

4월 2일에 나온 Google Gemma 4. 가장 작은 모델(2.3B)이 전 세대 가장 큰 모델(27B)을 수학이랑 코딩에서 이겼다. 12배 작은 모델이 더 똑똑하다. 대체 무슨 일이 벌어지고 있는 건지 정리해봤다.
2.3B가 27B를 이겼다는 게 무슨 뜻이야
“B”는 Billion, 10억이다. 2.3B면 23억 개의 파라미터, 27B면 270억 개. 파라미터는 모델이 학습한 지식을 저장하는 칸이라고 보면 된다. 지금까지는 이 칸이 많을수록 똑똑한 게 상식이었다.
근데 Gemma 4에서 그게 깨졌다.
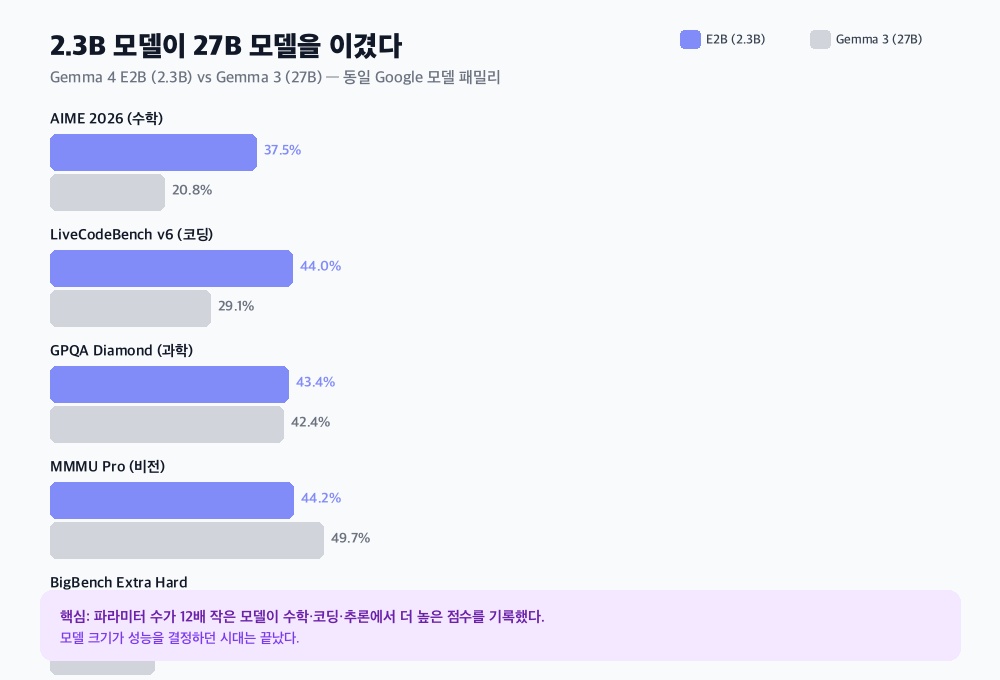
수학 올림피아드 수준 문제(AIME 2026)에서 2.3B가 37.5%, 27B가 20.8%. 코딩(LiveCodeBench)에서 44% 대 29%. 복합 추론(BigBench Extra Hard)에서는 74% 대 19%로 아예 격차가 안 된다.
Reddit r/LocalLLaMA에서 156점 받은 댓글이 분위기를 잘 보여준다.
“E2B가 Gemma 3 27B를 거의 모든 벤치마크에서 능가한다는 게 믿기지 않는다.” — u/Cubow
단, 이미지 이해(MMMU Pro)에서는 아직 27B가 앞선다. 44.2% 대 49.7%. 비전은 여전히 모델 크기가 중요한 영역이다.
내 폰에서 돌아가?
솔직히 이게 가장 궁금할 거다.
Gemma 4는 4가지 크기로 나온다. 가장 작은 E2B(2.3B)부터 가장 큰 31B까지. 이 중 스마트폰에서 돌아가는 건 E2B와 E4B 두 개다.
