LLM 디코딩 — ChatGPT가 한 글자가 아니라 한 문장을 매끄럽게 뽑는 정체
LLM 이론 집중코스 · 4편 (디코딩 — 토큰을 어떻게 뽑을지의 깊이)
3편 (ChatGPT 작동 원리) 와 3.5편 (AI 추론 모델) 을 안 읽으셨다면 먼저 보고 오시면 좋아요. 이 글은 그 위에 쌓는 글이에요.
LLM 디코딩은 ChatGPT가 한 토큰이 아니라 한 문장 전체를 매끄럽게 뽑기 위해 거치는 모든 메커니즘이에요. Beam search · Sampling · Temperature · Top-P · Min-P · Repetition Penalty · Stop Sequences · Constrained Decoding — 8개 도구가 누적되어 작동해요. 3편에서 한 토큰 뽑는 자리까지 봤다면, 이번 4편은 그 토큰들이 모여 한 문장이 되는 자리를 정공법으로 풀어요.
2️⃣ Beam search가 막강해 보이는데 왜 ChatGPT·Claude는 안 쓰는지 (반복 붕괴·모드 붕괴)
3️⃣ Min-P·Repetition Penalty·Stop Sequences·Constrained Decoding — 자리별 권장값까지 한 세트
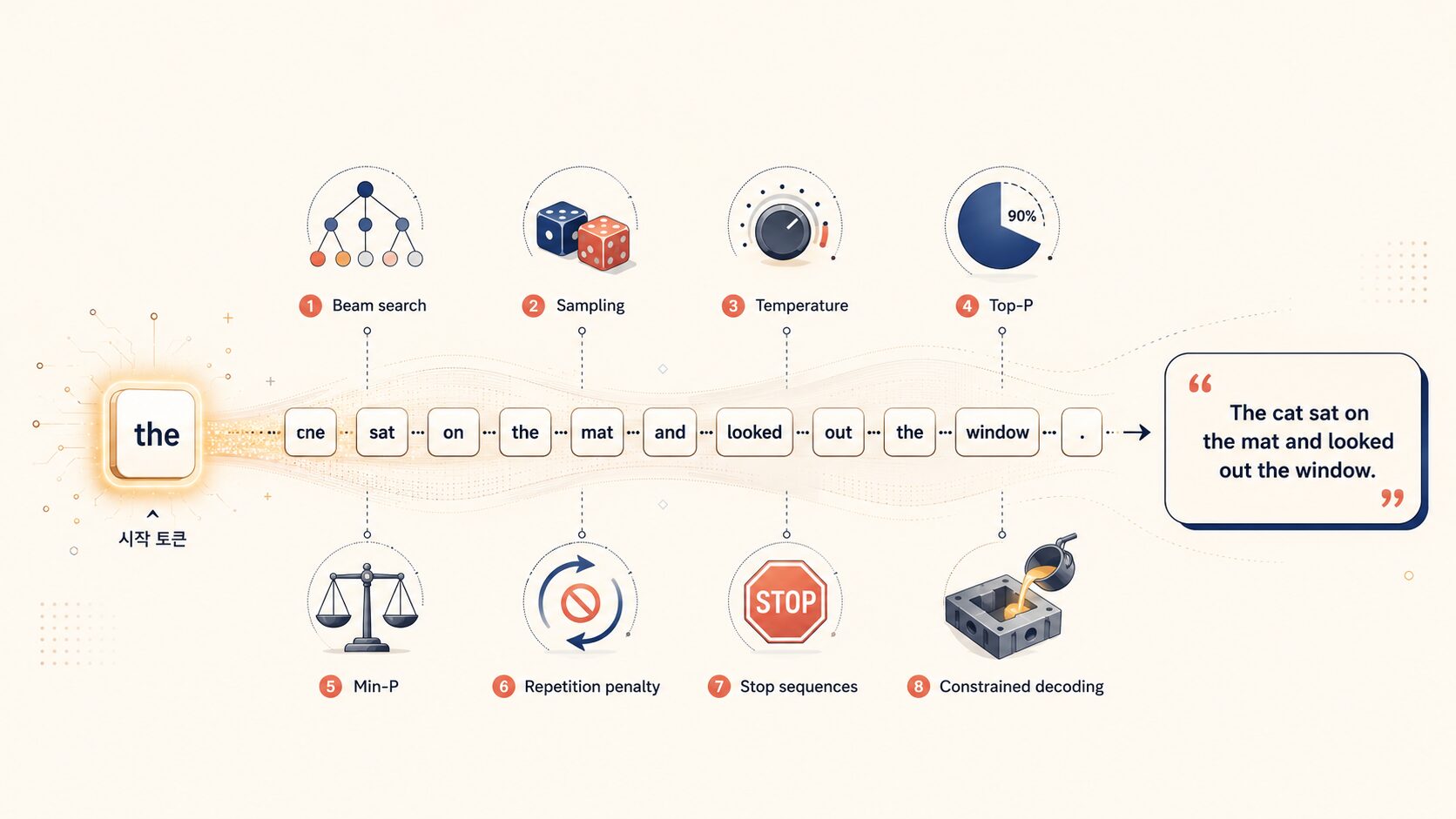
LLM 이론 집중코스 4편이에요.
3편에서 ChatGPT가 한 글자(토큰)씩 답을 뱉는 정체까지 봤어요. Softmax로 확률 분포 만들고, Sampling으로 한 토큰 뽑고, Temperature로 흔드는 정도 조절하고, Top-K·Top-P로 헛소리 토큰 잘라내고.
근데 잠깐 — 이 모든 게 “이번 한 토큰을 잘 뽑자” 였어요.
질문 하나가 자연스럽게 떠올라요.
한 토큰을 매번 best로 뽑으면, 그게 모여서 만들어진 문장 전체도 best일까?
이게 4편의 출발선이에요. 답부터 말하면 — 아니에요. 그리고 이 사실 위에서 LLM 디코딩 도구 8가지가 다 자라났어요.
2. Beam search라는 게 있다는데, 정작 ChatGPT·Claude는 왜 안 쓰나
3. 3편에서 본 Temperature·Top-P가 *왜* 존재하는지 4편에서 진짜로 풀려요
4. Top-P랑 Min-P 차이는? Min-P는 언제 등장했나
5. AI가 *그래서 그래서 그래서*를 반복하는 이유와 해결책
6. 긴 글에선 페널티가 자연스러운 접속사까지 죽이지 않나 — 조선시대 접속사 문제
7. AI는 답을 언제 멈춰야 할지 어떻게 아나
8. *JSON으로만 답해* 라는 지시는 어디서 나왔나, 왜 강제까지 필요한가
다 풀어보죠.
1. 한 토큰 best가 시퀀스 best가 아니에요
가장 작은 사례부터 가요.
LLM이 두 글자만 생성한다고 단순화해볼게요. 첫 토큰 후보가 둘이라고 쳐요.
