AI에 UI를 맡기면 왜 전부 같은 화면이 나올까——DESIGN.md와 Google Stitch로 결과 편차 줄이기
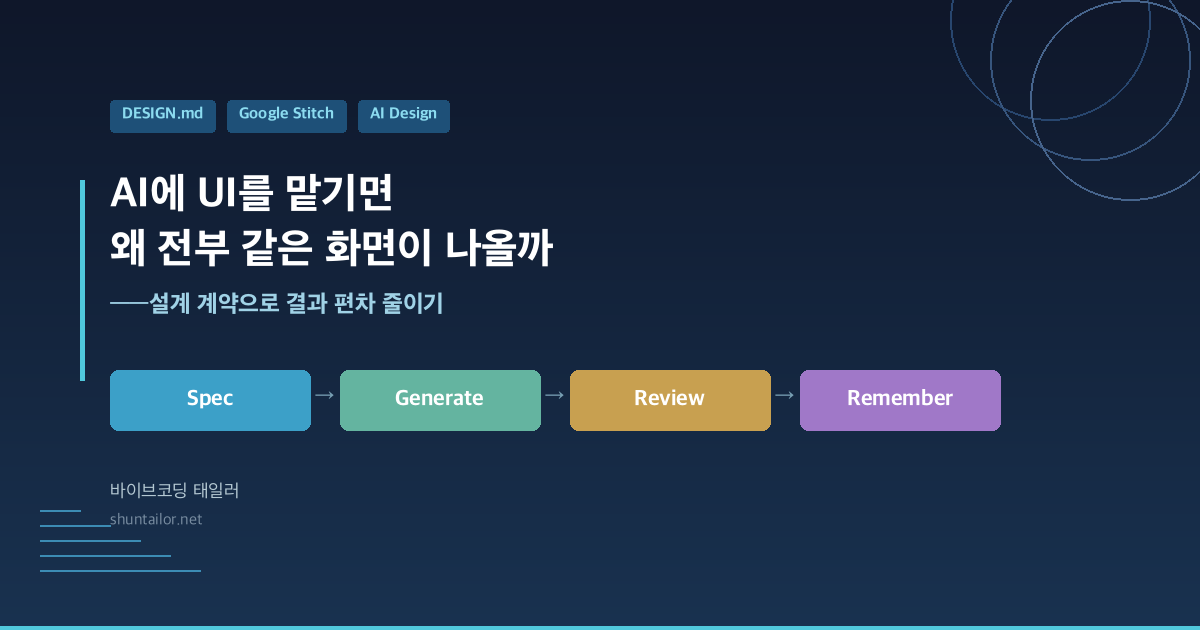
DESIGN.md와 Google Stitch를 조합하면 AI가 생성하는 화면의 편차를 크게 줄일 수 있습니다. “더 좋은 생성 툴로 바꾸면 결과도 좋아질 거야”——그렇게 생각해서 여러 번 툴을 갈아탄 경험이 있지 않나요? 결과의 흔들림을 줄이는 건 툴 성능보다, 에이전트가 반복해서 읽을 수 있는 설계 계약과 검수 루프입니다. 이 글에서는 AI가 만든 화면이 왜 비슷해지는지 정리하고, DESIGN.md라는 설계 계약 파일과 … Read more