

SWE-bench 점수는 코딩 AI의 수능 점수가 아니다. “특정 문제 세트 + 특정 테스트 설계 + 특정 실행 환경 + 특정 scaffold” 조건에서의 해결률이다. 이 글에서는 그 조건을 읽는 7가지 축을 정리한다.
새로운 코딩 AI가 등장할 때마다 “SWE-bench에서 ○○% 달성”이라는 헤드라인이 쏟아진다. 그런데 그 숫자 하나로 “이 AI가 코딩을 잘한다”고 판단하는 건, 시험 종류도 채점 방식도 확인하지 않고 점수만 비교하는 것과 같다.
읽고 나면 벤치마크 숫자를 볼 때 “누가 몇 점인가”가 아니라 “무엇을, 어떤 조건에서 측정했는가”를 먼저 확인하게 될 것이다.
1. SWE-bench는 대체 뭘 측정하는가
SWE-bench는 “코드를 생성할 수 있는가”가 아니라 “실제 버그 리포트를 읽고, 저장소에서 해당 부분을 찾아내고, 수정 패치를 만들어, 숨겨진 테스트를 통과시킬 수 있는가”를 측정한다.
Princeton 대학 팀이 2023년에 발표한 오리지널 버전(core)은 12개 Python 저장소에서 추출한 2,294개 issue로 구성되어 있다. 모델이 받는 건 issue 설명문과 저장소 상태뿐이다. 정답 패치도 채점 테스트도 보이지 않는다.
FAIL_TO_PASS와 PASS_TO_PASS를 둘 다 통과해야 ‘해결’로 인정된다. 버그를 고쳐도 다른 기능을 깨뜨리면 탈락한다. 점수에는 “버그 수정력”뿐 아니라 “회귀 방지력”까지 포함되어 있다.
2. SWE-bench는 실제로 어떻게 채점하는가
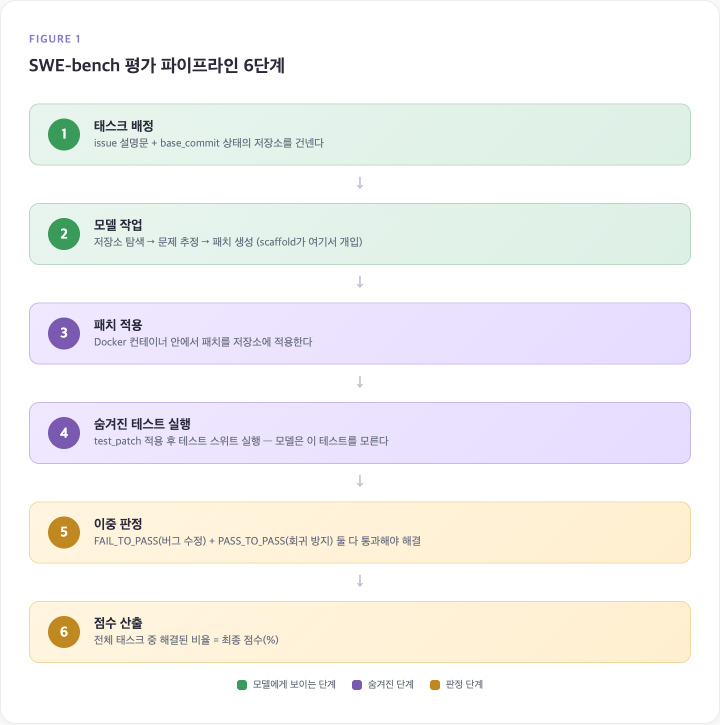
벤치마크 점수를 읽으려면 “무엇을 측정하는가”보다 “어떤 과정을 거쳐서 숫자가 나오는가”를 먼저 알아야 한다.
① 태스크 배정 — 모델에게 issue 설명문 + base_commit 상태의 저장소를 건넨다. 정답 패치, 채점 테스트, FAIL_TO_PASS 목록은 건네지 않는다.
② 모델 작업 — 모델(또는 에이전트 시스템)은 저장소를 탐색하고, 문제 원인을 추정하고, 수정 패치를 생성한다. 이 단계에서 scaffold(검색 도구, 리트라이 루프, 턴 제한 등)가 개입한다.
