
AI 에이전트 로그 기록 방법【2026년 최신】Simon Willison식 5단계 완전 가이드
AI 에이전트 로그 기록 방법이란, AI에 작업을 맡긴 후 「무엇을 지시했는지」「AI가 어떻게 움직였는지」「어떤 툴을 사용했는지」를 추적할 수 있도록, 프롬프트·응답·툴 사용·실행자·사용 모델의 5요소를 구조화해서 보존하는 워크플로우다. 2026년 4월, Simon Willison이 공개한 LLM 툴 릴리즈를 보면, 그가 이 워크플로우를 「채팅하고 끝」이 아니라 「SQLite에 기록하고 Datasette로 다시 볼 수 있는 운영 시스템」으로 설계하고 있음을 알 수 있다.
이 글에서는 그 접근법을 한국어로 체계적으로 해설한다. 파일 로그부터 시작해 Simon식 SQLite+뷰어 구성까지, 자신의 페이스에 맞게 단계별로 진행할 수 있는 3단계로 소개한다.
AI 에이전트 로그 기록 방법——지금 왜 필요한가
AI를 한 번 쓰고 결과를 복사해 붙여넣고 끝, 이라는 사용법을 하는 사람이 많다. 그런데 이런 경험은 없는가?
- 지난주 AI에게 만들게 한 코드가 「왜 이렇게 됐는지」를 모르게 됐다
- 같은 프롬프트를 재현하려 했지만 잘 안 됐다
- 팀원이 AI에게 무엇을 지시했는지 파악할 수 없다
- 비용 최적화를 위해 어떤 모델을 어떤 작업에 사용했는지 돌아보고 싶다
이것들은 모두 로그가 없기 때문에 생기는 문제다. AI 에이전트 로그 기록 방법을 실천하면, 결과가 예상과 달랐을 때 「프롬프트가 문제였는지」「툴이 오작동했는지」「모델의 한계였는지」를 정확히 추적할 수 있게 된다.
Simon Willison은 이를 이렇게 표현한다——「AI에게 일을 시키면, 무슨 일이 일어났는지 나중에 다시 볼 수 있게 만들어라」. 심플하지만, AI가 업무에 들어온 2026년에는 이것이 운영의 기본이 된다.
관련: 하네스 엔지니어링 완전 가이드 / 에이전틱 엔지니어링 완전 가이드
AI 에이전트 로그 기록 방법——기록해야 할 5가지 요소
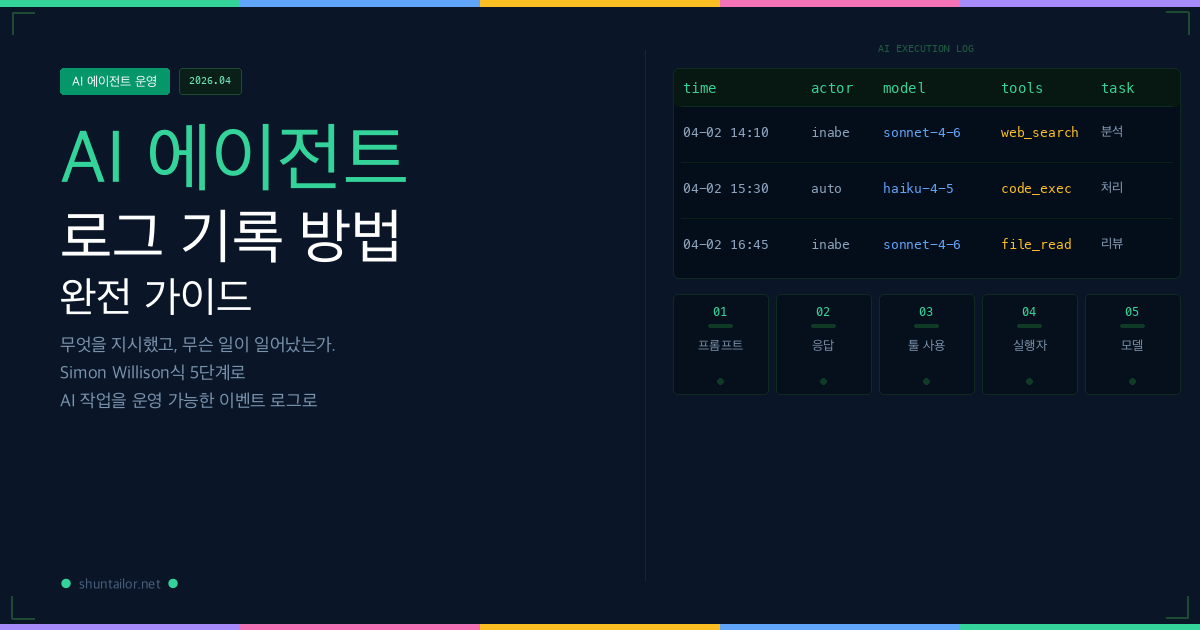
AI 에이전트 로그 기록 방법에서 보존해야 할 정보는 5가지로 압축된다. 어느 레벨의 구현부터 시작하더라도, 이 5요소가 갖춰지면 「나중에 추적 가능한 로그」가 된다.