Google이 공식 측정한 속도가 있다. 다만 측정 기기가 아직 안 나온 iPhone 17 Pro와 Galaxy S26 Ultra라서 참고값으로 봐야 한다.
| 기기 | 모델 | 속도 |
|---|---|---|
| iPhone 17 Pro (GPU) | E2B | 56.5 tok/s |
| iPhone 17 Pro (GPU) | E4B | 25.1 tok/s |
| Galaxy S26 Ultra (GPU) | E2B | 52.1 tok/s |
| Galaxy S26 Ultra (GPU) | E4B | 22.1 tok/s |
E2B 기준 50 tok/s 이상이면 실시간 대화에 충분하다. 문제는 발열이다.
일본인 개발자 @knshtyk가 iPhone 15 Pro Max에서 E4B를 실제로 돌렸다.
“발열 문제로 Thinking 단계에서부터 이미 느려짐. 본문 생성 시작하면 잠깐 속도 회복했다가 다시 저하.” — @knshtyk, X
요약하면: E2B는 폰에서 실용적이다. E4B는 돌아가긴 하는데 Thinking 모드 켜면 열받는다. 26B 이상은 폰에서 포기해야 한다.
Reddit에서는 Nothing Phone 3a(8GB)에 Termux로 E2B를 올린 사람도 있다. “basic한 코딩은 되더라”고 했다.
4종 모델, 뭐가 다른가

E2B (2.3B) — 가장 작다. 폰, 라즈베리 파이에서 돌아간다. 텍스트·이미지·음성 다 된다. 이게 Gemma 3 27B보다 대부분의 벤치마크에서 높다는 게 이번 릴리스의 가장 큰 뉴스.
E4B (4.5B) — E2B보다 정확한데 폰에선 열이 난다. 노트북이 현실적인 최소 기기.
26B A4B — 여기서 이름이 헷갈릴 수 있다.
- 총 파라미터: 25.2B (반올림해서 26B)
- 한 번에 활성화되는 파라미터: 3.8B (반올림해서 A4B)
- 나머지 21B는 잠들어 있다
이걸 MoE(Mixture of Experts)라고 부른다. 전문가 128명이 대기하고 있다가 질문이 들어오면 8명만 골라서 답하는 구조다. 전체 인건비는 128명분이지만 실제 일하는 건 8명이니까, 연산 비용이 확 줄어든다.
이론적으로는 멋진데, 실제로는 속도 문제가 터졌다. 같은 GPU(RTX 5060 Ti 16GB)에서 Qwen 3.5가 60+ tok/s인데 Gemma 4 26B A4B는 11 tok/s. 6배 차이. 커뮤니티가 가장 많이 불만을 표출한 부분이다.
RTX 4090처럼 VRAM이 넉넉한 GPU에서는 ~135 tok/s로 빠르다. 전문가 128명을 미리 다 메모리에 올릴 수 있어서다. 결국 이 모델은 GPU를 고르는 모델이다.
31B Dense — 제일 크고 제일 똑똑하다. 모든 파라미터가 항상 일한다. Arena AI 오픈 모델 세계 3위(ELO 1452). Codeforces에서 ELO 2150 — 인간 경쟁 프로그래머 상위 2% 수준. 4090에서 ~38 tok/s, 5090에서 50~60 tok/s.
