 완성됩니다. 6편을 다 읽으면 같은 뉴스를 읽어도 산업 구조가 보이기 시작합니다.
Q: AI만 관심 있는데 로봇과 에너지까지 봐야 하나요?
A: AI를 깊이 따라가면 반드시 만나는 것들이 있습니다. “이 AI 서비스를 돌리려면 데이터센터가 얼마나 필요한가?” → 전력 문제. “추론 비용이 내려가면 사용량이 얼마나 폭발하나?” → 인프라 문제. “AI가 만든 판단을 물리 세계에서 누가 실행하나?” → 로봇 문제. AI만 보면 이 질문들에 답할 수 없습니다. 로봇과 에너지는 AI의 “나머지 몸”이기 때문에, 같이 봐야 전체가 보입니다.
Q: 이 카테고리는 투자 정보를 다루나요?
A: 투자 추천은 하지 않습니다. 이 시리즈는 “어떤 종목을 사야 하나”가 아니라 “이 산업이 실제로 어떻게 작동하는가”를 설명합니다. 예를 들어 “변압기 리드타임이 4년”이라는 사실을 알면, 데이터센터 투자 발표가 실제 가동과 3~5년 차이가 난다는 걸 이해하게 됩니다. 이런 구조 이해가 투자 판단이든, 커리어 판단이든, 공부 방향이든 어떤 결정에든 기반이 됩니다.
Q: Elon Musk가 미래산업을 매일 공부하라고 했다는 말이 사실인가요?
A: 정확한 직접 인용으로 확인되지 않았습니다. 이 문구는 한국 인터넷에서 밈처럼 퍼진 것으로, 2019년 WAIC에서 잭 마가 한 “주 3일, 하루 4시간 근무” 발언과 머스크의 발언이 혼합된 것으로 추정됩니다. 직접 인용처럼 쓰면 안 됩니다. 하지만 중요한 점은 따로 있습니다. 테슬라는 실제로 AI(자율주행, Dojo), 로봇(Optimus), 에너지(Megapack 배터리 저장, 태양광)를 하나의 회사 안에서 운영하고 있습니다. 문구의 출처가 불확실해도, 실제 산업 구조에서 AI·로봇·에너지가 묶인다는 관찰은 유효합니다.
Q: 이 블로그는 AI 블로그인데 왜 로봇과 에너지를 다루나요?
A: 이 블로그의 AI 카테고리(Vibe Coding, Claude Code, AI Tools 등)는 “AI를 실제로 쓰는 법”을 다룹니다. 미래산업 카테고리는 “그 AI가 돌아가는 물리 인프라”를 다룹니다. 예를 들어 Claude Code를 쓰려면 데이터센터에서 AI 모델이 돌아가야 하고, 그 데이터센터는 전기가 필요하고, 그 전기를 보내는 변압기가 4년 걸립니다. AI 카테고리에서 “도구를 잘 쓰는 법”을 배우고, 미래산업 카테고리에서 “그 도구가 작동하는 산업 구조”를 배우는 겁니다. 둘은 같은 구조의 다른 층입니다.
회원 등록(무료)으로 매주 월요일 뉴스레터 받기 → 등록하기
저자: VibeCoding Tailor (shuntailor.net 운영. AI 도구 실무 활용과 미래산업 구조 해설을 일본어·한국어로 발신 중. Lovable 공식 앰버서더.)
이 글에서 사용한 데이터의 출처와 신뢰도
이 시리즈에서 사용하는 숫자는 모두 1차 데이터에서 가져왔습니다. “1차 데이터”란, 해당 분야의 공인 기관이 직접 수집·분석한 데이터를 뜻합니다. 뉴스 기사나 개인 블로그의 추정치가 아닙니다.
- Stanford HAI AI Index Report: AI 산업의 투자, 도입, 비용, 모델 동향을 추적하는 연례 보고서. 스탠퍼드 대학교 인간 중심 AI 연구소 발행.
- IFR World Robotics: 전 세계 산업용 로봇의 설치 대수, 밀도, 지역 분포를 집계하는 연례 보고서. 국제로봇연맹(IFR) 발행.
- IEA Electricity / Energy and AI: 전 세계 전력 수요, 데이터센터 전력, 에너지 전환 동향을 분석하는 보고서. 국제에너지기구(IEA) 발행.
각 보고서의 구체적 링크는 아래에 있습니다. 이 시리즈의 숫자가 맞는지 직접 확인하고 싶으면, 아래 원본을 읽어 보세요.
소스 목록
- Stanford HAI — AI Index Report 2025
- IFR — World Robotics 2025
- IEA — Electricity 2025
- IEA — Energy and AI (2025)