지시했는가
답했는가
행동 로그
실행했는가
어떤 작업에
1. 프롬프트——지시의 기록
AI에게 무슨 말을 했는지 남긴다. 결과가 예상과 달랐을 때 프롬프트 작성이 원인이었는지 판단할 수 있다. 「그때 뭐라고 입력했더라」가 사라진다.
2. 응답——AI의 판단 기록
AI의 답변을 남긴다. 결과뿐 아니라 AI가 어떤 판단 흐름으로 답했는지 나중에 읽을 수 있게 된다. 미묘하게 다른 결과가 나왔을 때의 비교 분석에도 사용할 수 있다.
3. 툴 사용——중간 행동의 기록
웹 검색, 파일 읽기, 코드 실행 같은 중간 행동을 남긴다. 에이전트가 「무엇을 조사하고, 무엇을 실행한 결과 이 답이 나왔다」는 행동 로그가 생긴다.
4. 실행자(actor)——책임의 기록
자신이 실행했는지, 팀원이 실행했는지, 자동화가 실행했는지 남긴다. 누구의 지시로 무슨 일이 일어났는지 명확해지고 운영상의 책임 범위가 정리된다.
5. 사용 모델——비용·품질의 기록
어떤 작업에 어떤 모델을 사용했는지 남긴다. 나중에 「이 작업은 Opus보다 저렴한 모델로 충분했다」「이 작업만 정확도가 떨어졌다」는 최적화가 가능해진다.
Simon Willison이 2026년 4월에 구현한 로그 시스템
Simon Willison은 오픈소스 툴 「llm」의 제작자이며, Python의 Django 프레임워크 코어 멤버이기도 한 개발자다(출처: Simon Willison April 2026 archive). 그의 공개 릴리즈를 추적하면 AI 에이전트 로그 기록 방법의 구현이 구체적으로 보인다.
2026년 4월 1일 릴리즈에서 반복해서 나오는 포인트는 다음과 같다.
- llm_prompt_context()를 통한 체인 내 프롬프트 추적과 tool call loop 추적
- prompts·responses·tool calls를 내부 SQLite 테이블에 기록
- usage 페이지에 permission 추가(누가 무엇을 사용할 수 있는지 관리)
- 모델 구성을 작업 목적별로 분류: enrichments purpose、extract purpose
- actor를
llm.mode(... actor=actor)로 전달 - default model과 allowed models 정리
주목할 것은 「actor를 전달할 수 있게 한」 변경이다. 이로써 로그에 「누가 실행했는지」가 들어가게 됐다. 툴을 사용했다는 사실뿐 아니라, 누구의 의사결정으로 그 툴이 동작했는지가 기록된다. 이는 개인 사용에서 소규모 팀으로의 스케일 업에 필수적인 변경이다.
📩 매주 월요일, AI 트렌드 뉴스레터를 배포하고 있습니다
회원 등록하면 매주 월요일에 「이번 주 AI·바이브코딩 최신 정보」를 보내드립니다.
기사에서는 쓸 수 없는 실전 노하우도 회원 한정으로 공개하고 있습니다.
AI 에이전트 로그 기록 방법——Simon식 5단계 워크플로우
Simon의 공개 툴과 릴리즈에서 확인할 수 있는 워크플로우를 5단계로 정리한다.
자동 저장
tool calls·usage가
로컬 DB에
축적된다
모델 분류
extract용 등
작업별로 허용
모델 제어
로그에 포함
actor=로 지정.
개인→팀으로의
확장이 쉬워짐
Simon식의 중요한 포인트는 「저장은 목적이 아니라, 나중에 다시 볼 수 있는 것이 목적」이라는 자세다. SQLite에 데이터가 쌓여도, Datasette에서 검색할 수 있는 상태로 해두지 않으면 의미가 없다. datasette "$(llm logs path)"라는 한 줄의 명령어로, 브라우저에서 모든 AI 실행 로그를 검색·필터할 수 있게 된다(출처: simonw/llm README).