"고" → 확률 0.6
"강" → 확률 0.4
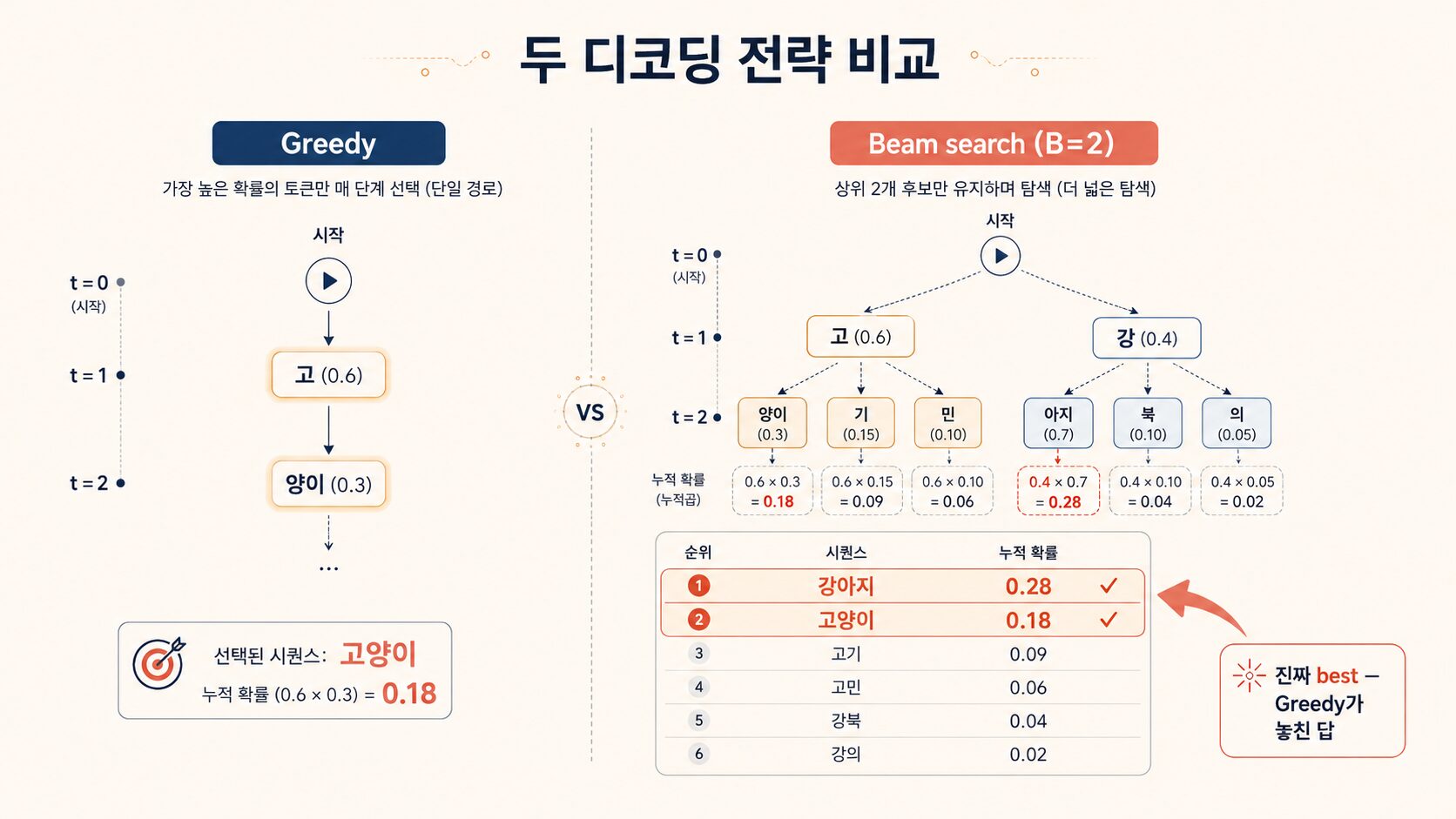
Greedy 라는 디코딩 방식이 있어요. 매번 가장 높은 확률 토큰을 그대로 뽑는 거예요. 당연히 “고” 선택이죠.
근데 t=2에서 각 길의 가장 좋은 다음 토큰이 이렇게 생겼다고 쳐봐요.
"고" 뒤 best 토큰 → "양이" (0.3)
"강" 뒤 best 토큰 → "아지" (0.7)
시퀀스 전체 확률을 계산해봐요.
"고양이" = 0.6 × 0.3 = 0.18
"강아지" = 0.4 × 0.7 = 0.28 ← 이게 best
Greedy는 t=1에서 0.6 > 0.4 만 보고 “고”로 갔어요. 근데 시퀀스 전체로 보면 “강아지”가 best였어요.
즉 이런 거예요.
매 토큰의 best ≠ 시퀀스 전체의 best
비유로 말하면 Greedy는 매 갈림길에서 가장 가파른 길로 가는 산행이에요. 그 가파른 길이 절벽으로 이어질 수도 있고, 살짝 덜 가파른 옆길이 정상까지 더 빨리 데려갈 수도 있어요.
2. 끝까지 다 보면 진짜 best를 잡을 수 있을까요
그럼 극단으로 가서, 모든 가능한 시퀀스를 다 따져보고 가장 확률 높은 거 고르면 진짜 best잖아요? 이론적으론 맞아요. 근데 비용을 가늠해봐요.
3편에서 본 BPE 어휘집 크기 기억나요? 약 12.8만 개.
시퀀스 길이가 짧게 잡아 100토큰 (답변 한 단락 정도).
가능한 시퀀스 수는요.
128,000 × 128,000 × ... (100번)
= 128,000 ^ 100
≈ 10 ^ 510
이게 얼마나 큰 숫자냐면 — 우주에 있는 원자 수가 약 10^80개예요.
즉 10^510은 우주 원자 수의 10^430배.
“끝까지 다 본다”는 물리적으로 불가능해요.
3. Beam search — 폭(B)으로 타협하는 법
여기서 두 개의 노브가 동시에 보이기 시작해요.
- 얼마나 멀리 볼 거예요 (깊이)
- 매 t마다 후보를 몇 개나 들고 갈 거예요 (폭)
극단들을 표로 정리하면 이래요.
| 방식 | 폭 | 깊이 | 비용 | 정확도 |
|---|---|---|---|---|
| Greedy | 1 | 1 | 거의 0 | 낮음 |
| 완전 탐색 | 12.8만 | ∞ | 우주 박살 | 진짜 best |
이 사이 어딘가에 현실적인 타협점이 있을 거 같죠? 핵심 발상은 이거예요.
매 t마다 후보를 모조리 보지 말고, 상위 B개만 살려두자.
이게 Beam search. 그리고 그 B를 beam width 라고 불러요.
작은 사례 — B=2일 때 어떻게 흐르는지
B=2로 우리 두 글자 예시를 다시 굴려봐요.
t=1 — 상위 2개 살림
"고" 0.6 ← 살림
"강" 0.4 ← 살림
살아있는 시퀀스: ["고", "강"]
t=2 — 각각에서 가지치고, 누적 확률로 한 줄에 놓고 정렬
“고” 뒤 후보 (단순화 3개):
"고민" 0.6 × 0.1 = 0.06
"고양이" 0.6 × 0.3 = 0.18
"고기" 0.6 × 0.15 = 0.09
“강” 뒤 후보:
"강아지" 0.4 × 0.7 = 0.28
"강북" 0.4 × 0.1 = 0.04
"강의" 0.4 × 0.05 = 0.02
6개를 다 한 줄에 놓고 누적 확률로 정렬, 상위 2개만 살림.
1. 강아지 0.28 ← 살림
2. 고양이 0.18 ← 살림
3. 고기 0.09 ✗
4. 고민 0.06 ✗
5. 강북 0.04 ✗
6. 강의 0.02 ✗
살아있는 시퀀스: ["강아지", "고양이"]
t=3에서도 똑같이
각 후보에서 다음 토큰 가지치고 → 누적 확률로 정렬 → 상위 2개만 살림. 시퀀스 끝날 때까지 (EOS 토큰 만나거나 max length) 반복.
마지막에 살아있는 B개 중 누적 확률 최고가 최종 답이에요.
헷갈리기 쉬운 자리 — Beam width는 “첫 토큰 개수”가 아니에요
처음 Beam search를 본 사람이 가장 흔히 빠지는 자리예요.
“폭(B)이라는 게 첫 토큰을 몇 개로 정할지인가요?” — 절반은 맞고 절반은 어긋나요.
t=2에서 일어나는 일을 다시 봐요. “고” 뒤 후보 3개랑 “강” 뒤 후보 3개가 한 줄에 놓이고 같이 경쟁해요.
함의가 미묘한데, 예를 들어 t=3에 갔을 때 “고”로 시작한 시퀀스가 둘 다 죽고 “강” 출신만 두 개 살아남을 수도 있어요. 반대로 t=1에서 0.6짜리 “고”가 강해 보였어도, “고” 뒤가 다 별로면 t=2 prune에서 “고” 출신이 다 사라질 수도 있어요.
즉 B는 “각 step에서 살릴 시퀀스 수”예요. “첫 토큰의 개수”가 아니라요.