③ 패치 적용 — 생성된 패치를 Docker 컨테이너 안의 저장소에 적용한다. 적용 자체가 실패하면 그 시점에서 미해결 처리.
④ 숨겨진 테스트 실행 — test_patch를 적용한 뒤 테스트 스위트를 실행한다. 모델은 이 테스트의 존재도, 내용도 모르는 상태에서 패치를 썼다.
⑤ 이중 판정 — FAIL_TO_PASS(버그 수정) + PASS_TO_PASS(회귀 방지) 둘 다 통과해야 “해결”로 인정된다.
⑥ 점수 산출 — 전체 태스크 중 해결된 비율 = 최종 점수(%).
모든 SWE-bench가 같은 파이프라인을 쓰는 건 아니다. core/Lite/Verified는 로컬 Docker 하네스, Multimodal은 sb-cli 클라우드 제출, Pro는 unified scaffold를 강조한다. “SWE-bench ○○%”라는 숫자를 봤을 때, 이 6단계 중 어느 조건이 달랐는지 모르면 숫자 비교 자체가 성립하지 않는다.
3. SWE-bench variant는 왜 이렇게 많은가

SWE-bench에는 현재 6가지 주요 variant가 있다. 단순 “난이도 조정”이 아니라 각각이 서로 다른 과제를 해결하기 위해 설계된 별개의 시험이다.
Lite는 비용과 속도 문제를 풀었고, Verified는 태스크 품질 문제를 풀었다. Multimodal은 모달리티 범위를, Multilingual은 언어 범위를 넓혔다. Pro는 오염 내성과 현실성을 강화했다. 대체재가 아니라 각각 다른 병목을 푸는 별개의 시험이다.
variant가 계속 늘어나는 흐름은 “코딩 능력”을 하나의 시험으로 닫을 수 없다는 시장 신호다.
4. SWE-bench Verified는 왜 더 이상 최전선 지표가 아닌가
OpenAI는 1,699개 sample을 93명의 Python 경험 개발자가 검토해서 Verified를 만들었다. 한동안 가장 깨끗한 벤치마크로 널리 쓰였다.
하지만 공개 저장소와 공개 패치를 기반으로 하는 이상, 시간이 지날수록 학습 데이터 혼입 위험이 커진다. OpenAI는 2026년 2월 23일 주석에서 Verified가 “점점 오염되고 있기 때문에(increasingly contaminated)” 최전선 코딩 능력 추적 목적으로는 더 이상 적합하지 않다고 밝혔고, SWE-bench Pro 리포팅을 권했다.
두 질문을 구별해야 한다: “Verified가 좋은 벤치마크였는가?” → 그렇다. “Verified가 지금도 최전선 진보를 보여주는 지표인가?” → 이제는 주의가 필요하다.
5. SWE-bench에서 같은 모델인데 점수가 다른 이유

코딩 에이전트의 실제 품질은 프롬프트 한 줄의 영리함보다 guidance, verification, visibility 하네스에서 더 크게 갈린다. SWE-bench 점수도 마찬가지다. 결과는 “모델 단독 능력”이 아니라 “모델 + scaffold + 평가 환경” 시스템 전체의 산물이다.
Verified 리더보드는 “전체 에이전트(all agents)”와 “bash-only 미니 에이전트(mini-SWE-agent)”를 분리해서 표시한다. 이 구조 자체가 이미 model score와 system score를 같은 숫자로 읽으면 안 된다는 공식 메시지다.
“Claude Code가 ○○%”, “Codex가 ○○%”라는 비교는, 모델의 우열을 보는 것 같지만 scaffold 설계 차이를 포함하고 있을 수 있다. 벤치마크 표를 볼 때 먼저 확인할 것: 이건 common scaffold 비교인가, all-agent 리더보드인가?
6. SWE-bench의 신뢰성은 왜 아직 완전하지 않은가
SWE-bench는 Docker 하네스, 표준화된 경로, sb-cli 같은 장치를 통해 재현성을 높이고 있다. 하지만 하네스가 있다는 것이 “평가 신뢰성은 해결 완료”와 같은 뜻은 아니다.