전 세대에서 얼마나 달라졌나
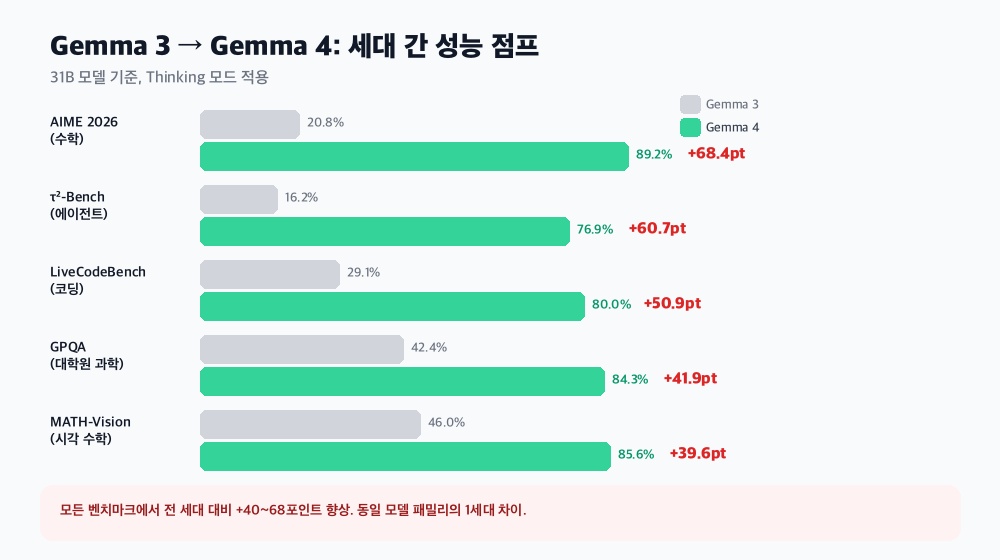
31B끼리 비교하면 규모감이 다르다.
- 수학(AIME): 20.8% → 89.2%. 4배 이상.
- 에이전트(τ²-Bench): 16.2% → 76.9%. 5배.
- 코딩(LiveCodeBench): 29.1% → 80.0%.
이건 모델 크기를 키운 게 아니라 설계를 바꾼 결과다. 특히 “Thinking 모드” — 답하기 전에 단계적으로 생각하는 기능이 이번에 추가됐는데, 수학 점수가 4배 오른 건 이것의 영향이 크다.
재밌는 건 Gemma 4의 Thinking이 “과잉 사고”를 안 한다는 점이다.
“‘Hi’라고 인사하면 Gemma는 30 토큰으로 답한다. Qwen은 7,000 토큰 동안 사색에 빠진다.” — u/Far-Low-4705, r/LocalLLaMA
Qwen 3.5랑은 뭐가 다른가
오픈 모델 쓰는 사람이라면 이게 가장 궁금할 거다. 결론부터 말하면 용도가 다르다.
| Gemma 4 31B | Qwen 3.5 27B | |
|---|---|---|
| 수학 (AIME) | 89.2% | ~48% |
| 지식 (MMLU Pro) | 85.2% | 86.1% |
| Arena ELO | 1452 | 1399 |
| 로컬 속도 | ~38 tok/s | ~45 tok/s |
| 이미지 이해 | 보통 | 우수 |
| 에이전트 코딩 | 보통 | 우수 |
| 다국어 | 우수 | 영어·중국어 외 약함 |
| 창작 글쓰기 | 우수 | 열위 |
코딩하거나 에이전트 돌리려면 Qwen. 번역하거나 글 쓰려면 Gemma. 한국어 포함 비영어권 언어에서는 Gemma가 낫다.
다국어 차이가 어느 정도인지 Reddit 댓글이 잘 보여준다.
“덴마크어·노르웨이어·스웨덴어에서 Qwen은 결과의 50%가 존재하지 않는 단어다.” — u/Ok-Drawer5245, r/ollama
Apache 2.0 — 숫자보다 중요한 변화
Gemma 1~3은 Google 독자 라이선스였다. 사용자 수 제한이 있고, 금지 조항이 붙어 있었다. 기업 법무팀이 “이거 갖다 쓰면 안 됩니다”라고 막는 경우가 있었고, 그래서 많은 기업이 Qwen이나 Mistral로 갔다.
Gemma 4부터 Apache 2.0이다. 상용 이용, 재배포, 수정 전부 자유. 사용자 수 제한 없음. 오프라인 운영 가능.
VentureBeat는 이렇게 평가했다.
“벤치마크 향상보다 이 라이선스 변경이 더 중요할 수 있다.” — VentureBeat
비교하면 Llama 4는 아직 월간 사용자 7억 명 제한이 있는 Meta 독자 라이선스다. Qwen 3.5는 Gemma와 같은 Apache 2.0.