B의 양 극단
- B=1 → 매 step에서 상위 1개만 살림 → 결국 매번 가장 높은 확률 토큰 = Greedy
- B=∞ → 다 살림 → 완전 탐색 (우주 박살)
- B=2~10 정도가 실용 영역
4. Beam search가 막강해 보이는데 — 요즘 ChatGPT·Claude는 안 써요
여기서 의외의 자리예요. 답을 한 줄로:
“best 확률 시퀀스” ≠ “좋은 텍스트”
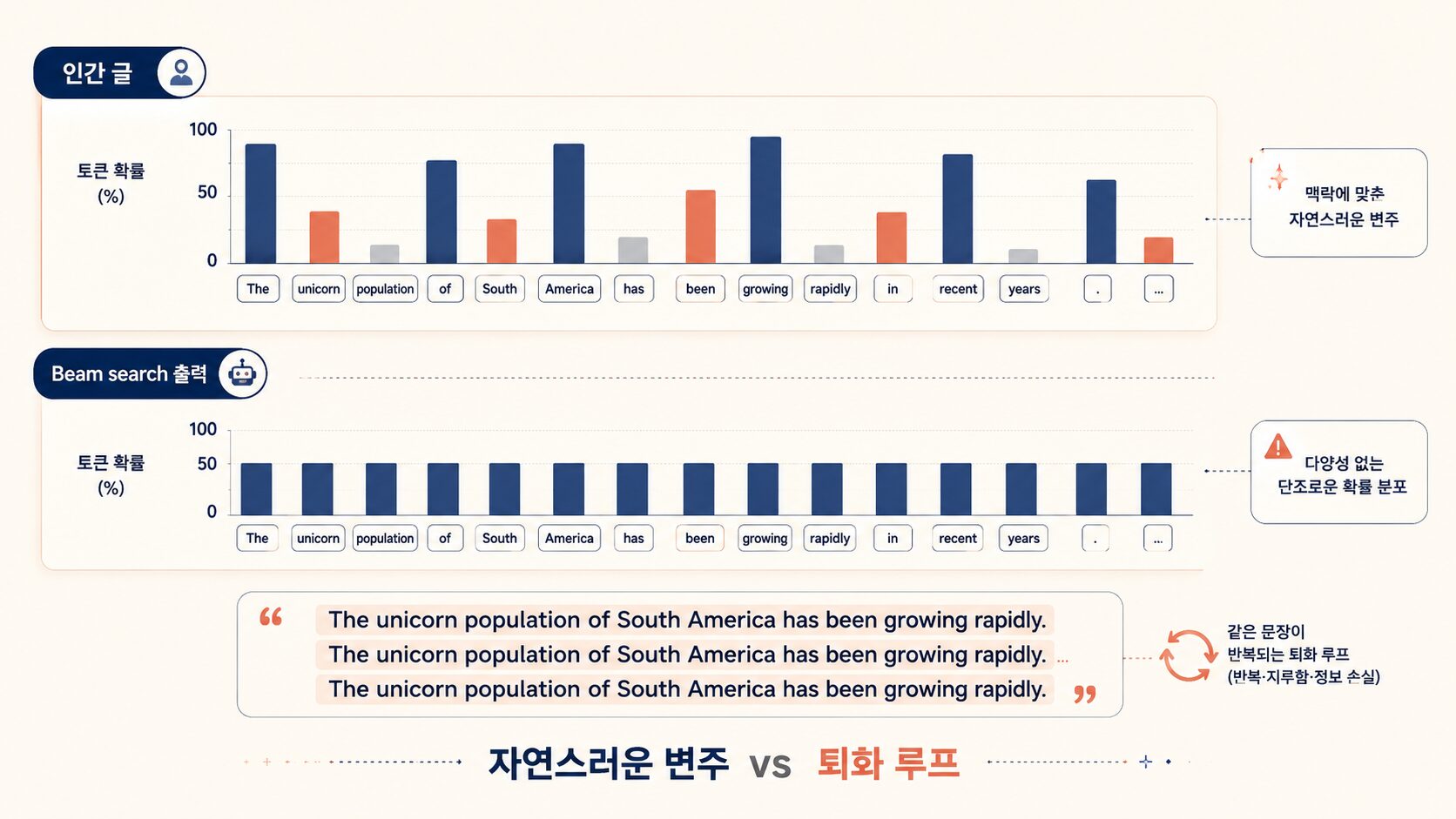
3편 끝까지, 그리고 4편 여기까지 — 우리는 “어떻게든 시퀀스 전체 확률을 높이자”고 노력했어요. 근데 막상 그 best 확률 시퀀스를 뽑아보면 재미없고 반복적이고 부자연스러워요.
반복 붕괴 (degeneration)
GPT-2 시절 잘 알려진 사례 (Holtzman 외, “The Curious Case of Neural Text Degeneration”, 2019):
Beam search 출력은 이래요.
"The unicorn population of South America has been growing rapidly.
The unicorn population of South America has been growing rapidly.
The unicorn population of South America has been growing rapidly.
The unicorn population..."
왜 이렇게 됐냐면 — LLM이 한 번 “The unicorn population…growing rapidly” 라고 뱉으면, 그 다음 토큰의 가장 높은 확률 후보가 같은 구절 인 경우가 많아요.
학습 데이터에서 LLM이 본 패턴 — 책에서 강조 반복, 시 후렴, 강조용 재진술 등 — 때문에 한 번 X를 뱉은 뒤엔 X를 또 뱉는 확률이 살짝 올라가요. (설명용 단순화예요. 진짜 메커니즘은 더 미묘한데, 직관으론 이 정도면 돼요.)
Beam search는 그 “살짝 높은” 확률을 충실히 따라가요. 그 결과 → 반복 루프.
인간 텍스트는 high-probability가 아니에요
Holtzman 그래프 직관:
인간 글: 확률 ▁▆█▄▇▁▆▅█▂▆▇▃▅▇▁ (들쭉날쭉)
Beam 출력: 확률 ████████████████ (계속 높음)
인간이 글 쓸 때 — “갑자기”, “근데”, “사실은” 같은 확률이 살짝 낮은 토큰들이 글을 자연스럽게 만들어요. Beam search는 정확히 그 토큰들을 잘라요. “더 높은 확률 있는데 왜 그걸 살려” 라고요.
모드 붕괴
B개 시퀀스가 살아남는다고 했죠? 막상 보면 B개가 다 비슷비슷해요.
1. "The unicorn population of South America has been growing rapidly..."
2. "The unicorn population of South America has been increasing rapidly..."
3. "The unicorn population of South America is growing rapidly..."
4. "The unicorn populations of South America have been growing rapidly..."
다양성 0. 같은 길의 미세 변주만이에요.
5. 3편이 여기서 풀려요 — Temperature·Top-P가 왜 있는지
여기서 3편 자리가 다시 등장해요.
3편에서 본 도구들이에요.
- Sampling (확률대로 뽑기)
- Temperature (분포 평평하게)
- Top-K, Top-P (헛소리만 잘라내고 나머지는 살림)
이게 다 뭘 위한 거였어요?
일부러 best 확률을 안 뽑기 위해서요.
3편 봤을 땐 “왜 굳이 일부러 안 뽑지?” 가 살짝 안 잡혔을 수 있어요. 4편 여기서 풀려요 — best 확률을 그대로 뽑으면 부자연스럽고 반복적이거든요. 그래서 확률 분포를 따르되, 적당히 흔들면서 뽑는 방식이 더 인간 같은 출력을 만들어요.
그래서 요즘 디코딩 지형
각 task가 어떤 디코딩을 쓰는지 실제 사례로 풀어볼게요.
채팅·창작·일반 대화 — Sampling
ChatGPT에 똑같이 “여행지 추천해줘” 두 번 던지면 이런 식이에요.
[1회차]
"가을이라면 일본 교토 어때요? 단풍이 절정이고,
청수사·금각사 같은 전통 사찰을 걷다 보면..."
[2회차]
"포르투갈 리스본 가보세요. 따뜻한 햇살 아래 트램 28번을 타고
구시가지를 누비면 색다른 유럽이 펼쳐져요..."
같은 질문, 다른 답. 매번 확률 분포에서 다른 토큰을 뽑기 때문이에요 — 이게 Sampling.
Temperature 노브로 흔드는 정도 조절해요.
- T=0.7 (기본) — 자연스럽고 다양함
- T=0 — 매번 똑같은 답
- T=1.5 — 너무 흔들려서 가끔 헛소리
기계번역, 요약 — Beam search
영한 번역기에 “I love you” 입력. Beam search 출력 → 항상 “사랑해요.” 만 나와요.
만약 Sampling을 쓰면 매번 답이 달라요 — “당신을 사랑해”, “널 좋아해”, 가끔 “I love you라는 건…”이라고 사고도 쳐요. 번역은 정답이 좁아서 Sampling이 안 맞아요.
Google 번역, DeepL, Papago — Beam search가 여전히 현역이에요.
Code 생성 — Sampling (낮은 Temperature)
코드는 정답이 좁아요. 잘못된 토큰 하나면 syntax error가 나죠. 그래서 Temperature 0.2~0.4 정도로 낮게 잡아 거의 같은 코드를 출력하되, 미세 변주만 허용해요.
GitHub Copilot, Cursor, Claude Code — 다 낮은 Temperature 사용.