공식 issue tracker에서 확인된 운영 문제:
- 거짓 음성 — gold patch가 로그상 통과인데 최종 report에서는 실패 처리 (공식 issue #447)
- 환경 불일치 — 로컬과 Modal 클라우드에서 결과가 다름 (공식 issue #447)
- 저장소 상태 누수 —
git log --all로 미래 커밋에 접근 가능 (공식 issue #465) - 메타데이터 버그 — FAIL_TO_PASS / PASS_TO_PASS 칼럼 불일치
이 issue들이 리더보드 전체를 무효화하지는 않는다. 하지만 “Docker 하네스가 있다”가 “재현성 문제는 해결됐다”와 같은 문장이 아니라는 점을 보여준다. 벤치마크는 데이터셋뿐 아니라 실행 스택까지 함께 읽어야 한다.
7. SWE-bench 점수를 읽을 때의 7가지 확인 축
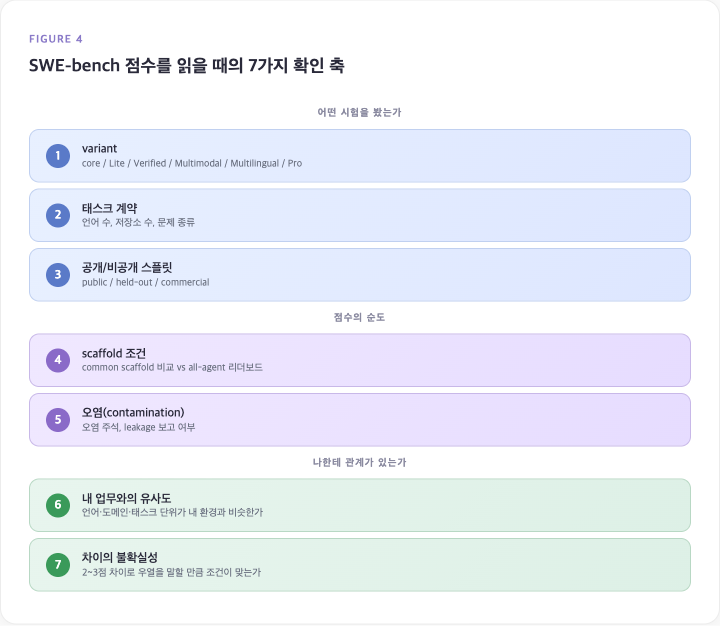
축 1~3 “어떤 시험을 봤는가”: variant, 태스크 계약, 공개/비공개 스플릿을 확인한다. variant가 다르면 묻는 능력이 다르다.
축 4~5 “점수의 순도”: scaffold 조건과 오염(contamination) 여부를 확인한다. scaffold가 다르면 같은 모델도 다른 결과가 나온다.
축 6~7 “나한테 관계가 있는가”: 내 업무와의 유사도, 차이의 불확실성을 확인한다. Python 버그 수정 벤치마크에서 고득점이어도, TypeScript 프론트엔드 개발에서의 실력은 별도의 질문이다.
한국 개발자라면 이 마지막 축이 특히 중요하다. 해외 모델 발표를 읽을 때 “몇 점 올랐나”보다 “이게 내 실제 개발 환경과 얼마나 닮았나”를 먼저 볼 필요가 있다.
8. 그러면 SWE-bench는 쓸모없는 건가?
아니다. SWE-bench 패밀리는 실제 저장소·issue·패치·숨겨진 테스트를 사용한다는 점에서 단순 코드 보완 벤치마크보다 훨씬 풍부하다. 문제는 숫자 자체가 아니라 숫자의 읽기 방식에 있다.