출시 3일 만에 터진 문제들
좋은 말만 할 수는 없다. 4월 5일 기준으로 커뮤니티가 발견한 것들.
KV 캐시 버그 (수정됨) — 출시 직후 VRAM을 비정상적으로 잡아먹었다. 24GB GPU에서 컨텍스트가 12K밖에 안 됐다. 4월 4일 llama.cpp 업데이트로 수정돼서 지금은 45K까지 가능. (Reddit 495점 스레드)
MoE 속도 — 위에서 말한 대로, 16GB GPU에서 Qwen 대비 1/6 속도. 커뮤니티 최대 불만.
에이전트 작업 신뢰도 — 함수 호출(tool calling)에서 Qwen보다 실수가 잦다는 보고.
124B는 어디 갔나 — 출시 전에 Jeff Dean(Google AI 수장)이 X에서 124B MoE를 언급했다가 삭제했다. 실제로는 안 나왔다. Reddit에서 130점 받은 댓글: “Gemma 팀이 Gemini 팀보다 좋은 모델 만들면 안 되잖아.”
그래서 뭐가 달라지는 건데
“AI는 커져야 좋아진다”는 상식이 있었다. GPT-3(175B) → GPT-4(추정 1.8T) → 모델은 계속 커졌고, 더 큰 모델이 더 똑똑했다.
Gemma 4가 보여주는 건 그 반대다. 2.3B가 27B를 이기고, 라즈베리 파이에서 돌아가고, 스마트폰에서 초당 50단어 이상을 쏟아낸다.
이건 “AI가 싸졌다”가 아니라 “AI가 들어갈 수 있는 곳이 달라졌다”는 뜻이다. 서버실에만 있던 게 주머니 속으로 들어왔다. 인터넷 없이도 된다. 내 데이터가 밖으로 나가지 않는다.
물론 GPT-5나 Claude 4.x 같은 대형 모델에는 아직 못 미친다. 그건 인정해야 한다. 하지만 “내 기기에서 무료로 돌리는 AI” 기준으로는 역대 최고 수준이 됐다. 거기에 Apache 2.0이 붙었다.
작아지면서 강해지는 게 2026년 오픈 모델의 방향이다. Gemma 4가 그 첫 번째 명확한 증거다.
자주 묻는 질문
내 폰에서 직접 돌려볼 수 있어?
된다. Google AI Edge Gallery 앱을 깔면 iPhone, Galaxy 모두 E2B를 바로 테스트할 수 있다. E4B는 RAM 8GB 이상에서 동작하는데, Thinking 모드를 켜면 열이 오르니까 노트북이 현실적이다.
“26B A4B”에서 숫자가 왜 이렇게 많아?
26B = 총 파라미터 수(25.2B 반올림). A4B = 실제 활성화되는 파라미터(3.8B ≒ 4B). 128명의 전문가 중 8명만 일하는 MoE 구조라서 전체와 활성이 다르다. 메모리엔 26B분을 올려야 하지만 연산은 4B분만 한다.
ChatGPT 대신 쓸 수 있어?
완전 대체는 아직 어렵다. GPT-5, Claude 4.x 같은 대형 모델이 전반적으로 앞선다. 하지만 인터넷 없이 내 기기에서 무료로 쓰고 싶다면 현재로서는 Gemma 4가 최선이다.
Qwen 3.5랑 뭘 골라야 해?
코드 쓰거나 자동화 돌리려면 Qwen. 글 쓰거나 번역하려면 Gemma. 한국어 포함 비영어권 언어에서는 Gemma가 낫다.
출처
- Google DeepMind 공식: deepmind.google
- Hugging Face 기술 해설: huggingface.co
- VentureBeat 라이선스 분석: venturebeat.com
- LiteRT 모바일 벤치마크: huggingface.co/litert-community
- Reddit r/LocalLLaMA (2,231점): reddit.com
- Reddit Qwen 비교 (823점): reddit.com
- Reddit KV 캐시 수정 (495점): reddit.com
- X @knshtyk iPhone 실측: x.com
- Artificial Analysis: artificialanalysis.ai