추론 모델 — Sampling + 다중 경로 탐색
o1, GPT-5.4 Pro 같은 추론 모델이 어려운 문제를 풀 때 내부 사고 과정은 이래요.
[경로 1] 이항 정리로 풀어볼까? ... 막힘
[경로 2] 그럼 수학적 귀납법? ... 진행 중
[경로 3] 잠깐, 다른 각도 — 모듈러 산술로 보면? ... 풀림 ✓
여러 풀이 경로를 의도적으로 다양하게 만들어요. 다양성이 핵심이라 Beam search는 안 맞아요 — 비슷한 풀이 4개 살려도 다 같은 막힘에 빠지거든요. Sampling은 일부러 다른 경로로 분기시켜요.
DeepSeek-R1, GPT-5.4 Pro, Claude Extended Thinking — 다 이 방식.
한 줄로 묶으면, 각 자리는 결국 “정답이 좁냐 넓냐” 로 갈려요.
정답 좁음 ─→ Beam search (번역, 요약)
정답 중간 ─→ 낮은 Temp Sampling (Code)
정답 넓음 ─→ 보통 Temp Sampling (채팅, 창작)
다양성 필요 ─→ Sampling + 분기 (추론)
6. Top-P도 무너지는 자리 — Min-P가 등장한 이유
지금까지의 3편 도구들 (Top-P, Top-K)이 만능 같았어요. 근데 Top-P가 무너지는 자리가 있어요.
Top-P 복기
Top-P (=nucleus sampling) = “누적 확률 P에 도달할 때까지의 토큰들만 살리자”.
Top-P=0.9 면 → 확률 높은 순으로 정렬, 누적 0.9 채울 때까지의 토큰만 candidate. 그 안에서 Sampling.
Top-K (상위 K개 고정)보다 똑똑한 이유는 분포 모양에 따라 살리는 토큰 수가 동적이라는 거예요.
Top-P가 무너지는 자리
Case A — 분포가 sharp할 때 (모델 확신 강함):
"파리" 0.95
"런던" 0.02
"베를린" 0.01
... long tail
Top-P=0.9 → “파리” 만 살림. 잘 작동.
Case B — 분포가 평평할 때 (모델 확신 약함):
"고양이" 0.10
"강아지" 0.08
"햄스터" 0.07
"앵무새" 0.06
... (수십 개가 0.02~0.05)
"수도꼭지" 0.015 ← 헛소리
"포항제철" 0.010 ← 헛소리
Top-P=0.9 → 누적 0.9 채우려면 수십 개 살려야 해요. 그 안에 “수도꼭지” 같은 헛소리 토큰도 같이 살아남아요.
가끔 문맥 안 맞는 토큰이 출력에 섞이게 돼요.
근데 Top-P=0.5로 낮추면? 정상 토큰까지 잘려나가서 다양성 죽음. 균형이 안 잡혀요.
핵심 문제는 — Top-P는 “누적”으로 자르니까, 분포가 평평할 때 약한 토큰까지 다 들어와요.
Min-P의 발상
1등 토큰 확률의 X% 미만은 다 버리자.
Min-P=0.1 이면 → “1등 토큰 확률의 10% 미만은 컷”.
Case B에 Min-P=0.1 적용:
"고양이" 0.10 ← max, threshold = 0.10 × 0.1 = 0.01
"강아지" 0.08 ✓
"햄스터" 0.07 ✓
"앵무새" 0.06 ✓
"잉어" 0.05 ✓
"닭" 0.04 ✓
"수도꼭지" 0.015 ✓ (살아남음, 애매)
"포항제철" 0.010 = threshold (경계)
... (0.01 미만은 다 cut)
(Min-P=0.2~0.3 으로 더 강하게 쓰면 threshold=0.02~0.03 → “수도꼭지”까지 cut)
핵심: 상대 기준이에요. 1등이 0.95이면 threshold=0.095라 거의 다 잘리고, 1등이 0.10이면 threshold=0.01이라 많이 살림. 분포 모양에 자동 적응.
Top-P vs Min-P 한 줄로
Top-P: "누적 90% 채우자" ← 절대 누적
Min-P: "1등의 10% 미만은 자르자" ← 상대 비율
비유로 말하면 이래요.
- Top-P = “위에서부터 손님 누적 매출이 90% 될 때까지 입장”
- Min-P = “VIP 손님 매출의 10% 미만인 손님은 입장 거부”

진짜 빛나는 자리 — 고온 Sampling
Temperature를 올리면 (예: T=1.5) 분포가 평평해져요. 이때 Top-P는 헛소리가 잔뜩 들어와서 무너져요. Min-P는 상대 기준이라 평평한 분포에서도 약한 토큰을 잘 잘라요.
원논문 제목이 정확히 이 자리를 짚어요.
“Min P Sampling: Balancing Creativity and Coherence at High Temperature” (Nguyen 외, 2023)
고온 (창의성 ↑) + 일관성 유지 (헛소리 ↓) — 둘을 동시에.
어디서 쓰이나
| 자리 | 사용 |
|---|---|
| 로컬 LLM (Llama.cpp, KoboldAI, Open WebUI) | Min-P 인기 ↑ |
| 창작·롤플레이 (Temp 높은 자리) | Min-P 적합 |
| OpenAI API, Claude API | 아직 Top-P 위주 (Min-P 미지원) |
| 번역·요약 | 어차피 Beam search 영역 |
창작 다양성 원하면서 헛소리는 피하고 싶다가 강한 커뮤니티(로컬 LLM, RP)에서 먼저 자리 잡고, 점차 mainstream으로 퍼지는 중이에요.
이번 주 AI 흐름
7. AI가 “그래서 그래서 그래서”를 반복하는 이유 — Repetition Penalty
앞에서 Beam search가 반복 붕괴한다고 봤죠. 근데 사실 Sampling에서도 미묘하게 반복은 일어나요. 더 부드러워서 잘 안 보일 뿐이에요.
실제 출력 예시:
"오늘 날씨가 정말 좋아요. 좋은 날씨가 좋은 기분을 만들고,
좋은 기분이 좋은 하루를 만들죠. 좋은 하루, 좋은 운동, 좋은 식사..."
또는 한 단어가 stuck:
"그래서 제 생각은요, 그래서 우리는, 그래서 이게 중요한데,
그래서 결론적으로 그래서..."
왜 일어나냐면 — Beam 자리에서 본 메커니즘과 동일해요. LLM이 한 번 X를 뱉으면 학습 데이터 패턴 때문에 “X 다음에 또 X” 확률이 살짝 올라가요. Sampling이 그 분포를 충실히 따르다가 가끔 반복 루프에 빠지는 거예요.
Repetition Penalty의 발상
이미 등장한 토큰은 logit에 페널티를 줘서 다음에 또 뽑힐 확률을 낮추자.
수식 직관:
원래 logit: z
이미 등장한 토큰 → z / penalty (penalty > 1, 보통 1.1~1.3)
등장 안 한 토큰 → z 그대로
(설명용 단순화예요. 실제 구현은 z가 양수냐 음수냐에 따라 처리가 갈리는데, 직관으론 “감점” 정도로 보면 돼요.)
작은 사례
“운동” 토큰의 원래 다음 확률이 0.30 (1위) 이라고 치고, penalty=1.3을 적용해봐요.
| Step | 누적 등장 | “운동” 확률 (대략) |
|---|---|---|
| 처음 등장 전 | 0 | 0.30 |
| 1번 등장 후 | 1 | ≈ 0.23 |
| 2번 등장 후 | 2 | ≈ 0.18 |
| 3번 등장 후 | 3 | ≈ 0.14 |
점점 안 뽑혀 → 반복 회피.
Frequency vs Presence — 헷갈리기 쉬운 자리
OpenAI API는 둘로 나눠요.
Frequency Penalty = 등장 횟수에 비례해서 감점.
- 2번 등장 → 작은 감점
- 10번 등장 → 큰 감점
- “정말 정말 정말…” 같은 누적 반복 차단에 강함
Presence Penalty = 등장 여부만 보고 감점 (1번이든 100번이든 같은 강도).
- 한 번이라도 등장한 토큰은 일률 감점
- 다양한 주제 유도 효과 (“이미 언급한 거 말고 새로운 거” 같은 느낌)
비유로 말하면 이래요.