흔한 과대 해석 4가지:
- “점수 = 범용 코딩 능력” — 태스크 분포가 Python 중심이고 scaffold 효과가 섞여 있다
- “Verified가 아직도 최전선 지표” — OpenAI 스스로가 오염 문제를 지적했다
- “2점 차이 = 확실한 능력 차이” — variant·scaffold·실행 정책이 맞지 않으면 비교 불가
- “Docker 하네스 있음 = 신뢰성 해결됨” — 공식 issue에 거짓 음성·leakage 문제가 현존한다
이 글의 한계: methodology reading guide이지 first-party 재현 보고서가 아니다. 벤치마크 점수는 여전히 유용하며, 조건을 확인하고 읽으면 더 정확해진다는 뜻이다.
실무자 플로우: SWE-bench 기사를 읽을 때
- 헤드라인 숫자에 바로 반응하지 않는다. 먼저 variant 이름을 확인한다
- scaffold 정보를 찾는다. “이 점수는 어떤 에이전트 시스템으로 냈는가”가 적혀 있는지
- 오염 주석을 확인한다. Verified 숫자를 최전선 지표로 쓰고 있지 않은지
- 평가 경로를 확인한다. 로컬 Docker인지, 클라우드 제출인지, held-out 스플릿인지
- 내 개발 환경과의 거리를 재본다
- 2~3점 차이로 결론을 내리는 기사는 의심한다
FAQ
Q. SWE-bench에서 점수가 높은 모델을 고르면 무조건 맞나?
점수는 참고가 되지만 그것만으로 “무조건 맞다”고는 할 수 없다. variant, scaffold, 내 개발 환경과의 유사도를 확인한 뒤 판단해야 한다.
Q. SWE-bench Verified 점수는 이제 안 봐도 되나?
안 봐도 된다는 뜻은 아니다. Verified는 벤치마크 설계의 역사적 교훈으로 여전히 가치가 있다. 다만 최전선 능력 지표로는 OpenAI 자신이 오염을 이유로 주의를 당부했다.
Q. SWE-bench Pro가 지금의 정답인가?
Pro는 오염 내성, 4개 언어, 장기 태스크, 산업 지향 현실성을 강화한 방향에 있다. “유일한 정답”이 아니라 “2026년 읽기법의 방향성”으로 보는 게 적절하다.
Q. 결국 코딩 AI를 고를 때는 뭘 봐야 하나?
벤치마크 + 다음 3가지를 함께 본다: (1) 내 환경에 가까운 variant의 점수, (2) common scaffold 비교인지 all-agent 비교인지, (3) 실제로 내 저장소에서 작은 태스크를 돌려본 결과.
이 글에서 사용한 주요 정보 소스
- SWE-bench 공식 (Princeton NLP) — 벤치마크 정의, datasets guide, harness docs
- SWE-bench Verified 공식 리더보드 — all-agent / bash-only 분리 표시, 93명 검증 프로세스
- SWE-bench Multimodal 공식 paper + GitHub — 17개 JS 라이브러리, private test, sb-cli
- SWE-bench Multilingual 공식 page — 9개 언어, 42개 저장소, 300 태스크
- OpenAI 2026-02-23 contamination note — Verified의 오염 문제 공식 견해, Pro 리포팅 권고
- GPT-5.2 릴리스 노트 — SWE-Bench Pro 공식 컨텍스트
- SWE-bench 공식 issue tracker — #447(거짓 음성), #465(repo 상태 누수)
시리즈 예고
이 글은 벤치마크 독해의 출발점이다. 다음 글에서는 “같은 모델 / 다른 scaffold” 문제, 코딩 에이전트 평가와 실무 품질의 차이, 그리고 실제 현업에서 벤치마크를 어떻게 참고하는지를 더 깊이 다룬다.
매주 월요일 뉴스레터
이 글을 읽고 떠오를 수 있는 다음 질문:
- 벤치마크 숫자를 볼 때 내가 가장 자주 놓치는 축은 무엇인가?
- same model / different scaffold 차이는 실제 업무에서 얼마나 큰가?
- 공용 벤치마크와 사내 코드 현실 사이의 간격을 어떻게 메워야 하는가?
매주 월요일 뉴스레터에서 이런 질문을 이어갑니다.
shuntailor.net은 AI 도구 사용법뿐 아니라 벤치마크 읽기법과 AI 개발 구조까지 파고들어 해설하는 AI 전문 기술 블로그입니다.