AI 에이전트 로그 기록 방법——3가지 구현 레벨
지금 당장 시작할 수 있는 가장 단순한 구현부터 Simon식에 가까운 본격적인 구현까지, 3가지 레벨로 소개한다.
| 레벨 | 방법 | 필요 스킬 | 적합한 규모 | Simon식과의 거리 |
|---|---|---|---|---|
| Level 1 | Markdown / 텍스트 파일 | 없음 | 개인·월 10회 이하 | 먼 편 (수동) |
| Level 2 | CSV / Google 스프레드시트 | 스프레드시트 기초 | 개인~소규모 팀 | 중간 |
| Level 3 | llm CLI + SQLite + Datasette | 터미널 기초·pip | 소규모~중규모 팀 | 가까움 (자동 기록) |
오늘부터 시작하는 실천 5단계
어느 레벨부터 시작하든, 이 5가지를 의식하는 것만으로 「추적 가능한 AI 운영」으로 바뀐다.
- AI에게 지시한 프롬프트를 남긴다——복사 붙여넣기로 충분. 어딘가에 기록하는 습관만 가지면 된다
- AI의 답변도 남긴다——결과뿐 아니라 판단의 흐름을 나중에 읽을 수 있도록 한다
- 사용한 툴을 적어둔다——「web_search」「code_execution」「file_read」 등 중간 행동도 기록
- 누가 실행했는지 입력한다 (actor)——자신의 이름으로 충분. 팀화했을 때 책임 추적에 사용 가능
- 어떤 모델을 어떤 작업에 사용했는지 남긴다——나중에 비용 최적화·품질 분석에 도움이 됨
이 5가지가 쌓이면, 그것이 개인 또는 소규모 팀의 AI 운영 하네스가 된다(관련: 하네스 엔지니어링이란).
AI 에이전트 로그 기록 방법 자주 묻는 질문
Q. AI 에이전트 로그 기록 방법은 어떤 툴부터 시작하면 좋을까요?
가장 간편한 것은 Markdown 파일에 수동으로 기록하는 것(Level 1)입니다. 오늘 사용한 프롬프트·응답·툴·actor·모델을 파일 하나에 쓰는 것만으로 시작할 수 있습니다. 습관이 되면 CSV(Level 2) → llm CLI + SQLite(Level 3)로 단계를 올리는 것이 현실적입니다.
Q. AI 에이전트 로그 기록 방법에서 actor란 무엇을 가리키나요?
「누가 그 실행을 행했는가」를 나타내는 필드입니다. 개인 사용이라면 자신의 이름(예: inabe)으로 충분합니다. 팀에서 사용하는 경우는 담당자명·봇 이름·자동화 시스템명 등을 입력합니다. Simon Willison은 llm.mode(... actor=actor)로 명시적으로 전달할 수 있도록 구현했습니다. actor가 있으면 문제 발생 시 「누구의 지시가 원인이었는지」를 추적할 수 있습니다.
Q. Simon의 llm 툴과 Datasette, 한국어 환경에서도 동작하나요?
네, 둘 다 Python제 CLI 툴로 한국어 환경에서도 문제없이 동작합니다. pip install llm으로 llm을 설치하고, pip install datasette로 Datasette를 설치할 수 있습니다. API 키 설정은 llm keys set openai나 llm keys set anthropic으로 할 수 있습니다. 자세한 내용은 simonw/llm GitHub을 참조하세요.
Q. AI 에이전트 로그 기록 방법은 얼마나 많은 스토리지가 필요한가요?
LLM 호출 한 번의 로그는 수KB에서 수십KB 정도입니다. 하루 100회 실행해도 월 수MB 수준입니다. SQLite는 압축이 효율적이라 수만 번의 로그도 수백MB에 수렴하는 경우가 많습니다. 로컬 저장이므로 클라우드 스토리지 비용은 발생하지 않습니다.
저자: VibeCoding Tailor(Lovable 공식 앰배서더)
운영: テイラーの隠れ家(shuntailor.net)
- Simon Willison April 2026 archive: simonwillison.net/2026/Apr/
- simonw/llm GitHub README: github.com/simonw/llm
- Language models on the command-line: github.com/simonw/language-models-on-the-command-line
- Datasette documentation: datasette.io