- Frequency = “같은 사람이 자주 발언하면 발언권 점점 줄임”
- Presence = “이미 발언한 사람은 한 번에 발언권 한 단계 깎아둠”
권장값.
frequency_penalty: 0.0 ~ 0.5 (보통 0.3)presence_penalty: 0.0 ~ 0.5 (보통 0.2)
8. 헷갈리기 쉬운 자리 — 긴 글에서 일어나는 진짜 부작용
여기가 4편에서 가장 미묘한 자리예요. 표면 답으론 “penalty 값이 너무 높으면 자연스러움이 깨진다” 정도지만, 진짜 메커니즘은 그 아래에 있어요.
질문 하나 — 글이 길어지면 어떻게 될까요?
긴 글에서 자주 쓰는 접속사들이 누적 등장해요 (penalty=1.3):
- “그래서” 5번 → logit / 1.3⁵
- “근데” 3번 → logit / 1.3³
- “그리고” 4번 → logit / 1.3⁴
“흔한 접속사들이 다 같이 떨어지니까 괜찮은 거 아닌가” 하는 직감이 들 수 있어요. 절반은 맞아요 — 다 같이 떨어지긴 해요. 근데 절반은 어긋나요 — 균등하게 안 떨어져요.
그리고 더 본질적인 자리가 있어요.
한 번도 안 쓴 토큰은 그대로 살아있어요
Penalty는 “등장한 토큰만 감점” 이에요. 즉:
- “그래서”, “근데”, “그리고” → 점점 감점
- “하옵고”, “고로”, “이에”, “기실” → 감점 0, 그대로
흔한 접속사들이 가라앉는 동안, 어휘집 깊은 곳에 잠자던 드물게 등장하는 토큰들의 상대 확률이 부풀어 올라요.
결과는 이래요.
긴 글 후반부:
"고로 우리는 운동을 해야 하옵고, 기실 식단도 중요하옵나니,
이에 더불어 수면 또한..."
조선시대 접속사 등장. 페널티가 흔한 거 누르니까, 모델이 점점 어휘집의 변두리로 도망하는 거예요. LLM 커뮤니티에서 잘 알려진 누적 페널티의 본질적 한계예요.

그래서 어떻게 푸나
세 가지 실무적 해법이 있어요.
1. Window 방식
Penalty를 전체 누적이 아니라 최근 N토큰 (예: 마지막 512)만 보고 계산. llama.cpp의 --repeat-last-n 512 같은 옵션.
1만자 글이라도 “그래서”가 1000토큰 전에 등장했으면 그 등장은 무시. 가까이 등장한 것만 감점.
2. Decay 방식
등장 위치에 따라 감점 강도를 다르게. 최근 등장 = 큰 감점, 오래된 등장 = 약한 감점. 자연스러운 “흐림” 효과.
3. DRY sampler (Don’t Repeat Yourself, 2024)
단일 토큰 단위로 감점하지 말고 n-gram 패턴 단위로 감지.
- “그래서” 단독 5번 → 봐줌 (자연스러움)
- “그래서 결국 우리는” 이라는 4단어 구문이 두 번 반복하려고 → 큰 페널티
- “구문 반복”만 죽이고 “단어 반복”은 살림
요즘 로컬 LLM 커뮤니티 (KoboldAI, SillyTavern 등) 에서 DRY가 가장 핫한 자리예요.
글 길이별 권장
| 글 길이 | 권장 |
|---|---|
| 짧은 글 (< 1000자) | Repetition penalty 1.1~1.3 OK |
| 중간 (1000~5000자) | Windowed penalty (마지막 N토큰만) |
| 긴 글 (1만자+) | DRY sampler 또는 penalty off |
9. AI는 언제 멈춰야 할지 어떻게 아나 — Stop Sequences
3편에서 본 디코딩 — autoregressive하게 한 토큰씩 영원히 뽑을 수 있어요. 그럼 자연스러운 종료는 어디서 일어나요?
세 가지 메커니즘이 공존해요.
- 모델이 스스로 멈춤 (EOS 토큰)
- 사용자가 외부에서 잘라냄 (Stop sequences)
- 그래도 안 멈추면 → Max tokens 강제 컷
순서대로 가요.
1. EOS 토큰 — 모델이 스스로 멈추는 법
학습 데이터에서 모든 문장의 끝에 특수 토큰을 박아둬요. 모델마다 이름이 달라요.
- GPT 계열:
<|endoftext|> - LLaMA 계열:
</s>또는<|eot_id|>
학습 시 모델은 “이 자리에서 끝나는 게 자연스럽다”는 패턴을 배워요. 추론 시 답이 다 됐다고 판단하면 EOS 토큰의 확률이 올라가서 → EOS가 뽑힘 → 디코딩 루프 종료.
직관:
- 답이 자연스럽게 끝나면 EOS 확률 ↑
- 답이 더 이어져야 하면 EOS 확률 ↓
- 모델은 “이제 끝났어”를 확률 분포로 표현해요
작은 사례 — GPT-2 같은 옛 모델은 EOS를 잘 못 뽑아서 끝없이 rambling했어요.
사용자: "안녕"
GPT-2: "안녕 그래 오늘은 어떻게 지냈어 나도 잘 지냈어 사실 어제는 친구를 만났는데..."
(끝없이 이어짐)
ChatGPT부터는 RLHF로 “적절한 길이로 끝내기”까지 학습됐어요. 답이 충분하면 EOS 적극 뽑아요.
2. 사용자 지정 Stop Sequences
API에서 직접 지정 가능해요.
client.chat.completions.create(
model="gpt-4o",
messages=[...],
stop=["\n\n", "Human:", "###"]
)
지정한 문자열이 출력에 나타나면 즉시 중단.
멀티턴 모킹 — 프롬프트로 대화 형식 던질 때, 모델이 답한 다음에 또 “Human:” 쓰면서 사용자 척 계속하면 안 돼요. stop=["Human:"] 으로 컷.
코드 자동완성 — 함수 하나만 완성하고 싶을 때 stop=["\n\n", "def ", "class "]. 다음 함수 시작 전 멈춤.
구조화된 출력 — JSON 닫힘 후 추가 설명 못 붙이게 stop=["\n}"].
3. Max Tokens — 마지막 안전망
EOS 안 뽑고 stop sequence 안 나오면 → max_tokens 도달 시 강제 컷.
부작용: 문장 중간에 잘림.
"그래서 우리가 할 일은 다음과 같습니다: 1) 식단 조절, 2)"
↑ 여기서 끝
API는 보통 finish_reason 으로 알려줘요.
stop→ EOS or stop sequence로 정상 종료length→ max_tokens 도달 (잘렸음)content_filter→ 안전 필터에 걸림
finish_reason 안 확인하면 사용자가 미완성 답 받아도 모르게 돼요.

헷갈리기 쉬운 자리 — EOS vs Stop Sequence
| EOS 토큰 | Stop sequence | |
|---|---|---|
| 누가 정함 | 모델 학습 시 박힘 | 사용자 API 호출 시 |
| 형태 | 특수 토큰 1개 | 임의 문자열 |
| 작동 | 모델이 자발적으로 뽑음 | 매칭되면 즉시 컷 |
| 영향 | 자연스러운 종료 | 강제 절단 |
비유로 말하면 이래요.
- EOS = 화자가 “이야기 끝났어요” 라고 마무리
- Stop sequence = 청자가 “어, 거기까지” 라고 잘라냄
흔한 사고
사고 1 — Stop sequence가 본문에 등장
stop="\n" 으로 두고 “들여쓰기 포함해서 출력해” 라고 프롬프트하면 → 모델이 첫 줄에 \n 넣자마자 거기서 잘려요.
사고 2 — Tokenizer 경계
stop="Human:" 인데 모델이 그걸 ["Hum", "an:"] 두 토큰으로 뽑으면 매칭이 안 될 수도 있어요. OpenAI는 후처리에서 잡지만, 일부 로컬 API는 토큰 경계 문제로 놓쳐요.
사고 3 — Max tokens 너무 짧음
긴 답 받으려면서 max_tokens=200 으로 두면 답이 중간에 잘려요. finish_reason: "length" 안 보면 인지 못 해요.
10. 잠깐, 여기서 큰 전환이 있어요
지금까지 우리가 다룬 7개 도구 — Beam search, Sampling, Temperature, Top-K/Top-P, Min-P, Repetition penalty, Stop sequences — 이건 다 “사람이 읽는 LLM 답”을 위한 거였어요.
자연스럽게, 다양하게, 반복 없이, 적절한 길이로 — 다 사람 독자가 만족하기 위한 미세조정이에요.
근데 갑자기 다른 종류의 사용 맥락이 등장해요.
마지막 도구 — Constrained Decoding — 은 사람이 아니라 프로그램이 LLM 답을 받는 자리에서 필요해진 도구예요.
11. “JSON으로만 답해” — Constrained Decoding
잠깐 — “JSON으로만 답해” 라는 지시는 어디서 나온 거예요?
여기서 자연스러운 막힘 자리예요.
지금까지 우리가 ChatGPT에 던지는 질문은 다 자연어였어요. “오늘 날씨 어때?”, “여행지 추천해줘”, “이 코드 짜줘” — 다 자연어로 답을 받았죠. 그럼 “JSON으로만 답해” 라는 지시는 누가 왜 던지는 거예요?
답을 한 줄로 이렇게 정리할 수 있어요.
사람이 ChatGPT 화면에서 답을 읽을 땐 JSON 강제가 필요 없어요. 프로그램이 LLM 답을 받아서 다음 단계로 넘길 때 필요해요.
풀어보죠.
두 가지 LLM 사용 패턴
패턴 A — 사람이 직접 LLM과 대화
ChatGPT 창에 “오늘 날씨 어때?” 던지면 → 모델이 자연어로 답함 → 눈으로 읽고 끝.
이게 지금까지 우리가 익숙한 LLM 사용 방식이에요. 여기선 자연어가 best.
패턴 B — 프로그램이 LLM을 도구로 씀
이게 4편의 진짜 새로운 자리예요. 구체 사례로 직진해봐요.
1. 이메일 비서 앱
이메일 들어옴 → 앱이 텍스트를 LLM에 넘김 → LLM이 답함
↓
앱이 그 답을 받아서 DB 저장 / 화면 표시
LLM 답이 자연어로 오면 — “이 이메일은 김철수씨가 보낸 회의 일정 안내입니다.” — 앱이 못 읽어요. 앱은 글을 안 읽거든요.
앱이 원하는 건 이런 거예요.
{
"sender": "kim@example.com",
"subject": "회의 일정",
"priority": "high"
}
이게 와야 앱이 data["sender"] 처럼 꺼내서 자동으로 분류·저장해요.
2. 영수증 앱 (가계부 자동 입력)
- 사용자가 영수증 사진 찍음
- 앱이 사진을 LLM에 넘김
- LLM 답:
{"date": "2026-05-20", "store": "스타벅스", "amount": 6500, "category": "음료"} - 앱이 자동으로 가계부 항목 추가
3. AI 에이전트의 도구 호출 (핵심)
사용자: “비행기 표 예약해줘. 인천에서 도쿄, 다음 주 화요일.”
LLM은 자연어 답이 아니라 실행할 action을 토해야 해요.
{
"action": "book_flight",
"from": "ICN",
"to": "NRT",
"date": "2026-05-26"
}
그래야 시스템이 받아서 실제 항공사 API 호출이 가능해요. 자연어 답으론 항공사 API를 못 부르거든요.
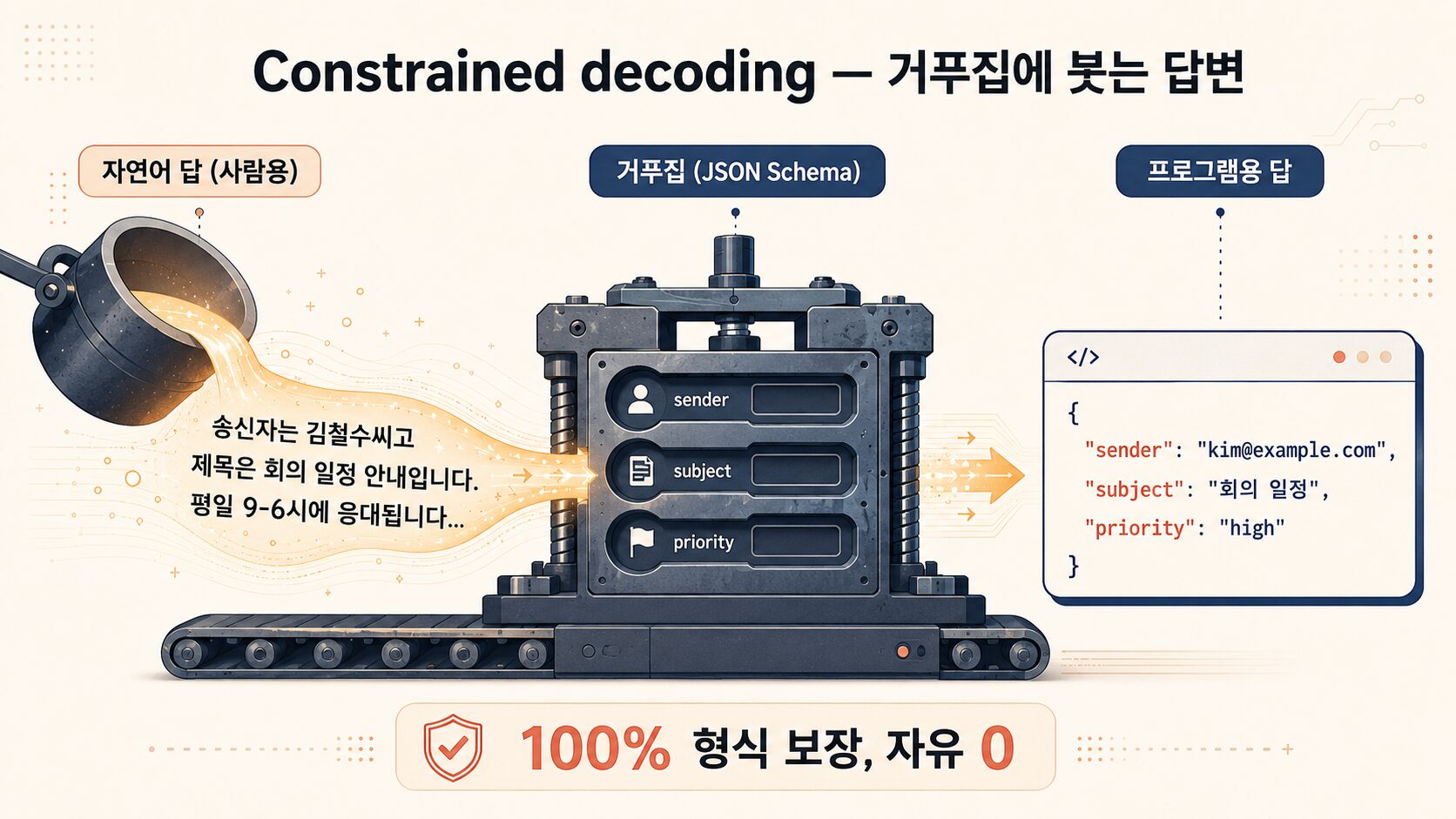
사람용 답 vs 프로그램용 답
사람용: "송신자는 김철수씨고 제목은 회의 일정 안내입니다."
프로그램용: {"sender": "kim@example.com", "subject": "회의 일정"}
같은 정보, 다른 형식. 프로그램은 “키 = 값” 짝으로만 정보를 꺼낼 수 있어요.
그럼 프롬프트로 부탁하면 충분하지 않을까요
JSON 답이 필요하다고 치고 가장 먼저 떠오르는 건 프롬프트예요.
"이메일에서 송신자와 제목을 JSON으로만 답해줘."
GPT-4o 같은 좋은 모델은 보통 따라줘요. 근데 가끔 사고 쳐요.
[정상] {"sender": "john@example.com", "subject": "회의"}
[사고 1] 다음은 JSON입니다: {"sender": "john@example.com", "subject": "회의"}
[사고 2] ```json
{"sender": "john@example.com", "subject": "회의"}
```
[사고 3] {"sender": "john@example.com", "subject": "회의" ← 닫는 brace 빠뜨림
[사고 4] {"sendr": "john@example.com", "subject": "회의"} ← 키 오타
작은 비율로 일어나지만, 100건 처리하면 1~2건은 깨져요. API 파이프라인에선 치명적이에요.
저도 처음엔 프롬프트만 잘 짜면 될 줄 알았어요. 근데 프롬프트는 확률적 부탁이지, 보장이 아니더라고요.
발상 — 디코딩 단계에서 강제
토큰 뽑을 때 허용된 토큰 외에는 아예 확률을 0으로 만들자.
매 step에서 이렇게 작동해요.
- 모델이 logit 계산 (어휘 12.8만 개)
- 현재 위치에서 허용 안 되는 토큰의 logit → −∞
- Softmax → 허용 토큰 중에서만 sampling
- 뽑힌 토큰으로 상태 전이
작은 사례 — JSON 상태 기계
JSON 출력이라고 치면, 매 step에서 허용되는 토큰이 정해져요.
상태 0 (시작) → 허용: {
상태 1 ( { 직후) → 허용: " (key) or } (빈 객체)
상태 2 (key 끝난 직후) → 허용: :
상태 3 ( : 직후) → 허용: " or { or [ or 숫자 or true/false/null
상태 4 (값 끝난 직후) → 허용: , or }
...
이 상태 전이를 유한 상태 기계 (FSA) 또는 문법 (CFG) 으로 표현. 매 step마다 다음 허용 토큰을 알려줘요.
결과: 수학적으로 보장된 JSON 출력. 닫는 brace 빠질 수 없고, 키 오타도 안 나와요. 형식상 깨지는 게 불가능해요.
Grammar로 일반화
JSON 외에도 다양한 형식 강제가 가능해요.
- 전화번호 형식 (
XXX-XXXX) - SQL 쿼리 (유효한 SQL만)
- HTML, XML, 임의의 정해진 패턴
핵심은 “이런 형식을 따라야 한다”는 규칙을 컴퓨터가 읽을 수 있게 적어주는 것이에요. 이걸 grammar (문법) 이라고 불러요.
예 — “이름과 나이만 있는 JSON” 을 규칙으로 적으면 (사람말로):
이름 = 따옴표 안에 글자들
나이 = 숫자
출력 = { "name": 이름 , "age": 나이 }
세부 표기법 (BNF, GBNF, JSON Schema 등)이 여러 가지 있는데 — 이름은 외울 필요 없어요. 핵심은 “형식을 규칙으로 적어두면, 그 규칙 안에서만 토큰을 뽑게 강제할 수 있다” 자리.
거푸집 비유
재료공학으로 비유하면 한 번에 꽂혀요.
프롬프트 방식 = 작업자한테 “이런 모양으로 만들어줘” 부탁.
- 작업자(모델)가 보통은 잘 만듦
- 가끔 모양 살짝 다르게 나옴 (개인 차)
Constrained decoding = 거푸집(mold)에 부어 굳히기.
- 거푸집 모양 그대로 100% 보장
- 단, 거푸집 외 모양은 못 만듦
캐스팅이 정확히 이래요 — 거푸집 만들 때 미리 정한 한도 안에서만 결과물이 나와요. 형상은 보장, 자유는 0.
어떤 도구로 쓸 수 있나
세부 이름은 외울 필요 없고, 알아둘 것 하나만 있어요.
클라우드 API (OpenAI, Anthropic, Google) 든 로컬 LLM (llama.cpp 등) 이든, 다 강제 기능 제공해요. 이름만 약간씩 달라요.
흔히 보이는 이름: “Tool use”, “Structured Outputs”, “Function calling”, “Grammar mode” — 다 같은 개념이에요.
트레이드오프
1. 모델 답이 메말라짐
자연스럽게 답하면 부연 설명도 하는데, 강제하면 schema 자리만 채워요.
자연 답: "전화번호는 010-1234-5678 이고, 사무실 연락처고요,
평일 9-6시에 응대됩니다."
강제 답: "010-1234-5678"
2. 살짝 느려짐 (5~15%)
매 토큰 뽑을 때마다 “다음에 허용되는 토큰이 뭔지” 한 번 검사하는 단계가 추가돼요.
3. 거푸집이 너무 빡빡하면 사고
예 — “나이를 정수로 무조건 채워라” 라고 강제했는데 모델이 정보를 모를 때.
- 모델이 어쩔 수 없이
0이나-1같은 이상한 값 채움 - 진실보다 형식이 우선해버려요
해결: schema에 “모를 때는 null 가능” 같은 여지를 두기.
프롬프트 vs 강제 — 단순히
프롬프트 방식 → "JSON으로 답해줘" → 보통 따라줌. 가끔 사고
강제 방식 → 거푸집에 붓기 → 100% 형식 보장. 자유 0
언제 뭘 쓰냐면 이래요.
- 자유 채팅 (가벼운 질문) → 프롬프트만
- 데이터 추출 (이메일 송신자, 영수증 항목) → 강제 권장
- AI 에이전트가 함수 호출할 때 → 강제 필수
왜 지금 이걸 배워야 하나
요즘 AI 트렌드의 본질은 이래요.
2023년까지: 사람이 ChatGPT 화면 보며 대화
2024년부터: AI가 다른 도구·앱·시스템을 호출
ChatGPT → Custom GPTs → AI 에이전트 (Claude Computer Use, OpenAI Operators 등) — 다 “LLM이 시스템에 끼워져서 도구 호출하는 시대” 로 가는 흐름이에요.
이때 LLM 답이 구조화된 데이터 (JSON) 로 안정적으로 나와야 시스템이 안 깨져요. Constrained decoding이 4편 마지막 자리에 있는 이유가 이거예요.
12. 자리별 권장값 — 한눈에
블로그에서 가장 자주 찾아볼 자리예요. 도구별로 묶어서 정리할게요.
Temperature
| 자리 | Temperature |
|---|---|
| 일반 채팅 | 0.7 |
| 창작 (시·소설) | 1.0~1.2 |
| 코드 생성 | 0.2~0.4 |
| 번역·요약 | 0 (Greedy) 또는 Beam search |
| 추론 모델 | 0.7~1.0 (다양성 필요) |
Top-P (nucleus)
| 자리 | Top-P |
|---|---|
| 일반 채팅 | 0.9 |
| 창작 | 0.95 |
| 코드 | 0.8 |
Min-P (로컬 LLM 위주)
| 자리 | Min-P |
|---|---|
| 일반 창작 | 0.05~0.1 |
| 고온 (T>1) 환경 | 0.1~0.3 |
| 일반 채팅 | 0 (off) |
Repetition Penalty
| 자리 | repetition_penalty |
|---|---|
| 일반 채팅 | 1.1 |
| 창작 (소설·시) | 1.2~1.3 |
| 코드 | 1.0 (off — 반복이 정상) |
| 번역 | 1.0 |
| 긴 글 (1만자+) | Windowed 또는 DRY sampler 권장 |
OpenAI Frequency / Presence Penalty
| 자리 | freq | pres |
|---|---|---|
| 일반 채팅 | 0.3 | 0.2 |
| 다양성 강조 | 0.5 | 0.5 |
| 일관성 중요 | 0 | 0 |
Stop Sequences
| 자리 | Stop sequences | Max tokens |
|---|---|---|
| 일반 채팅 | None (EOS만) | 2000~4000 |
| 코드 자동완성 | ["\n\n", "```"] |
500~1000 |
| Few-shot prompting | ["\n\n", "Q:", "Human:"] |
200~500 |
| 구조화된 출력 | 후처리로 잘라내기 | 1000 |
| 긴 글 생성 | None | 4000~8000 |
Constrained Decoding
| 자리 | 사용 |
|---|---|
| 자유 채팅 | Off |
| Function calling / Tool use | On (필수) |
| 데이터 추출 (이메일, 영수증) | On (JSON Schema) |
| SQL 쿼리 생성 | On (SQL grammar) |
| 일반 코드 생성 | Off (자연스러움 우선) |
| 학습용 / Chain-of-Thought | Off (자유 사고) |
이번 주 AI 흐름
13. 4편 정리 — 8개 도구의 누적
처음 질문으로 돌아가요.
한 토큰을 매번 best로 뽑으면, 그게 모여서 만들어진 문장 전체도 best일까?
답: 아니에요. 그리고 그 “아니에요”의 빈틈을 메우려고 8개 도구가 자라났어요.
| 도구 | 푸는 문제 |
|---|---|
| Beam search | 한 토큰 best ≠ 시퀀스 best |
| Sampling (3편) | best 확률 ≠ 자연스러운 텍스트 |
| Temperature | 분포 흔드는 강도 |
| Top-K, Top-P | 헛소리 토큰 잘라내기 |
| Min-P | Top-P가 평평한 분포에서 무너지는 자리 |
| Repetition penalty | 같은 토큰이 점점 더 나오는 루프 |
| Stop sequences | 언제 멈출지 결정 |
| Constrained decoding | 출력을 정해진 형식으로 강제 |
이 8개를 두 묶음으로 나누면 흐름이 한 번 더 풀려요.
“사람이 읽는 LLM 답”을 위한 7개
- Beam search (어떤 자리는 여전히 사용)
- Sampling, Temperature, Top-K, Top-P, Min-P
- Repetition penalty (+ Frequency/Presence)
- Stop sequences
“프로그램이 받는 LLM 답”을 위한 1개
- Constrained decoding
이게 4편이에요. LLM을 사람과 프로그램 둘 다에게 안전하게 끼워 넣을 수 있는 도구 한 세트.
핵심 정리 — LLM 디코딩 한 줄로
LLM 디코딩은 “한 토큰 best ≠ 시퀀스 best”에서 시작해서 “best 확률 ≠ 좋은 텍스트”를 거쳐 “사람용 답 vs 프로그램용 답”까지 메꾸는 8개 도구의 누적이에요. Beam search는 번역·요약 같은 정답이 좁은 자리에만 남았고, 채팅·창작은 Sampling + Temperature + Top-P/Min-P + Repetition Penalty + Stop Sequences 조합으로 갔고, AI 에이전트 시대에 등장한 Constrained Decoding은 출력을 거푸집에 부어 100% 형식 보장을 만들어요.
핵심 3가지:
-
한 토큰 best가 시퀀스 best가 아니에요. Greedy는 매 갈림길에서 가파른 길로 가는 산행 — 절벽으로 이어질 수도. Beam search는 폭(B)으로 타협. 다만 best 확률 시퀀스 ≠ 좋은 텍스트 라서 ChatGPT·Claude는 안 써요. 인간 글은 high-probability가 아니거든요.
-
Sampling 계열 도구는 일부러 best를 안 뽑기 위한 것. Temperature 흔들고 Top-P/Min-P로 헛소리 자르고 Repetition Penalty로 반복 막기. 그 균형 위에서 자연스러운 답이 나와요. Min-P는 평평한 분포에서 Top-P가 무너지는 자리를 풀려고 2023년에 등장.
-
Constrained Decoding은 디코딩의 새 자리에요. 사람이 ChatGPT 화면을 보던 시대에서 프로그램이 LLM 답을 받는 시대로 가면서 등장. JSON Schema · grammar 로 출력 형식을 거푸집처럼 강제. AI 에이전트의 도구 호출이 안 깨지는 이유가 이거예요.
다음 편 예고
5편: Attention — 토큰끼리 어떻게 서로를 보나
이번 글 내내 한 가지를 가정한 채로 갔어요 — 모델이 logit을 계산해서 던져준다 자체는 안 건드렸어요. 5편에서는 그 logit이 어떻게 만들어지는지로 내려가요. Q · K · V가 진짜로 어떤 일을 하는지, 사과가 근면한 옆에서 의미가 바뀌는 메커니즘이 무엇인지, 1편의 문맥 임베딩과 3편의 KV 캐시가 둘 다 5편으로 이어져요.
→ 6편: Transformer — 그 attention이 어떤 구조 안에서 작동하는가
→ 7편: 양자화·RAG·Fine-tuning — 시리즈 마무리
즉 4편이 디코딩 = 모델 출력을 어떻게 변환하나 였다면, 5/6편은 그 출력 자체가 어떻게 만들어지나 로 한 단계 더 내려가요.
자주 묻는 질문
Q. LLM 디코딩이 정확히 뭐예요?
모델이 logit을 토해낸 다음에 그걸 *실제 토큰*으로 변환해서 한 문장으로 잇는 과정 전체를 디코딩이라고 불러요. Sampling으로 한 토큰을 뽑고, Temperature·Top-P로 분포 모양을 조절하고, Repetition Penalty로 반복을 막고, Stop Sequence로 멈출 자리를 정하고, 필요하면 Constrained Decoding으로 형식까지 강제. 8개 도구가 누적되어 한 문장이 만들어져요.
Q. Beam search는 왜 ChatGPT·Claude에선 안 쓰이나요?
*best 확률 시퀀스*와 *좋은 텍스트*가 다르기 때문이에요. Beam search는 매번 가장 높은 확률을 충실히 따라가다 같은 구절을 반복하는 *퇴화 루프*에 빠지고, 살아남은 B개 후보가 다 비슷한 *모드 붕괴*도 일어나요. 인간 글은 확률이 들쭉날쭉한 게 자연스러움이에요. 다만 번역·요약처럼 정답이 좁은 자리에선 여전히 Beam search가 현역이에요 (Google 번역, DeepL 등).
Q. Top-P랑 Min-P 차이가 뭐예요?
Top-P는 절대 누적 기준 — “확률 누적이 90%에 도달할 때까지 토큰을 살리자”. Min-P는 상대 기준 — “1등 토큰 확률의 10% 미만은 자르자”. 분포가 평평할 때 Top-P=0.9는 누적 채우려고 헛소리 토큰까지 데려오지만, Min-P=0.1은 1등 대비 비율로 잘라 깔끔. 특히 Temperature를 올린 *고온 sampling*에서 Min-P가 빛나요. 로컬 LLM (llama.cpp, KoboldAI) 커뮤니티에서 먼저 자리 잡았어요.
Q. AI가 같은 단어를 반복할 때 Repetition Penalty를 무조건 켜면 되나요?
짧은 글에선 OK (1.1~1.3 권장). 근데 긴 글에선 부작용이 있어요. 페널티는 *등장한 토큰만* 감점하니까, “그래서·근데·그리고” 같은 흔한 접속사가 가라앉는 동안 “고로·하옵고·기실·이에” 같은 어휘집 변두리의 옛 한국어 접속사가 상대적으로 부풀어 올라요. *조선시대 접속사 도망*이라고 부르는 자리. 해결은 Windowed penalty (최근 N토큰만) 또는 DRY sampler (n-gram 단위로 감지).
Q. *JSON으로만 답해* 라는 프롬프트로 충분하지 않나요?
GPT-4o 같은 좋은 모델은 보통 따라줘요. 근데 100건 처리하면 1~2건은 깨져요 — 닫는 brace를 빠뜨리거나, 키 오타를 내거나, “다음은 JSON입니다:”를 앞에 붙이거나. API 파이프라인에선 치명적. Constrained Decoding은 디코딩 단계에서 허용 안 되는 토큰의 확률을 0으로 만들어 *수학적으로* 형식을 보장. AI 에이전트가 도구 호출할 땐 사실상 필수예요. 이름이 *Tool use*, *Structured Outputs*, *Function calling*, *Grammar mode* 여러 가지인데 다 같은 개념.
Q. Temperature·Top-P·Min-P·Repetition Penalty 권장값이 한 줄에 정리되나요?
일반 채팅: T=0.7 · Top-P=0.9 · rep_penalty=1.1. 창작: T=1.0~1.2 · Top-P=0.95 · rep_penalty=1.2~1.3. 코드: T=0.2~0.4 · Top-P=0.8 · rep_penalty=1.0(off — 반복이 정상). 번역·요약: T=0 (Greedy) 또는 Beam search. 추론 모델: T=0.7~1.0 (다양성 필요). 로컬 LLM에서 고온으로 갈 땐 Min-P=0.1~0.3 추가. 본문 12장에 풀 표 있어요.
소스 / 더 읽을거리
- Holtzman, A., Buys, J., Du, L., Forbes, M., Choi, Y. (2019). “The Curious Case of Neural Text Degeneration.” ICLR 2020 논문
- Nguyen et al. (2023). “Min P Sampling: Balancing Creativity and Coherence at High Temperature.” arXiv
- OpenAI API Reference — Chat Completions · Structured Outputs
- Anthropic — Tool use documentation
- llama.cpp — GBNF grammar ·
--repeat-last-noption - p-e-w. (2024). DRY (Don’t Repeat Yourself) sampler — GitHub PR
- 본 시리즈 1~3.5편 — 1편 가중치 · 2편 학습 · 3편 추론 · 3.5편 AI 추론 모델
저자: VibeCoding Tailor (테이라)
shuntailor.net 운영. 고려대 공대생 · Lovable 공식 앰버서더. 고려대 캠퍼스타운 창업 경진대회 우수상으로 교내 창업사무실에 입주, 지금은 개발에 집중 중. 내가 IT·AI를 공부하며 막힌 지점은 모두가 막힐 지점이라는 가정으로, 그 막힘을 하나씩 깊이 파헤쳐 「쉽깊잼(쉽고·깊고·재미있게)」을 실현한다. 이 블로그는 AI 시대의 표준을 만들기 위해 시작한 미디어다.